Diagnóstico Forense de Hardware: Diferenciando Bit Flips, Falhas de RAM e Cabos Defeituosos
Investigação cirúrgica de falhas silenciosas. Aprenda a isolar erros de ECC RAM, corrupção de firmware e CRC de cabos usando logs e traces de baixo nível.
Na engenharia de sistemas, a "esperança" não é uma estratégia e "reiniciar" não é uma solução; é uma destruição de evidências. Quando um servidor falha, o sintoma é apenas o eco de um evento catastrófico que ocorreu em nanossegundos no nível do silício. Como investigadores forenses, nossa obrigação não é apenas restaurar o serviço, mas dissecar o cadáver digital para entender se fomos vítimas de um raio cósmico aleatório (Soft Error), de um transistor degradado (Hard Error) ou de uma falha na integridade do sinal em um cabo SATA de cinco reais.
Este artigo detalha a metodologia cirúrgica para diferenciar falhas de memória volátil, corrupção de dados em trânsito e degradação física de interconexões.
Sintomas Observados: O Início da Anomalia Silenciosa
O incidente raramente começa com uma explosão. Ele começa com um sussurro nos registros que a maioria dos administradores ignora. A anomalia silenciosa se manifesta através de comportamentos erráticos que desafiam a lógica da aplicação.
Em um cenário forense típico de alta complexidade, os sintomas iniciais que disparam o alerta vermelho incluem:
Segfaults Não Determinísticos: Aplicações estáveis (como NGINX ou PostgreSQL) falhando com
SIGSEGV(Segmentation Fault) ouSIGBUSem endereços de memória variáveis. Se o endereço da falha muda a cada reinício, o código provavelmente está inocente; o hardware é o culpado.Corrupção de Filesystem em Repouso: O
fsckou o scrub do ZFS reporta checksum mismatches em blocos que foram gravados corretamente dias atrás.Kernel Panics Crípticos: Telas de erro ou dumps de console apontando para "General Protection Fault" ou exceções de página em ring 0, frequentemente associadas a drivers de armazenamento ou subsistemas de gerenciamento de memória.
A distinção crucial aqui é a consistência. O software tende a falhar de forma previsível (mesma entrada, mesmo erro). O hardware falha de forma estatística ou ambiental (dependendo de temperatura, vibração ou carga elétrica).
Timeline do Incidente: Reconstruindo a Cronologia da Falha
Para isolar a causa raiz, precisamos congelar a cena do crime e alinhar os eventos em uma linha do tempo de precisão de microssegundos. A correlação entre carga de trabalho, temperatura e erros é fundamental.
Abaixo, apresentamos a árvore de decisão inicial que guia nossa cronologia.
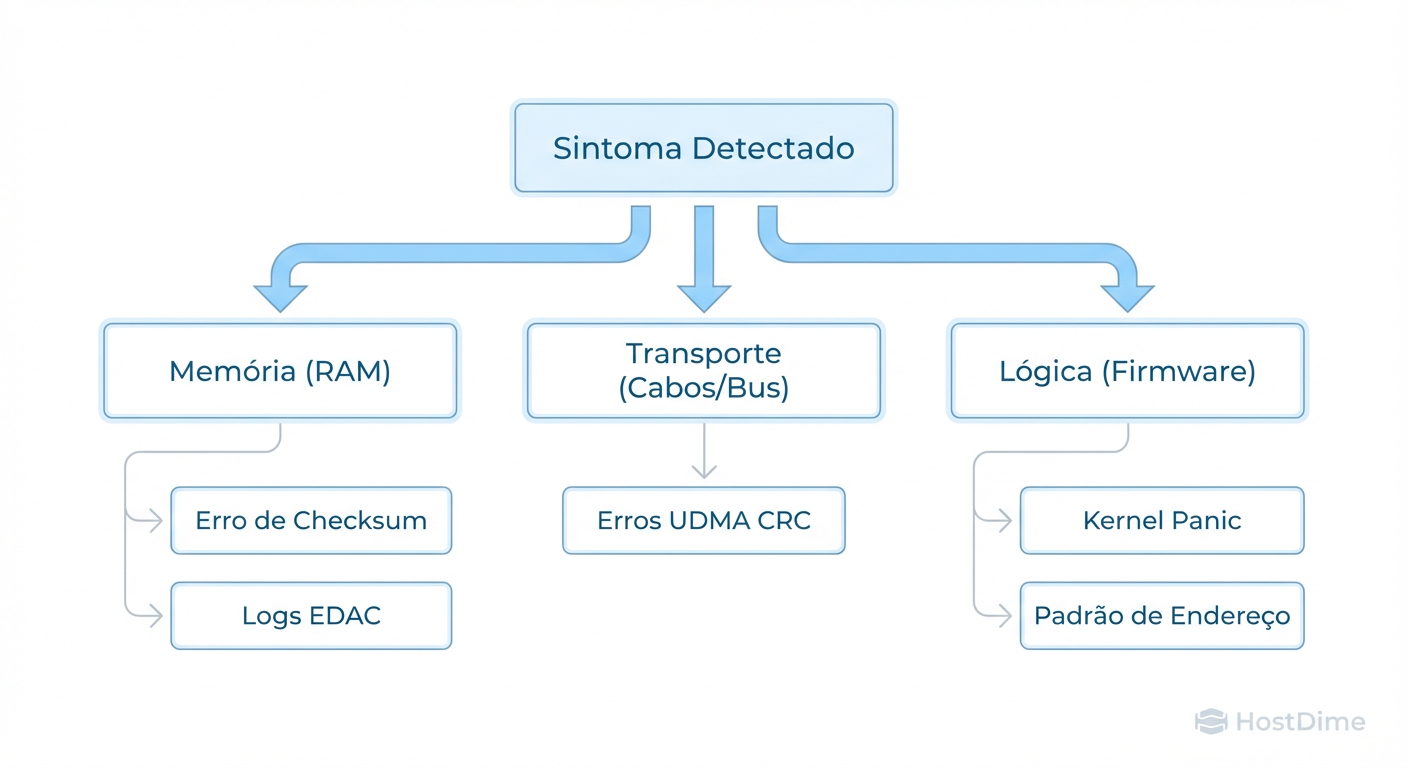 Figura: Fig. 1: Árvore de Decisão Forense para isolamento de falhas de hardware.
Figura: Fig. 1: Árvore de Decisão Forense para isolamento de falhas de hardware.
Fase 1: O Evento Sentinela (T-minus 72h)
Muitas vezes, o kernel Linux tenta nos avisar. Observamos, retrospectivamente, entradas no dmesg sobre "Corrected Errors" (CE). Estes são eventos onde o ECC (Error Correction Code) da RAM ou os mecanismos de retry do protocolo SATA/SAS intervieram com sucesso. O sistema não caiu, mas sangrou.
Fase 2: A Degradação (T-minus 24h)
A frequência dos erros corrigíveis aumenta. O contador UDMA_CRC_Error_Count nos atributos SMART dos discos começa a subir incrementalmente. O sistema operacional começa a gastar ciclos de CPU apenas lidando com retransmissões de pacotes SCSI ou correções de memória. A latência sobe, o throughput cai.
Fase 3: O Ponto de Ruptura (T-0) Um erro não corrigível (UE - Uncorrectable Error) ocorre.
Cenário RAM: Um bit flip duplo ocorre em uma palavra de memória protegida por ECC padrão. O controlador de memória envia um sinal de Machine Check Exception (MCE) para a CPU. O kernel entra em pânico imediatamente para proteger a integridade dos dados.
Cenário Cabo/Disco: O link SATA cai após múltiplas tentativas falhas de negociação. O filesystem é remontado como Read-Only (RO) para evitar corrupção adicional.
Análise de Logs e Traces: Isolando o Subsistema (RAM vs. I/O)
A análise forense exige que mergulhemos nos logs brutos. Não procure por "erro"; procure por assinaturas específicas de subsistemas. A primeira tarefa é separar o que é computação (CPU/RAM) do que é I/O (Disco/Cabo).
Identificando Assinaturas de Falha de Memória
O subsistema EDAC (Error Detection and Correction) do Linux é nossa principal fonte de verdade.
# Comando forense primário para erros de hardware
grep -i "hardware error" /var/log/mcelog
# Ou utilizando journalctl para kernels modernos
journalctl -k | grep -E "EDAC|MCE|Hardware Error"
Uma saída típica de falha de RAM se parece com isto:
[Hardware Error]: CPU 0: Machine Check Exception: 5 Bank 4: be00000000800400[Hardware Error]: RIP !INEXACT! 10:<ffffffff81626d70> {intel_idle+0x100/0x130}
Aqui, "Bank 4" é a pista geográfica. Se os erros se repetem sempre no mesmo banco e linha, temos um módulo físico defeituoso. Se os erros pulam entre bancos aleatoriamente, podemos estar lidando com problemas de tensão na placa-mãe (Vdimm instável) ou superaquecimento.
Identificando Assinaturas de Falha de Transporte (I/O)
Diferente da RAM, erros de cabo e controladora aparecem como falhas de comunicação e timeouts.
dmesg | grep -E "ata|scsi|sata|sas"
Sintomas de Cabo Defeituoso:
ata1: link is slow to respond, please be patient (ready=0)ata1: COMRESET failed (errno=-16)ata1: hard resetting link
Sintomas de Disco/Mídia Defeituosa:
blk_update_request: I/O error, dev sda, sector 2048sd 0:0:0:0: [sda] Unhandled sense code
A tabela abaixo ajuda a diferenciar a origem baseada no log:
| Sintoma no Log | Provável Culpado | Gravidade |
|---|---|---|
Machine Check Exception (MCE) |
RAM / Cache L1-L3 / CPU | Crítica (Panic Imediato) |
EDAC sbridge MC0: HANDLER |
RAM (ECC Corrigiu) | Alerta (Monitorar) |
ataX: SError: { 10B8B } |
Cabo / Porta SATA (Erro de Disparidade) | Alta (Corrupção de Dados em Trânsito) |
Sense Key : Medium Error |
Platter do Disco / Célula SSD | Alta (Perda de Dados em Repouso) |
Para visualizar onde a corrupção ocorre, considere a topologia do dado:
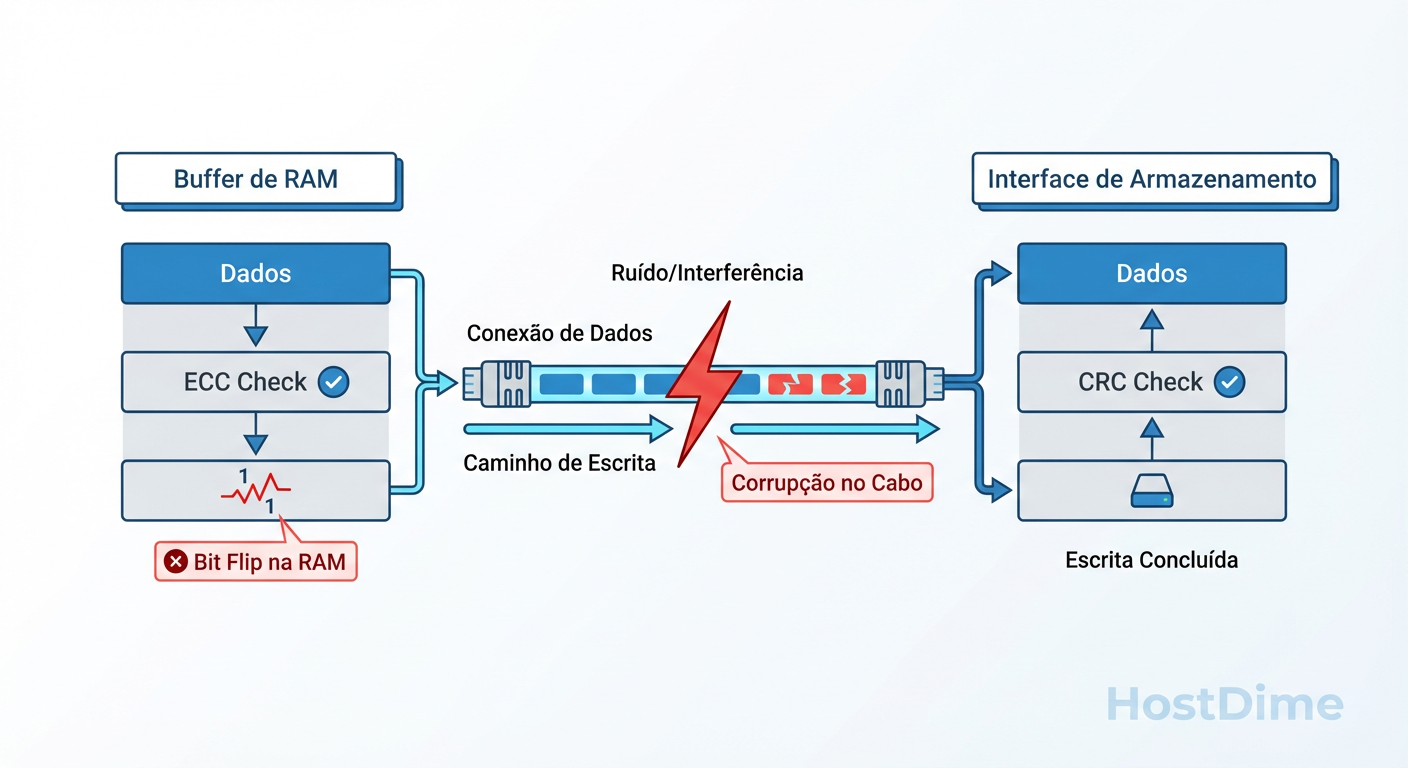 Figura: Fig. 2: Topologia da Corrupção – Diferenciando erros de armazenamento (Data at Rest) de erros de transmissão (Data in Transit).
Figura: Fig. 2: Topologia da Corrupção – Diferenciando erros de armazenamento (Data at Rest) de erros de transmissão (Data in Transit).
Investigação de Memória: Decifrando EDAC e Padrões de Endereçamento
Quando isolamos o problema na memória RAM, a investigação deve descer ao nível do silício. Não basta saber que a "RAM falhou". Precisamos saber como ela falhou.
Bit Flips Aleatórios vs. Stuck Bits
Um Bit Flip (Soft Error) é uma inversão transitória causada por partículas alfa ou raios cósmicos. É um evento de uma vez. Um Stuck Bit (Hard Error) é uma falha física na célula de memória que a mantém presa em 0 ou 1.
Utilizamos ferramentas como edac-util ou rasdaemon para mapear esses erros.
O Teste do Padrão de Endereçamento: Se você plotar os endereços de memória onde os erros ocorrem, verá padrões distintos.
Padrão Disperso: Erros ocorrem em endereços aleatórios ao longo de dias.
- Veredito: Provável interferência cósmica ou instabilidade leve de voltagem.
Padrão Colunar/Linha: Erros se agrupam em endereços que compartilham os mesmos bits de coluna ou linha (ex: endereços terminados em
0x...A000).- Veredito: Falha no chip de memória ou na trilha da placa de circuito impresso do DIMM.
Padrão de Banco: Erros massivos em um único banco lógico.
- Veredito: Controlador de memória ou falha catastrófica do módulo.
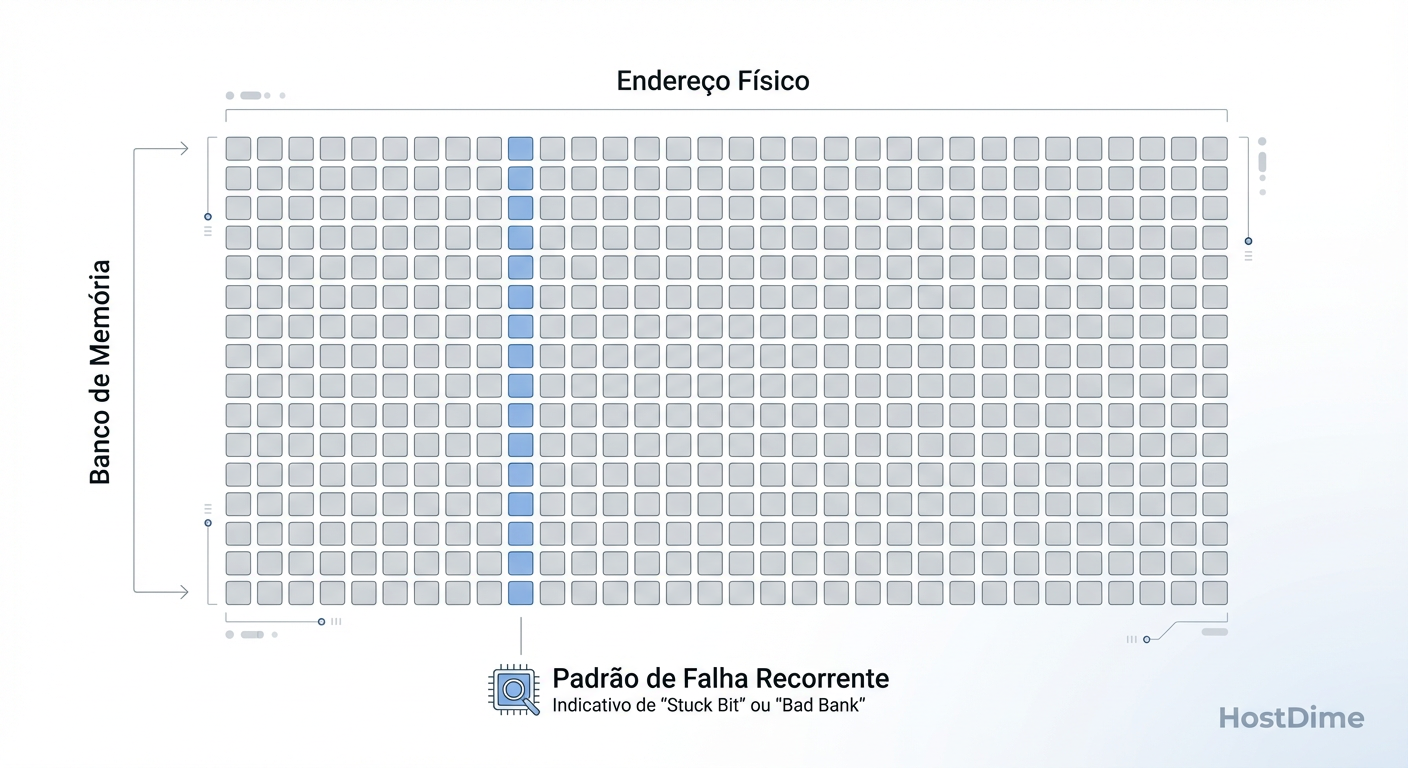 Figura: Fig. 3: Análise de Padrão de Endereçamento – Distinguindo aleatoriedade de falha estrutural no módulo de memória.
Figura: Fig. 3: Análise de Padrão de Endereçamento – Distinguindo aleatoriedade de falha estrutural no módulo de memória.
Rowhammer: O Vilão Moderno
Em arquiteturas DDR3 e DDR4 de alta densidade, o acesso repetido a uma linha de memória pode causar vazamento de carga elétrica para linhas adjacentes, invertendo bits. Se seus logs mostram corrupção de memória correlacionada a picos de carga de trabalho específicos (ex: um loop apertado em um banco de dados), você pode estar diante de um efeito Rowhammer, e não de um defeito de fabricação tradicional.
Investigação de Transporte: Erros CRC, Cabos e Controladoras
A falha mais negligenciada e mais comum em datacenters não é o disco, é o cabo. Cabos SATA e SAS operam com sinalização diferencial de alta frequência. Uma dobra excessiva, oxidação nos contatos ou vibração do chassi pode alterar a impedância do cabo.
Isso resulta em Bit Rot em Trânsito. O dado sai correto da CPU, mas chega corrompido ao disco (ou vice-versa).
A Prova Forense: SMART Attribute 199
O atributo SMART 199 (UDMA_CRC_Error_Count) é o "canário na mina" para cabos ruins.
smartctl -A /dev/sda | grep -i crc
# Saída Exemplo:
# 199 UDMA_CRC_Error_Count 0x003e 200 200 000 Old_age Always - 425
O valor RAW (neste caso, 425) indica quantos pacotes chegaram com checksum inválido na interface física.
Se este número for > 0: Há um problema físico no caminho (Cabo, Backplane ou Controlador).
Se este número está aumentando: A falha é ativa.
Importante: O disco não é o culpado. Trocar o disco não resolverá o problema; o novo disco herdará o cabo ruim e continuará reportando erros.
Outro indicador crítico é o Link PHY Reset. Se você ver nos logs do kernel mensagens sobre phy reset ou renegociação de velocidade (caindo de 6Gbps para 3Gbps ou 1.5Gbps), o sistema está tentando compensar um sinal elétrico degradado baixando a frequência.
Causa Raiz: O Veredito Baseado em Evidências
Após coletar logs, analisar timestamps e verificar contadores físicos, devemos emitir o veredito. Não há espaço para "talvez".
Cenário A: O Assassino Silencioso (Cabo)
Evidência:
UDMA_CRC_Error_Countcrescendo. Logs deata1: hard resetting link. Filesystem corrompido, massmartctlself-test do disco passa sem erros.Causa Raiz: Degradação de sinal na camada física (Layer 1) da interface SATA/SAS, causando corrupção de dados em trânsito que excede a capacidade de retransmissão do protocolo.
Cenário B: A Célula Morta (RAM)
Evidência:
MCElogado nodmesgapontando consistentemente paraSocket 0 Bank 2. Endereços de falha seguem um padrão binário fixo.Causa Raiz: Falha permanente (Hard Error) em um chip DRAM específico no módulo DIMM, resultando em incapacidade de retenção de carga elétrica na célula.
Cenário C: A Tempestade Perfeita (PSU/Placa-mãe)
Evidência: Erros aleatórios tanto em MCE (RAM) quanto em CRC (Disco). Reinícios espontâneos sob carga.
Causa Raiz: Ripple excessivo na linha de 12V ou 5V da fonte de alimentação, introduzindo ruído elétrico em todos os barramentos de dados simultaneamente.
Correção Definitiva: Validação e Endurecimento da Infraestrutura
A investigação só termina quando a correção é validada. Substituir a peça é apenas o primeiro passo.
Validação de Memória Pós-Troca: Não coloque o servidor em produção imediatamente. Execute o
memtest86+por pelo menos 4 passadas completas ou utilize ferramentas de stress em OS comostress-ng:stress-ng --vm 4 --vm-bytes 90% --vm-method all --verify -t 60mIsso força a escrita e leitura de padrões na RAM e verifica a integridade.
Endurecimento de I/O: Ao trocar cabos, prefira cabos com travas metálicas e blindagem adequada. Após a troca, monitore o atributo CRC. O valor RAW nunca deve aumentar. Zere o contador (anote o valor atual) e verifique após 24h de carga.
Configuração de EDAC e MCElog: Garanta que o daemon
mcelogourasdaemonesteja ativo e configurado para enviar alertas. Em sistemas críticos, configure o kernel para entrar em pânico (kernel.panic_on_oops = 1) imediatamente ao detectar corrupção de dados não corrigível, prevenindo que dados corrompidos sejam gravados no disco.
Conclusão Forense: O hardware mente menos que o software, mas fala uma língua mais difícil. Diferenciar um bit flip de um cabo ruim exige abandonar a intuição e abraçar a análise rigorosa dos registros de erro. Na dúvida, confie no código de correção de erro (ECC) e nos contadores físicos; eles são as testemunhas oculares do crime.
Referências
Intel 64 and IA-32 Architectures Software Developer’s Manual, Volume 3B: System Programming Guide, Part 2 (Machine Check Architecture).
Gregg, Brendan. Systems Performance: Enterprise and the Cloud, 2nd Edition. Addison-Wesley Professional, 2020.
Linux Kernel Documentation. EDAC - Error Detection And Correction. kernel.org.
T13 Technical Committee. AT Attachment 8 - ATA/ATAPI Command Set (ATA8-ACS). (Referência para atributos SMART e CRC).

Roberto Sato
Planejador de Capacidade
"Traduzo métricas de consumo em modelos de crescimento sustentável. Minha missão é antecipar gargalos e garantir que sua infraestrutura escale matematicamente antes de atingir o limite crítico."