Diagnosticando degradação de link PCIe e erros AER no Linux

Aprenda a investigar gargalos de I/O, quedas de velocidade em NVMe e erros de barramento usando lspci, dmesg e logs AER no Linux.
Você comprou um SSD NVMe Gen4 de ponta, instalou no servidor, mas o fio reporta metade da largura de banda esperada e a latência de cauda (p99) está errática. O sistema operacional não travou, o disco não reporta falha no SMART, mas algo está fundamentalmente errado. Bem-vindo ao submundo da camada física: onde a poeira, cabos riser de má qualidade e negociações de energia falhas destroem a performance do seu storage.
O barramento PCIe (Peripheral Component Interconnect Express) é a espinha dorsal de qualquer infraestrutura de armazenamento moderna. Quando ele falha silenciosamente, ele não para de funcionar; ele degrada. Um link x16 pode cair para x8, ou x4 para x1. A velocidade de 16 GT/s (Gen4) pode recuar para 8 GT/s (Gen3) para manter a estabilidade. O Linux sabe disso, e com as ferramentas certas, você também saberá.
Resumo em 30 segundos
- O Sintoma: Performance de disco abaixo do esperado sem erros de I/O explícitos geralmente indica que o link PCIe negociou uma velocidade ou largura de banda inferior (ex: rodando em x1 em vez de x4).
- A Ferramenta: O
lspcié seu melhor amigo. Compare sempreLnkCap(Capacidade do Hardware) comLnkSta(Status Atual) para identificar degradação física.- O Vilão Oculto: O ASPM (Active State Power Management) economiza energia, mas pode causar latência alta e erros de link em SSDs NVMe de alta performance. Desativá-lo é frequentemente o primeiro passo no troubleshooting.
O detetive do barramento: por que seu NVMe x4 está rodando em x1
A primeira etapa de qualquer diagnóstico de storage não é olhar o sistema de arquivos, é olhar o hardware. O comando lspci (parte do pacote pciutils) é a janela para os registradores de configuração dos dispositivos PCIe.
Para auditar seus discos, você precisa de privilégios de root (para ler a configuração estendida) e verbosidade.
sudo lspci -vv | grep -A 20 "Non-Volatile memory"
O output é denso. O que você procura são duas linhas específicas dentro da seção do seu dispositivo NVMe: LnkCap e LnkSta.
LnkCap (Link Capabilities): O que o dispositivo e o slot conseguem fazer.
LnkSta (Link Status): O que eles estão efetivamente fazendo agora.
Veja este exemplo de um cenário degradado:
LnkCap: Port #0, Speed 16GT/s, Width x4, ASPM L1, Exit Latency L1 <64us
LnkSta: Speed 8GT/s (downgraded), Width x1 (downgraded), TrErr- Train- SlotClk+ DLActive-
💡 Dica Pro: Se você vir
(downgraded)ou se aWidthno Status for menor que na Capacidade, você tem um problema físico. Pode ser sujeira no slot, um SSD mal encaixado ou, muito comumente em servidores 1U/2U, um cabo riser PCIe defeituoso.
A negociação do link PCIe acontece na inicialização (Link Training). Se o controlador detectar ruído excessivo ou perda de sinal em algumas trilhas (lanes), ele desativa essas trilhas e tenta operar com o que sobra. O resultado é um SSD funcionando a 25% da capacidade sem gerar um único log de erro de sistema de arquivos.
 Figura: Diagrama ilustrando o processo de degradação de link: interferência física força o controlador a desativar trilhas (lanes), reduzindo a largura de banda efetiva.
Figura: Diagrama ilustrando o processo de degradação de link: interferência física força o controlador a desativar trilhas (lanes), reduzindo a largura de banda efetiva.
Interpretando logs do Advanced Error Reporting (AER)
Quando o hardware PCIe detecta problemas, ele usa o mecanismo AER (Advanced Error Reporting) para notificar o kernel. O Linux, por sua vez, joga isso no ring buffer. Se o seu dmesg está sendo inundado, seu hardware está gritando por socorro.
Use o dmesg ou journalctl para filtrar esses eventos:
sudo dmesg | grep -i "AER"
Você encontrará dois tipos principais de erros. A distinção entre eles é vital para a saúde dos seus dados.
1. Correctable Errors (Erros Corrigíveis)
pcieport 0000:00:1c.0: AER: Correctable error received: 0000:00:1c.0
pcieport 0000:00:1c.0: AER: [ 0] RxErr (Receiver Error)
Isso significa que o pacote de dados chegou corrompido, o hardware detectou e solicitou uma retransmissão (Replay).
Impacto: O dado está íntegro, mas a latência aumenta drasticamente. Se o link precisa retransmitir 10% dos pacotes, seu throughput cai e a latência de cauda explode.
Causa: Geralmente integridade de sinal (cabos ruins, interferência eletromagnética).
2. Uncorrectable Errors (Erros Não Corrigíveis)
Estes são divididos em "Non-Fatal" e "Fatal".
Non-Fatal: O hardware não conseguiu corrigir, mas a transação específica pode ser descartada sem derrubar o sistema.
Fatal: O link caiu completamente. O kernel geralmente reseta o dispositivo ou entra em kernel panic para evitar corrupção de dados no disco.
⚠️ Perigo: Ignorar "Correctable Errors" é um erro de novato. Eles são o canário na mina. Um volume alto de erros corrigíveis é o prenúncio de uma falha fatal ou de corrupção silenciosa caso o mecanismo de correção falhe estatisticamente.
Ajustando políticas de ASPM para estabilizar links
O ASPM (Active State Power Management) é frequentemente o culpado por instabilidades em SSDs NVMe de alta performance em Linux. O protocolo PCIe permite que o link entre em estados de baixa energia (L0s, L1) quando ocioso.
O problema? Sair do estado L1 leva tempo (latência de saída). Se o seu SSD entra e sai de L1 milhares de vezes por segundo, a latência acumula. Pior: alguns controladores SSD têm bugs de firmware que falham na negociação de retorno do estado L1, causando timeouts e resets do link.
Para servidores de storage e workstations de alta performance, a economia de alguns watts raramente justifica a instabilidade.
Verificando a política atual
cat /sys/module/pcie_aspm/parameters/policy
A saída mostrará a política ativa entre colchetes, ex: [default] performance powersave.
Tabela Comparativa: Políticas de ASPM
| Política | Comportamento | Impacto no Storage | Recomendação |
|---|---|---|---|
| default | Segue o que a BIOS/Firmware configurou. | Imprevisível. Depende da qualidade da BIOS do fabricante da placa-mãe. | Uso geral. |
| powersave | Agressivo. Tenta reduzir a velocidade do link e desligar lanes sempre que possível. | Alto risco de latência e desconexões em NVMe sob carga. | Apenas para laptops na bateria. |
| performance | Desabilita ASPM. Mantém o link em estado L0 (ativo) permanentemente. | Máxima estabilidade e menor latência. Maior consumo elétrico. | Obrigatório para servidores de storage/ZFS. |
Para alterar em tempo de execução (cuidado, pode causar instabilidade momentânea):
echo performance | sudo tee /sys/module/pcie_aspm/parameters/policy
Monitoramento contínuo com watch e sysfs
O lspci é uma foto instantânea. Para diagnosticar problemas intermitentes, você precisa de um filme. O kernel expõe contadores de erro diretamente no sistema de arquivos sysfs.
Localize o endereço do seu dispositivo (ex: 0000:01:00.0) e monitore os contadores de erro corrigível em tempo real. Isso é extremamente útil enquanto você executa um teste de carga com fio para ver se o estresse provoca erros.
# Encontre o caminho do dispositivo no sysfs
cd /sys/bus/pci/devices/0000:01:00.0/aer_dev_correctable/
# Monitore os contadores
watch -n 1 "grep . *"
Se você ver o contador rx_err ou bad_tlp subindo enquanto o disco está sob carga, você confirmou um problema físico. Nenhum ajuste de software (driver, scheduler de I/O) resolverá isso. Você precisa trocar o cabo, o slot ou o disco.
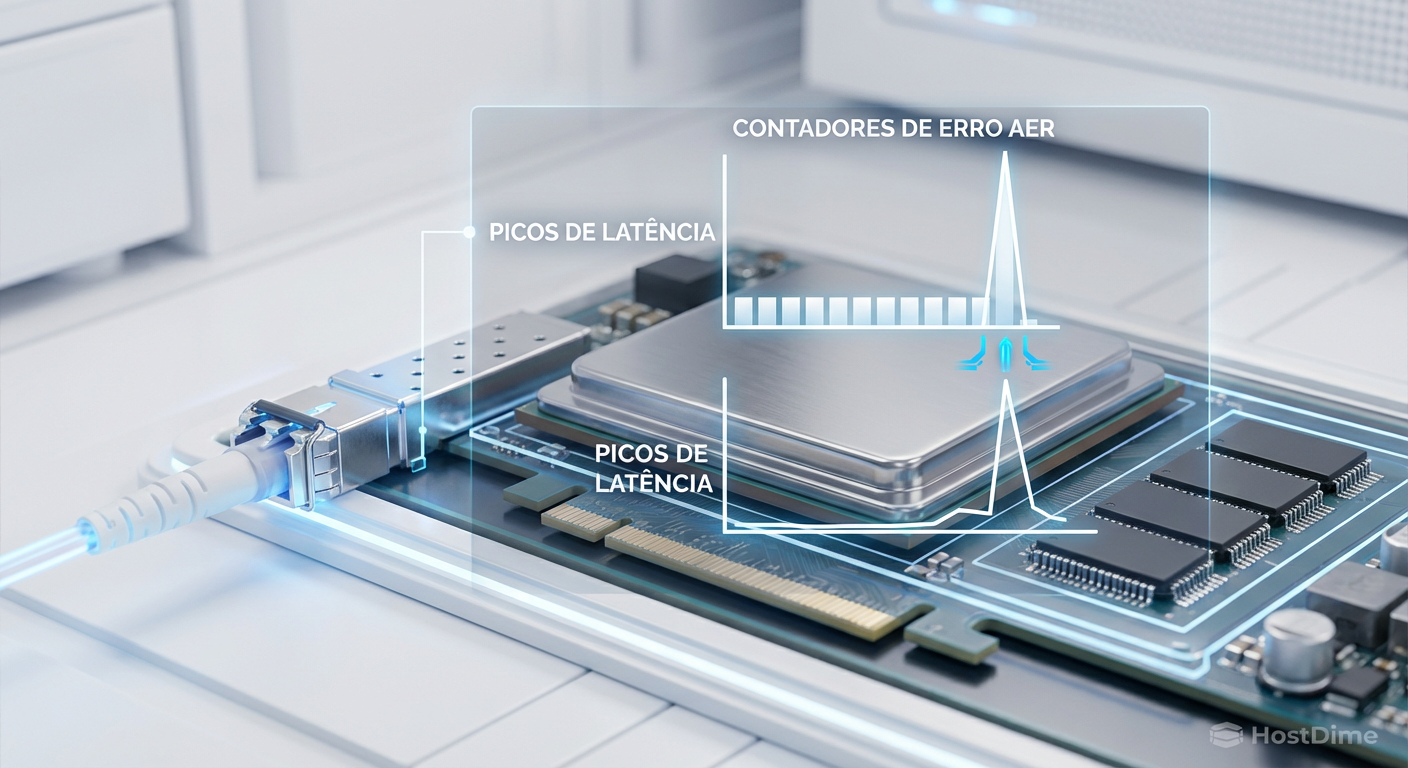 Figura: Visualização de monitoramento em tempo real: correlação entre contadores de erro AER no terminal e picos de latência.
Figura: Visualização de monitoramento em tempo real: correlação entre contadores de erro AER no terminal e picos de latência.
Quando o hardware mente: parâmetros de boot
Às vezes, a BIOS reporta incorretamente as capacidades do link ou o suporte a ASPM, confundindo o kernel. Em cenários de storage crítico, podemos forçar o comportamento do kernel via parâmetros do GRUB.
Edite /etc/default/grub e adicione à linha GRUB_CMDLINE_LINUX_DEFAULT:
pcie_aspm=off: A marreta. Desabilita completamente o ASPM no nível do kernel, ignorando o que a BIOS diz. Essencial para estabilidade de arrays NVMe.pci=nommconf: Em algumas plataformas antigas ou com implementações ACPI bugadas, o acesso ao espaço de configuração PCIe via MMCONFIG falha. Isso reverte para métodos de acesso mais antigos e estáveis.pci=noaer: Use com extrema cautela. Isso diz ao kernel para ignorar e não logar erros AER. Isso não conserta o erro, apenas silencia o log. Útil apenas se um dispositivo está enviando tantos erros corrigíveis que o log do sistema está enchendo o disco de boot (sim, isso acontece), e você precisa de tempo para planejar a troca do hardware.
Após editar, não esqueça de rodar sudo update-grub (ou equivalente na sua distro) e reiniciar.
O veredito do link
Diagnosticar problemas de PCIe exige uma mudança de mentalidade: parar de culpar o software e começar a desconfiar da física. Se o lspci mostra degradação de largura de banda ou o dmesg mostra erros AER, não perca tempo ajustando sistemas de arquivos ou schedulers.
A tendência para a próxima geração de datacenters, com a chegada do PCIe 5.0 e 6.0, é que a integridade de sinal se torne ainda mais crítica. As tolerâncias elétricas são minúsculas. Um grão de poeira ou uma curva muito acentuada no cabo riser que funcionava no Gen3 será catastrófico no Gen5. Adote a verificação do LnkSta e dos contadores AER como parte padrão do seu checklist de provisionamento de servidores. Se o link não está sólido, seus dados estão andando na corda bamba.
FAQ: Perguntas Frequentes
O que significa 'Correctable Error' nos logs do PCIe?
Significa que o hardware detectou um problema na transmissão (como um bit flip ou ruído) e conseguiu corrigi-lo via retransmissão sem perda de dados. Embora os dados estejam seguros, uma alta frequência desses erros indica degradação física iminente e causa latência alta (lag) no acesso ao disco.Como verificar se meu SSD está usando todas as pistas (lanes) PCIe disponíveis?
Use o comandosudo lspci -vv, encontre seu dispositivo NVMe e compare os campos LnkCap (Capacidade do Hardware) com LnkSta (Status Atual). Se o LnkCap diz "Width x4" e o LnkSta diz "Width x1" ou "Width x2", seu SSD está rodando com performance degradada.
O ASPM pode causar lentidão em discos NVMe?
Sim. O Active State Power Management tenta economizar energia colocando o link PCIe em repouso (L1) quando ocioso. Em discos de alta performance, a latência para "acordar" o link (wake-up latency) pode causar engasgos, timeouts e até desconexões se o firmware do SSD não lidar bem com as transições de estado.O que fazer se o lspci mostrar "downgraded"?
Primeiro, verifique o contato físico. Remova e reinsira o SSD ou a placa. Limpe os contatos do slot com ar comprimido. Se usar cabos riser (comuns em gabinetes verticais ou servidores), teste sem o cabo. Se o problema persistir, teste o SSD em outro slot para descartar falha na placa-mãe ou na CPU.
Alexandre Tavares
Operador de Storage em Rede (SAN/NAS)
"Respiro Fibre Channel e NVMe-oF. Meu foco é eliminar gargalos de I/O e otimizar rotas multipath para garantir que seus dados trafeguem com a menor latência possível."