Dominando NVMe-oF: Análise de Gargalos com nvme-cli

Guia técnico para Storage Engineers: diagnostique latência, ajuste filas de I/O e interprete logs ANA em NVMe over Fabrics usando apenas o nvme-cli.
Dominando NVMe-oF: Análise de Gargalos com nvme-cli
A latência é o inimigo silencioso em qualquer infraestrutura de armazenamento. Quando migramos de DAS (Direct Attached Storage) para NVMe over Fabrics (NVMe-oF), trocamos a simplicidade do barramento PCIe local pela complexidade das redes (TCP, RDMA ou Fibre Channel). O disco não está mais "logo ali"; ele está do outro lado de um switch, competindo por largura de banda.
Diagnosticar performance em NVMe-oF exige abandonar velhos hábitos. O iostat vai te dizer que está lento, mas não por que. Para entender o que acontece entre o host e o target, precisamos dissecar o protocolo. É aqui que o nvme-cli deixa de ser um utilitário de configuração e vira uma ferramenta forense.
Resumo em 30 segundos
- Versão é Crítica: O suporte a Fabrics e multipathing nativo evolui rápido; use sempre
nvme-clie kernel Linux recentes (5.15+ recomendado).- ANA é o novo ALUA: Em arrays enterprise, o Asymmetric Namespace Access define qual caminho entrega performance máxima. Ignorá-lo causa latência alta.
- Timeouts Salvam Vidas: A configuração padrão de keep-alive pode deixar sua aplicação travada por minutos em caso de falha de rede; ajuste as flags
-ke-c.
O Ambiente: Versão e Módulos
Antes de culpar o storage, verifique sua toolchain. O protocolo NVMe muda. Novos Log Pages e funcionalidades de telemetria são adicionados constantemente. Rodar uma versão antiga do nvme-cli em um kernel moderno (ou vice-versa) é pedir para ter diagnósticos incompletos.
Verifique sua versão e os transportes carregados:
nvme version
lsmod | grep nvme
Você deve ver módulos como nvme_tcp, nvme_rdma ou nvme_fc dependendo da sua infraestrutura. Se o módulo de transporte não estiver carregado, o comando connect falhará com erros genéricos que não ajudam em nada.
 Figura: A pilha de I/O do Linux: Onde o nvme-cli intercepta e gerencia a comunicação com o Fabric.
Figura: A pilha de I/O do Linux: Onde o nvme-cli intercepta e gerencia a comunicação com o Fabric.
Topologia e Status: list-subsys
Em discos locais, usamos nvme list. Em Fabrics, esse comando é insuficiente porque esconde a relação entre controladores e subsistemas. O comando vital aqui é nvme list-subsys.
Ele revela se o Native Multipathing do NVMe está ativo e como os caminhos estão agrupados.
nvme list-subsys -o json
A saída JSON é preferível para automação, mas no terminal, o formato padrão mostra a estrutura hierárquica. Você verá o NQN (NVMe Qualified Name) do subsistema e, abaixo dele, os controladores (caminhos).
💡 Dica Pro: Se você vir múltiplos
/dev/nvmeXsob o mesmo NQN e o status estiverlive, o multipath está funcionando. Se vir subsistemas duplicados com NQNs idênticos mas separados, o kernel não conseguiu agrupar os caminhos (provavelmente erro de configuração de NQN no target ou falta dehostnqnno connect).
Ajuste Fino na Conexão: Filas e Profundidade
A maioria dos administradores roda um simples nvme connect -t tcp -a 192.168.1.10 -n <nqn>. Isso funciona, mas aceita os valores padrão do kernel para filas de I/O e profundidade de fila (queue depth). Em redes de alta latência ou throughput massivo, os padrões são conservadores.
Ao conectar, temos flags cruciais para performance:
--nr-io-queues(-i): Define quantas filas de I/O serão criadas. O ideal geralmente é parear com o número de cores da CPU para evitar locking, mas alguns targets limitam isso.--queue-size(-Q): A profundidade da fila. O padrão costuma ser 128. Para NVMe-oF em redes rápidas (100GbE+), aumentar para 1024 pode ser necessário para saturar o link, embora aumente a latência de cauda se o target não der conta.
Tabela: Impacto das Flags de Conexão
| Flag | Função | Cenário de Ajuste | Risco |
|---|---|---|---|
-i / --nr-io-queues |
Contagem de filas de submissão/conclusão | Aumentar em hosts com muitas CPUs (vCPUs) | Consumo excessivo de memória no Host e Target |
-Q / --queue-size |
Profundidade da fila (Queue Depth) | Aumentar para throughput sequencial máximo | Latência alta sob carga (Bufferbloat) |
-k / --keep-alive-tmo |
Heartbeat do protocolo | Reduzir para detecção rápida de falhas | Desconexões falsas em redes congestionadas |
ANA: O Trânsito Inteligente
Em ambientes Enterprise (NetApp, Pure Storage, Dell PowerStore), os controladores do storage não são iguais. Um pode ser o "dono" do volume, enquanto o outro é apenas um proxy ou standby. O NVMe resolve isso com ANA (Asymmetric Namespace Access).
Se você notar latência alta em apenas alguns caminhos, verifique o log ANA:
nvme ana-log /dev/nvme0n1
Procure pelo campo state.
Optimized: O caminho ideal. O I/O vai direto ao processador que controla o SSD.
Non-Optimized: O caminho funciona, mas o I/O precisa atravessar o interconnect do storage para chegar ao outro controlador. Isso adiciona latência.
Inaccessible: O caminho existe (link up), mas não pode processar I/O agora.
Se seu host estiver enviando I/O para um caminho Non-Optimized quando existe um Optimized disponível, verifique a política de multipath (cat /sys/class/nvme-subsystem/nvme-subsys0/iopolicy). Deve estar em numa ou round-robin (com consciência de ANA).
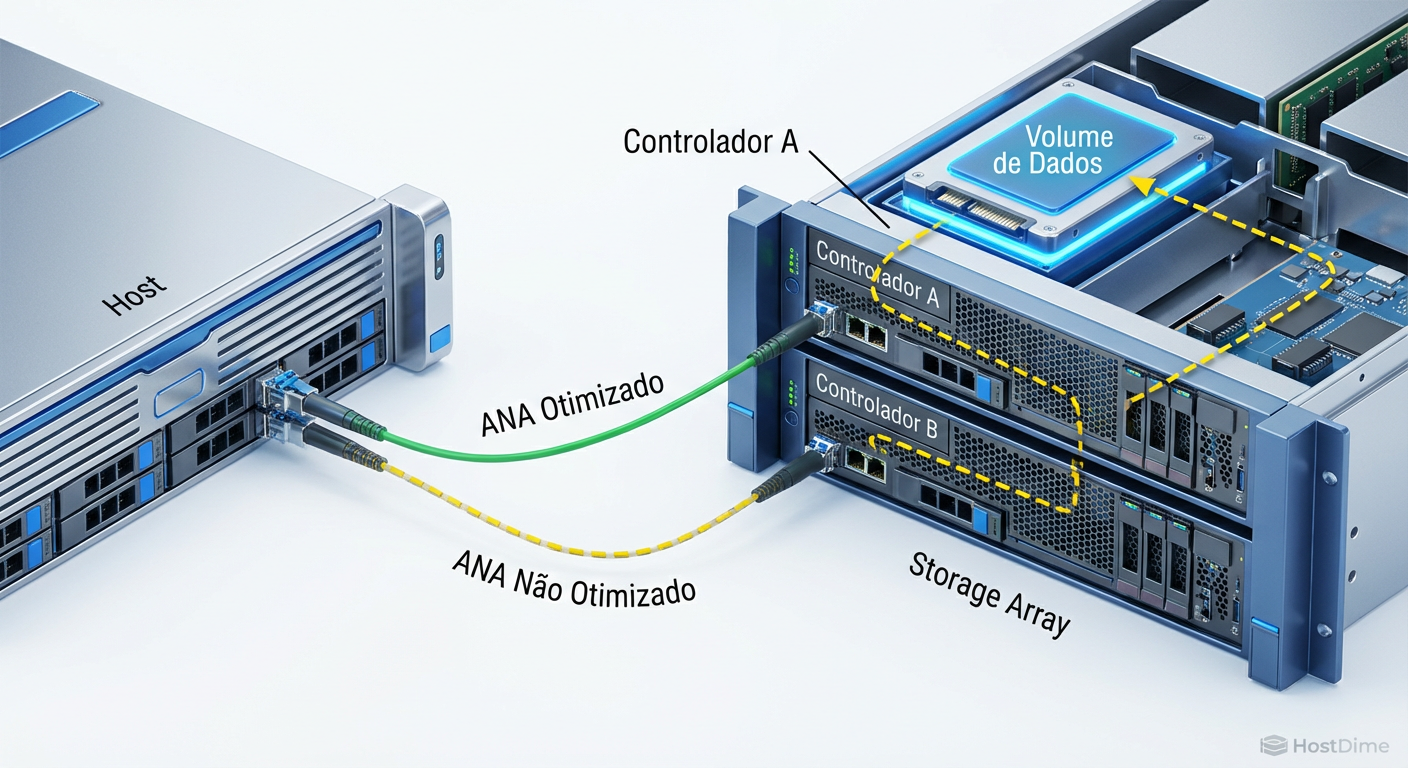 Figura: Visualização do Asymmetric Namespace Access (ANA): Por que o caminho mais curto nem sempre é o mais rápido.
Figura: Visualização do Asymmetric Namespace Access (ANA): Por que o caminho mais curto nem sempre é o mais rápido.
O Lado Sombrio: Error-Log e Transporte
Diferente do SCSI/SAS, onde erros de cabo eram óbvios, no NVMe-oF (especialmente TCP), o protocolo de rede tenta esconder a sujeira. O TCP retransmite pacotes perdidos. Para a aplicação, parece apenas "lentidão".
Para ver se a rede está degradando a performance do disco, precisamos olhar o log de erros interno do controlador NVMe, não apenas o dmesg.
nvme error-log /dev/nvme0
Foque nas entradas que mencionam Transport Error. Se você usa NVMe/TCP, cruze esses dados com estatísticas de rede:
netstat -s | grep -i "retrans"
Um aumento correlacionado entre retransmissões TCP e erros no nvme error-log indica problemas físicos (cabos, portas de switch, CRC errors) ou congestionamento severo (micro-bursts) que o Flow Control não segurou.
⚠️ Perigo: Ignorar contadores de erro de transporte é a causa número 1 de "latência fantasma". O disco está saudável, o host está saudável, mas a rede está perdendo 1% dos pacotes e destruindo a performance do NVMe.
Keep-Alive e Timeouts: Evitando o "Hang"
O padrão do NVMe para keep-alive costuma ser conservador. Se um cabo é puxado ou um switch reinicia, o driver NVMe pode esperar muito tempo antes de declarar o caminho morto e falhar o I/O (ou fazer failover).
No comando connect, duas flags controlam a paciência do host:
-k(--keep-alive-tmo): Frequência e timeout do heartbeat.-c(--ctrl-loss-tmo): Quanto tempo esperar após perder a conexão antes de remover o dispositivo do sistema operacional.
Para ambientes críticos, reduzir o -c evita que processos fiquem em estado D (Uninterruptible Sleep) por minutos esperando um storage que não vai voltar. No entanto, cuidado com valores muito baixos em redes TCP instáveis; você pode causar "flapping" de conexões.
Previsão
O futuro do NVMe-oF está na descarga de processamento. Veremos o nvme-cli interagir cada vez mais com SmartNICs e DPUs para configurar offloads de criptografia e compressão diretamente no comando de conexão. A complexidade vai sair do kernel do host e ir para o hardware de rede. Até lá, dominar essas flags é o que separa um cluster lento de um cluster de alta performance.
FAQ: Perguntas Frequentes
Qual a diferença entre nvme connect e nvme connect-all?
O `connect` é cirúrgico: estabelece uma ligação com um subsistema específico que você define via NQN. Já o `connect-all` é exploratório: ele contata o Discovery Controller, lê o log de descoberta (Discovery Log Page) e conecta automaticamente a todos os subsistemas que o target anunciar para o seu host.Como verificar se o multipath do NVMe-oF está funcionando?
Esqueça o `dm-multipath` antigo. Utilize o comando `nvme list-subsys`. Na saída, verifique se o subsistema (identificado pelo NQN) agrupa múltiplos controladores (ex: `nvme0`, `nvme1`) sob a mesma estrutura. Se o estado estiver `live` e agrupado, o multipath nativo do NVMe está operando.O que é o erro 'Connect command failed, error: 11'?
Esse código de erro geralmente traduz para "Resource temporarily unavailable" (EAGAIN). No contexto de NVMe over Fabrics, isso frequentemente sinaliza que o host esgotou as portas TCP efêmeras disponíveis para abrir novas conexões, ou que o target atingiu seu limite máximo configurado de conexões ou filas por host (Host Queue Limit).
Arthur Costas
Especialista em FinOps
"Transformo infraestrutura em números. Meu foco é reduzir TCO, equilibrar CAPEX vs OPEX e garantir que cada centavo investido no datacenter traga ROI real."