Definindo SLOs de armazenamento: o custo oculto da latência versus disponibilidade

99,999% de uptime não garante performance. Descubra como definir SLOs de latência em storage para evitar prejuízos financeiros e multas contratuais.
A disponibilidade de um sistema de armazenamento é, historicamente, a métrica mais superestimada em contratos de TI. Como Gerente de Nível de Serviço, afirmo categoricamente: um storage array que responde ao ping mas leva 500ms para completar uma operação de escrita não está "disponível". Ele está funcionalmente morto. No entanto, a maioria dos contratos de SLA (Service Level Agreement) padrão ignora essa nuance, protegendo o provedor de serviços enquanto a operação do cliente sangra dinheiro devido à latência excessiva.
Resumo em 30 segundos
- Disponibilidade ≠ Usabilidade: Um storage com 100% de uptime pode causar paradas operacionais se a latência de disco exceder os timeouts da aplicação (I/O Wait).
- A armadilha da média: Métricas de latência média mascaram picos críticos. Contratos robustos devem exigir garantias baseadas em percentis (P99 ou P99.9).
- Penalidades por Performance: O SLA moderno deve incluir cláusulas de crédito financeiro não apenas por queda de serviço, mas por degradação de IOPS e throughput abaixo do limite contratado.
O impacto financeiro da latência em transações críticas
No universo de armazenamento corporativo, tempo é literalmente dinheiro. Em ambientes de High Frequency Trading (HFT) ou bancos de dados transacionais massivos (OLTP), a diferença entre um disco NVMe respondendo em 100 microssegundos e um SSD SATA respondendo em 2 milissegundos pode significar a perda de uma janela de oportunidade de mercado.
Quando definimos um SLO (Service Level Objective) para armazenamento, não estamos apenas discutindo especificações técnicas de hardware; estamos definindo o limiar de dor financeira da organização. Uma latência de escrita elevada em um log de banco de dados (REDO log) trava toda a transação. O servidor de aplicação fica ocioso, aguardando o commit do disco. Esse estado, conhecido como I/O Wait, é um custo oculto: você paga por CPU e RAM que não podem ser usados porque o subsistema de armazenamento é o gargalo.
💡 Dica Pro: Ao auditar seus sistemas de armazenamento, verifique a métrica de Queue Depth (Profundidade de Fila). Se a fila de comandos pendentes para o disco estiver consistentemente alta, sua latência aumentará exponencialmente. O SLO deve limitar não apenas o tempo de resposta, mas a profundidade de fila aceitável antes de considerar uma violação de serviço.
A falácia dos cinco noves e o "Zombie Storage"
O padrão da indústria persegue os "cinco noves" (99,999% de disponibilidade), o que permite cerca de 5 minutos de inatividade por ano. Contudo, essa métrica é binária: ou está ligado, ou está desligado. Ela falha em capturar o estado de "Zombie Storage" — onde o array de discos está acessível via rede, os controladores estão online, mas a performance degradou a tal ponto que as aplicações conectadas entram em timeout.
Para um contrato de nível de serviço eficaz, a definição de "Indisponibilidade" deve ser reescrita. Uma cláusula moderna de SLA deve declarar: "O serviço será considerado indisponível se a latência de leitura/escrita exceder X milissegundos por Y minutos consecutivos". Sem essa cláusula, seu fornecedor (ou departamento interno de infraestrutura) pode alegar cumprimento do SLA enquanto seus usuários não conseguem salvar um único arquivo.
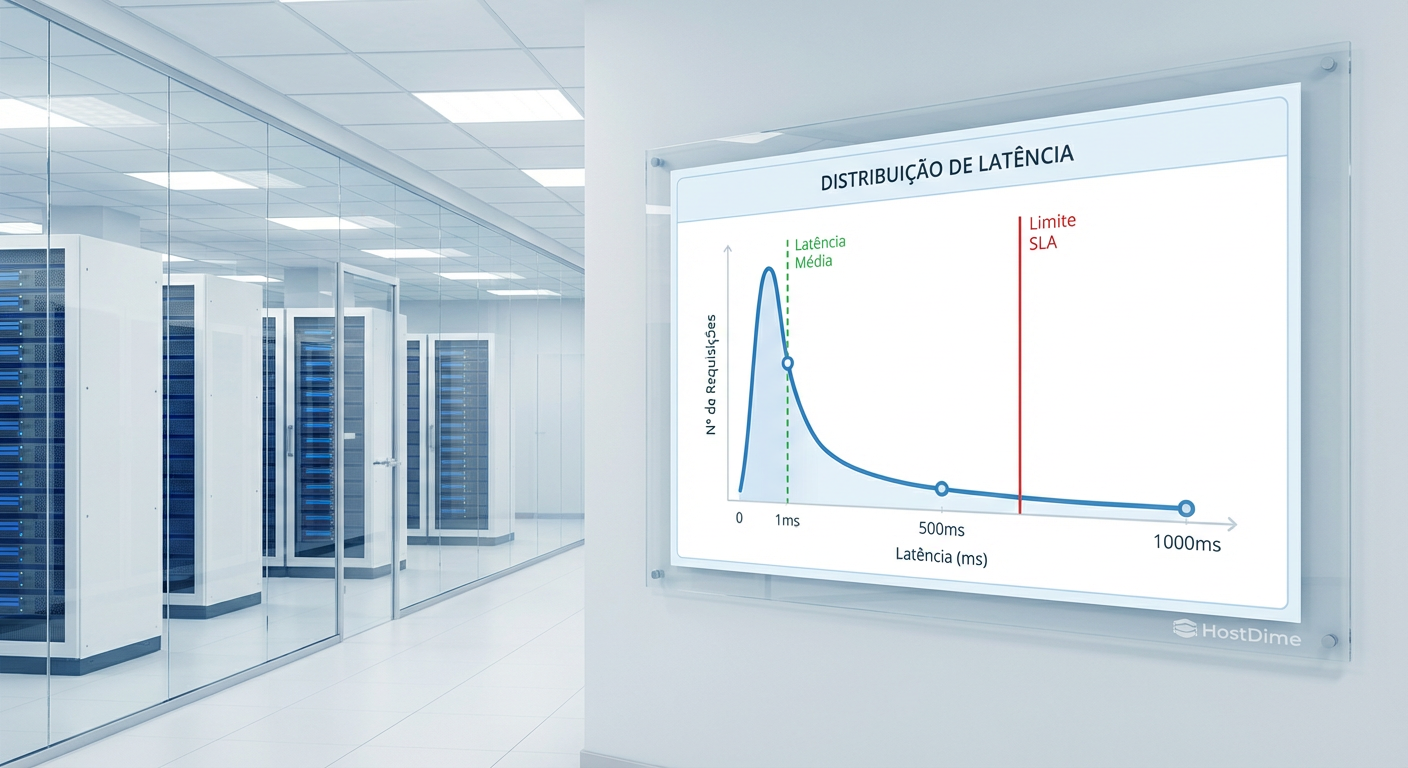 Figura: Gráfico de distribuição de latência demonstrando o perigo da "Latência de Cauda" (Tail Latency). A média (verde) esconde os picos (vermelho) que violam o SLO e causam timeouts na aplicação.
Figura: Gráfico de distribuição de latência demonstrando o perigo da "Latência de Cauda" (Tail Latency). A média (verde) esconde os picos (vermelho) que violam o SLO e causam timeouts na aplicação.
Métricas que importam: Percentis vs. Médias
O maior erro técnico na definição de SLOs de armazenamento é o uso de médias aritméticas. A média é uma ferramenta estatística que dilui a realidade. Se 99 operações de disco levam 1ms e 1 operação leva 10 segundos (devido a uma reconstrução de RAID ou Garbage Collection agressivo em um SSD), a média será de aproximadamente 100ms. Isso parece ruim, mas talvez aceitável. Porém, para o usuário que pegou a operação de 10 segundos, o sistema travou.
Para mitigar isso, exigimos o uso de Percentis:
P50 (Mediana): O desempenho típico.
P99: O desempenho vivenciado por 1% das requisições mais lentas.
P99.9: O pior cenário (latência de cauda).
Um SLO robusto para um All-Flash Array deve estipular: "A latência de leitura não deve exceder 1ms no percentil P99". Isso garante que 99% de todas as transações sejam rápidas, forçando a infraestrutura a lidar com os picos de forma eficiente.
Estruturando Tiers de Armazenamento: Custo por IOPS
Não faz sentido financeiro ou técnico aplicar o mesmo SLO para todos os dados. O gerenciamento de nível de serviço exige a classificação inteligente dos dados em Tiers (camadas), alinhando o custo do hardware à exigência de performance.
Abaixo, apresento uma estrutura de referência para alinhamento de SLOs e penalidades:
| Tier de Armazenamento | Tecnologia Típica | Caso de Uso | SLO de Latência (P99) | Penalidade Sugerida |
|---|---|---|---|---|
| Tier 0 (Mission Critical) | NVMe, Storage Class Memory (SCM) | Bancos de Dados HFT, Logs de Transação, VDI de Alta Performance | < 0.5 ms | 10% da fatura mensal por evento de violação > 10 min. |
| Tier 1 (Business Critical) | SSD Enterprise (SAS/SATA), All-Flash Arrays | Aplicações ERP, CRMs, Virtualização Geral | < 5 ms | 5% da fatura mensal por evento de violação > 30 min. |
| Tier 2 (General Purpose) | HDD 10k/15k RPM ou SSD QLC | File Servers, Repositórios de Código, Backups Recentes | < 20 ms | Crédito de serviço proporcional ao tempo excedido. |
| Tier 3 (Archive/Cold) | HDD NL-SAS (7.2k RPM), Object Storage, Fita | Backups de Longa Retenção, Logs de Auditoria, Cold Data | N/A (Foco em Throughput) | Sem penalidade de latência, apenas integridade de dados. |
⚠️ Perigo: Cuidado com o "Tiering Automático" mal configurado. Se o algoritmo mover dados quentes para discos lentos (Tier 2) durante o horário comercial, você terá uma violação de SLO causada pela própria inteligência do storage. O contrato deve especificar que a performance garantida se aplica ao dado onde ele estiver residindo no momento do acesso.
Cálculo de penalidades e garantias de Throughput
Além da latência (tempo de resposta), o Throughput (vazão de dados, geralmente em MB/s ou GB/s) é crítico para operações de backup e restore. Um SLO de recuperação de desastres (Disaster Recovery) é inútil se o storage de backup não conseguir entregar os dados rápido o suficiente para cumprir o RTO (Recovery Time Objective).
Para calcular penalidades baseadas em throughput, a fórmula deve considerar a degradação percentual. Exemplo de cláusula: "Se a taxa de transferência sustentada cair abaixo de 500 MB/s durante a janela de backup (22h - 02h), será aplicado um crédito de 2% sobre a mensalidade para cada ocorrência."
Isso força o provedor a não fazer oversubscription (venda excessiva) de largura de banda no back-end do storage ou na rede SAN (Storage Area Network). Em ambientes de Home Lab ou Small Business usando NAS (como TrueNAS ou Synology), isso se traduz em garantir que tarefas de scrubbing (verificação de integridade ZFS) ou reconstrução de RAID não saturem o barramento a ponto de impedir o fluxo de dados regular.
Veredito Técnico
A era de aceitar "o sistema está lento" como uma fatalidade acabou. Como gestores de infraestrutura e nível de serviço, devemos tratar a latência como um defeito de fabricação do serviço. Ao desenhar seus próximos contratos ou acordos internos de operação:
Elimine a palavra "Média" dos indicadores de performance.
Vincule a latência à disponibilidade: Se é lento demais para usar, está indisponível.
Segmente os riscos: Não pague preço de NVMe para guardar PDF antigo, mas não aceite performance de HDD para rodar seu banco de dados principal.
A garantia contratual é a única linguagem que fornecedores e hardware entendem. Se não estiver escrito, não existe.
FAQ: Perguntas Frequentes sobre SLOs de Storage
Qual a diferença entre SLA e SLO em contratos de storage?
O SLA (Service Level Agreement) é o contrato externo, jurídico e comercial, que define as penalidades financeiras e responsabilidades. O SLO (Service Level Objective) é a meta técnica específica (ex: latência de escrita < 1ms no percentil 99) que a equipe de engenharia deve atingir para garantir que o SLA não seja violado. O SLO é o alvo; o SLA é a consequência de errar o alvo.Por que a disponibilidade (uptime) não garante performance?
Um servidor ou storage pode estar tecnicamente "disponível" (respondendo ao protocolo ICMP/Ping e com portas de serviço abertas), mas se os discos estiverem saturados ou travados em I/O Wait, qualquer tentativa de leitura ou escrita falhará por timeout. Para a aplicação e o usuário final, o sistema está inoperante, embora o dashboard de monitoramento mostre "luz verde" baseada apenas em conectividade.Como medir latência de forma contratual?
A medição deve ser feita através de percentis (P90, P95, P99) e não por médias simples. Além disso, é crucial definir o ponto de medição: a latência deve ser medida na porta do iniciador (servidor) ou na porta do alvo (storage)? A medição no servidor (iniciador) é mais realista para o negócio, pois inclui a latência da rede SAN/LAN, que também faz parte da entrega do serviço de armazenamento.
Arthur Sales
Gerente de Nível de Serviço
"Vivo na linha tênue entre a conformidade e a violação contratual. Para mim, 99,9% não é disponibilidade; é prejuízo. Exijo garantias absolutas e aplicação rigorosa de penalidades."