Dominando o FIO: Benchmarking Realista de Storage para VMs, Bancos de Dados e Backups
Pare de testar storage errado. Aprenda a configurar o FIO com presets reais para OLTP, Virtualização e Object Storage. Métricas que importam além do IOPS.
Se você está validando a performance do subsistema de armazenamento do seu banco de dados copiando um arquivo de 10GB via sistema operacional ou, pior, utilizando o comando dd, pare imediatamente. Você está medindo a velocidade com que seu sistema operacional armazena cache na RAM, não a capacidade real do seu disco em sustentar transações atômicas.
Como Arquiteto de Workloads, minha premissa é absoluta: um banco de dados não é um arquivo de vídeo. Tratar armazenamento como uma commodity genérica é o erro número um em projetos de infraestrutura crítica. O armazenamento se comporta de maneira radicalmente diferente dependendo de como você pede os dados.
Para entender a verdade sobre seu storage, você precisa dominar o Flexible I/O Tester (FIO). Este artigo disseca como arquitetar testes de estresse que replicam a realidade hostil de ambientes produtivos, separando métricas de vaidade de KPIs operacionais reais.
Perfil do Workload: Por que um Banco de Dados não é um Arquivo de Vídeo
A performance de armazenamento é governada pela física do acesso aos dados, seja em discos rotacionais, SSDs NAND ou NVMe. O erro fundamental de muitos engenheiros é olhar apenas para a etiqueta do fabricante que promete "5.000 MB/s de leitura". Esse número é irrelevante para 90% dos workloads corporativos.
Para desenhar um benchmark realista, precisamos distinguir dois comportamentos antagônicos:
Acesso Sequencial (Throughput): Imagine um trem em um trilho. É fácil carregar vagões um atrás do outro. É assim que funcionam backups, streaming de vídeo e data lakes. O cabeçote (ou controlador) lê blocos contíguos (LBA $N, N+1, N+2$). Aqui, a métrica rainha é MB/s ou GB/s.
Acesso Aleatório (IOPS): Imagine um carteiro entregando cartas em casas aleatórias espalhadas pela cidade. Ele gasta mais tempo se deslocando (seek time) do que entregando a carta. É assim que funcionam bancos de dados OLTP, virtualização e sistemas de mensageria. O sistema pede o bloco 400, depois o 9000, depois o 2. A métrica rainha é IOPS (Input/Output Operations Per Second).
 Figura: Fig. 1: A física do acesso aos dados define a performance. Bancos de dados fragmentam o I/O; backups o alinham.
Figura: Fig. 1: A física do acesso aos dados define a performance. Bancos de dados fragmentam o I/O; backups o alinham.
Bancos de dados relacionais (RDBMS) como PostgreSQL, MySQL ou Oracle fragmentam o I/O. Eles leem páginas de dados (geralmente 8KB ou 16KB) espalhadas pelo disco. Se você testar seu storage com blocos de 1MB sequenciais, você terá um resultado lindo, mas quando o banco de dados entrar em produção, a performance colapsará porque o storage não consegue lidar com a intensidade de operações pequenas e aleatórias.
A Matemática do Block Size
O tamanho do bloco (block size) é a variável mais crítica do FIO (--bs).
4k - 8k: Típico de logs de transação e leituras de índices (Random I/O).
64k - 128k: Comum em Scans de tabelas ou operações de Data Warehouse.
1M+: Backup e Object Storage.
Se o seu FIO não especifica o block size correto, o teste é nulo.
Requisitos de Latência: O SLA Silencioso (CLAT vs SLAT)
Em arquitetura de workloads de alta performance, IOPS é apenas metade da história. A outra metade, frequentemente ignorada até que a aplicação comece a travar, é a latência. Mas não qualquer latência.
O FIO nos permite dissecar a latência em duas métricas vitais para DBAs e Arquitetos:
SLAT (Submission Latency): O tempo que leva para o processador "entregar" o pedido de I/O ao subsistema de armazenamento. Se o SLAT está alto, seu problema não é o disco, é a CPU ou o Kernel que estão engasgados (CPU contention).
CLAT (Completion Latency): O tempo que o disco leva para processar o pedido e devolver o dado após ter recebido a ordem. Este é o número que julga a qualidade do seu storage.
O Impacto no ACID
Para um banco de dados garantir durabilidade (o 'D' em ACID), ele precisa fazer um fsync — obrigar o disco a confirmar que o dado foi persistido fisicamente, e não apenas salvo no cache do controlador.
Se o seu CLAT médio é de 5ms, mas você tem picos de 200ms, seu banco de dados irá "congelar" as transações esperando o disco. Em testes com FIO, devemos monitorar rigorosamente se o CLAT excede os requisitos da aplicação (geralmente sub-milissegundo para All-Flash Arrays).
Seleção de Storage e Presets FIO para Virtualização (O Efeito I/O Blender)
Ambientes virtualizados (VMware, KVM, Hyper-V) introduzem o caos no padrão de I/O, conhecido como "The I/O Blender Effect" (Efeito Liquidificador de I/O).
Mesmo que você tenha três VMs executando tarefas sequenciais, quando esses pedidos chegam ao hypervisor e descem para o storage físico, eles são intercalados. Para o storage array, aquilo parece um tráfego totalmente aleatório.
Configurando o FIO para Simular VMs
Ao benchmarkar storage para virtualização, devemos aumentar a profundidade da fila (iodepth). O storage moderno precisa de paralelismo para brilhar.
Parâmetros Chave:
ioengine=libaio(Linux Asynchronous I/O) ouioengine=io_uring(para kernels 5.10+ de alta performance).iodepth=32ou superior: Simula múltiplas threads/VMs requisitando dados simultaneamente.direct=1: Mandatório. Ignora o page cache do sistema operacional. Se você não usar isso, estará testando sua RAM, não seu disco.
 Figura: Fig. 2: Matriz de Presets do FIO. Cada coluna representa uma estratégia de teste alinhada ao comportamento real da aplicação.
Figura: Fig. 2: Matriz de Presets do FIO. Cada coluna representa uma estratégia de teste alinhada ao comportamento real da aplicação.
A tabela acima (Fig. 2) ilustra como diferentes configurações do FIO mapeiam para cenários reais. Note que para virtualização, o foco muda de latência pura de thread única para a capacidade de processar filas profundas sem degradação.
Simulação de Bancos de Dados OLTP: Tuning para Acesso Aleatório e ACID
Este é o cenário mais complexo e onde a maioria dos arquitetos falha. Um workload OLTP (Online Transaction Processing) é caracterizado por pequenas leituras e escritas aleatórias, com alta exigência de consistência.
Para simular um PostgreSQL ou MySQL, não basta gerar tráfego aleatório. Precisamos simular a proporção de leitura/escrita e o comportamento de sincronização.
Arquétipo de Teste OLTP (Exemplo Técnico)
Abaixo, apresento um job file do FIO desenhado para estressar um storage destinado a um banco de dados transacional pesado.
[global]
ioengine=libaio
direct=1
time_based
runtime=300 ; Execute por 5 minutos para estabilizar o cache do controlador
group_reporting
disk_util_check_command=iostat -x -d 1
; Definição do Perfil OLTP
[db-oltp-simulation]
filename=/dev/sdb ; NUNCA use o disco do SO. Use um volume dedicado.
bs=8k ; Tamanho de página padrão do PostgreSQL/Oracle
rw=randrw ; Leitura e Escrita Aleatória
rwmixread=75 ; Mix típico: 75% Leitura, 25% Escrita
iodepth=64 ; Alta concorrência
numjobs=4 ; Simula múltiplas conexões/processos de DB
fsync=1 ; OBRIGATÓRIO para simular commit de transação real (WAL)
Análise dos Parâmetros:
rw=randrw: O banco acessa linhas específicas em tabelas gigantes. Isso é aleatório.bs=8k: Alinha o teste com a página de memória do banco. Usar 4k (padrão de SSD) pode dar resultados inflados irreais para o DB.fsync=1: Este é o "matador de performance". Ele força o flush para o disco a cada escrita. Sem isso, você não está testando um banco de dados, está testando um sistema de arquivos temporário. Muitos storages "rápidos" colapsam quandofsyncé ativado.
Cenários de Backup e Object Storage: Onde o Throughput Sequencial é Rei
Diferente do OLTP, operações de Backup (Veeam, RMAN) ou ingestão em Object Storage (MinIO, Ceph) dependem de "largura de banda". Aqui, o disco não precisa buscar posições aleatórias; ele precisa engolir um fluxo contínuo de dados.
Neste cenário, a latência de cada operação individual é menos importante que o volume total transferido por segundo.
Tuning para Throughput Sequencial
Para validar se seu storage aguenta a janela de backup da madrugada:
Aumente o Block Size: Mude
--bspara1Mou4M. Backups escrevem em grandes chunks.Mude o Padrão: Use
rw=write(sequencial puro) ourw=read.Numjobs: Aumente o número de jobs se o seu software de backup usa multithreading (ex: RMAN channels).
Comparativo de Estratégia:
| Característica | Workload OLTP (Banco de Dados) | Workload Backup/Streaming |
|---|---|---|
| Padrão de Acesso | Aleatório (randrw) |
Sequencial (read/write) |
| Tamanho do Bloco | Pequeno (4k, 8k, 16k) | Grande (512k, 1M, 4M) |
| Métrica Principal | IOPS & Latência (ms) | Throughput (MB/s) |
| Fator Crítico | Seek Time / Controller Latency | Interface Bandwidth / Disk Rotation Speed |
Validação e Interpretação: Lendo os Percentis (p95, p99) no Output
Executar o comando é fácil. Interpretar a saída separa os amadores dos especialistas. O FIO cospe uma quantidade massiva de dados. Onde focar?
Ignore a Média (Avg). A média é a métrica dos tolos. Se o seu storage responde em 1ms na maioria das vezes, mas a cada 10 segundos ele trava por 2 segundos (garbage collection do SSD, por exemplo), a média ainda parecerá boa, mas sua aplicação terá timeouts.
O Foco nos Percentis
Você deve olhar para a seção de clat percentiles do output do FIO:
p95 (95th percentile): 95% das suas requisições foram mais rápidas que este número. É o seu "dia a dia".
p99 (99th percentile): Os 1% mais lentos. É aqui que vivem os "stalls" de I/O que causam reclamações de usuários.
p99.99: A latência máxima. Em sistemas financeiros, isso define o SLA.
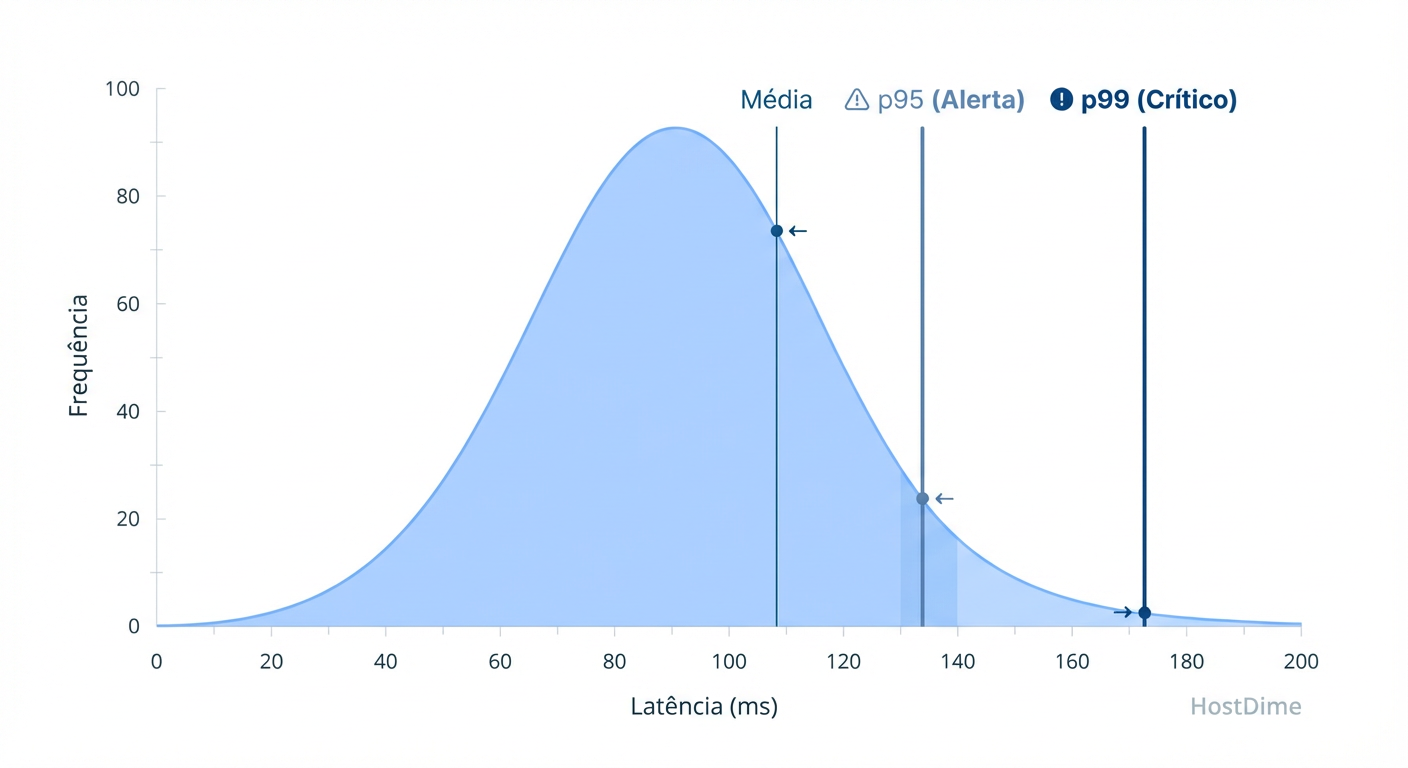 Figura: Fig. 3: A tirania da média. A validação real de um storage para banco de dados vive nos percentis p95 e p99, onde os 'stalls' de I/O ocorrem.
Figura: Fig. 3: A tirania da média. A validação real de um storage para banco de dados vive nos percentis p95 e p99, onde os 'stalls' de I/O ocorrem.
Exemplo de Leitura de Output:
read: IOPS=15.2k, BW=119MiB/s (125MB/s)(34.8GiB/300002msec)
clat (usec): min=82, max=18564, avg=312.45, stdev=154.12
95.00th=[ 844], 99.00th=[ 1256], 99.90th=[ 4520]
Neste exemplo, a média é excelente (312 microsegundos). Porém, o p99.90 mostra picos de 4.5ms. Para um banco de dados em memória, isso é aceitável. Se o p99 estivesse em 50ms, este storage estaria reprovado para cargas transacionais críticas, independentemente de quantos IOPS ele entregou.
Veredito Técnico: O Disco Não Mente
Benchmarking de storage não é sobre obter o maior número para colocar em um slide de marketing. É sobre previsibilidade sob estresse.
Ao utilizar o FIO com os parâmetros corretos — alinhando block sizes, simulando concorrência e respeitando a física do acesso aleatório vs. sequencial — você deixa de adivinhar e passa a arquitetar. Lembre-se: em produção, o storage é o único componente que tem gravidade; todo o resto é efêmero. Teste-o com o rigor que seus dados merecem.
Referências
Jens Axboe. FIO - Flexible I/O Tester Documentation. Source Code & Docs.
PostgreSQL Global Development Group. PostgreSQL Documentation: Reliability and the Write-Ahead Log.
Gregg, Brendan. Systems Performance: Enterprise and the Cloud, 2nd Edition. Addison-Wesley Professional, 2020.
NVM Express Organization. NVMe Specification 1.4: Queue Depth and Arbitration.
VMware. Storage I/O Performance Characterization and Workload Analysis. Technical Whitepaper.

Ricardo Vilela
Especialista em Compras/Procurement
"Especialista em dissecar contratos e destruir argumentos de vendas. Meu foco é TCO, SLAs blindados e evitar armadilhas de lock-in. Se não está no papel, não existe."