DWPD e TBW: A matemática oculta no custo real de storage em 2026

Não compre SSDs olhando apenas o preço por terabyte. Descubra como o DWPD e o TBW definem o TCO da sua infraestrutura e evite o 'lock-in' de hardware prematuro em meio à crise de NAND de 2026.
Você acabou de receber uma proposta de renovação de infraestrutura de storage. O preço por terabyte parece incrível, quase um erro de digitação de tão baixo. O vendedor, com aquele sorriso treinado, garante que esses novos SSDs NVMe são "otimizados para data center" e vão reduzir seu CAPEX em 40%. Se você assinar agora, ele garante o preço antes do fechamento do trimestre.
Pare. Respire. E coloque a caneta na mesa.
O que ele não te contou — e o que a maioria dos gestores de TI descobre da pior maneira, geralmente às 3 da manhã de um sábado — é que o preço de aquisição é apenas a ponta do iceberg. Em 2026, com a volatilidade do mercado de NAND e a demanda insana de workloads de IA, a verdadeira métrica de custo não é o Real por GB. É o Real por Escrita.
Se você não domina os conceitos de DWPD (Drive Writes Per Day) e TBW (Terabytes Written), você não está comprando armazenamento; você está alugando uma falha catastrófica futura. Vamos dissecar as letras miúdas que os fornecedores adoram esconder.
Resumo em 30 segundos
- A métrica da verdade: O preço por GB é uma métrica de vaidade. O custo real de um SSD Enterprise deve ser calculado dividindo o preço pelo TBW (vida útil de escrita).
- O risco do "Consumer Grade": Usar SSDs sem proteção contra perda de energia (PLP) em servidores é negligência. A economia no CAPEX vira prejuízo no OPEX na primeira corrupção de banco de dados.
- Garantia vs. Uso: A garantia do fabricante expira por tempo (5 anos) OU por volume de dados escritos (TBW). Se sua carga de trabalho de IA queimar o disco em 6 meses, o custo de reposição é 100% seu.
O cenário de 2026 e a retração da oferta de NAND
Estamos vivendo o que os analistas chamam de "ressaca da euforia". Após a explosão de demanda por infraestrutura de IA em 2024 e 2025, a cadeia de suprimentos de memória NAND se ajustou, mas não a favor do comprador. Os fabricantes de chips pivotaram linhas de produção inteiras para atender a demanda de HBM (High Bandwidth Memory) para GPUs, deixando o mercado de NAND flash tradicional com oferta restrita.
Isso criou um cenário perigoso para compras corporativas. Para manter os preços "atraentes" nos catálogos, muitos vendors começaram a empurrar drives com memórias QLC (Quad-Level Cell) de baixa resistência para cargas de trabalho que exigem TLC (Triple-Level Cell).
Eles chamam de "Read-Intensive Enterprise SSD". Eu chamo de bomba-relógio. Se você colocar um desses drives em um cluster de virtualização ou, pior, num servidor de banco de dados transacional, você vai estourar o limite de escrita muito antes do fim do contrato de suporte.
A armadilha do hardware de prateleira no data center
É tentador. Você abre um site de varejo e vê um SSD NVMe Gen5 "Gamer" com velocidades de leitura sequencial de 14.000 MB/s custando metade do preço do drive que seu fornecedor de storage enterprise (Dell, HPE, NetApp) está cotando.
Por que pagar o dobro por um drive que, no papel, parece mais lento?
A resposta técnica tem três letras: PLP (Power Loss Protection).
⚠️ Perigo: SSDs de consumo (client drives) dependem da RAM do sistema e de caches voláteis para atingir essas velocidades absurdas de marketing. Se a energia piscar, os dados que estavam no cache — e que o sistema operacional achava que já estavam gravados — desaparecem. O resultado é corrupção lógica de LUNs e bancos de dados inconsistentes.
SSDs Enterprise possuem capacitores de tântalo visíveis no PCB. Eles garantem energia suficiente para que o drive "despeje" o cache para a memória NAND em caso de corte abrupto de energia. Além disso, drives de consumo sofrem de latência de cauda inconsistente. Sob carga constante 24/7, o garbage collection do firmware de consumo engasga, fazendo a latência de I/O saltar de 0.1ms para 500ms aleatoriamente. Seu cluster vSAN ou Ceph vai marcar esse disco como falho e iniciar um rebuild desnecessário, degradando todo o array.
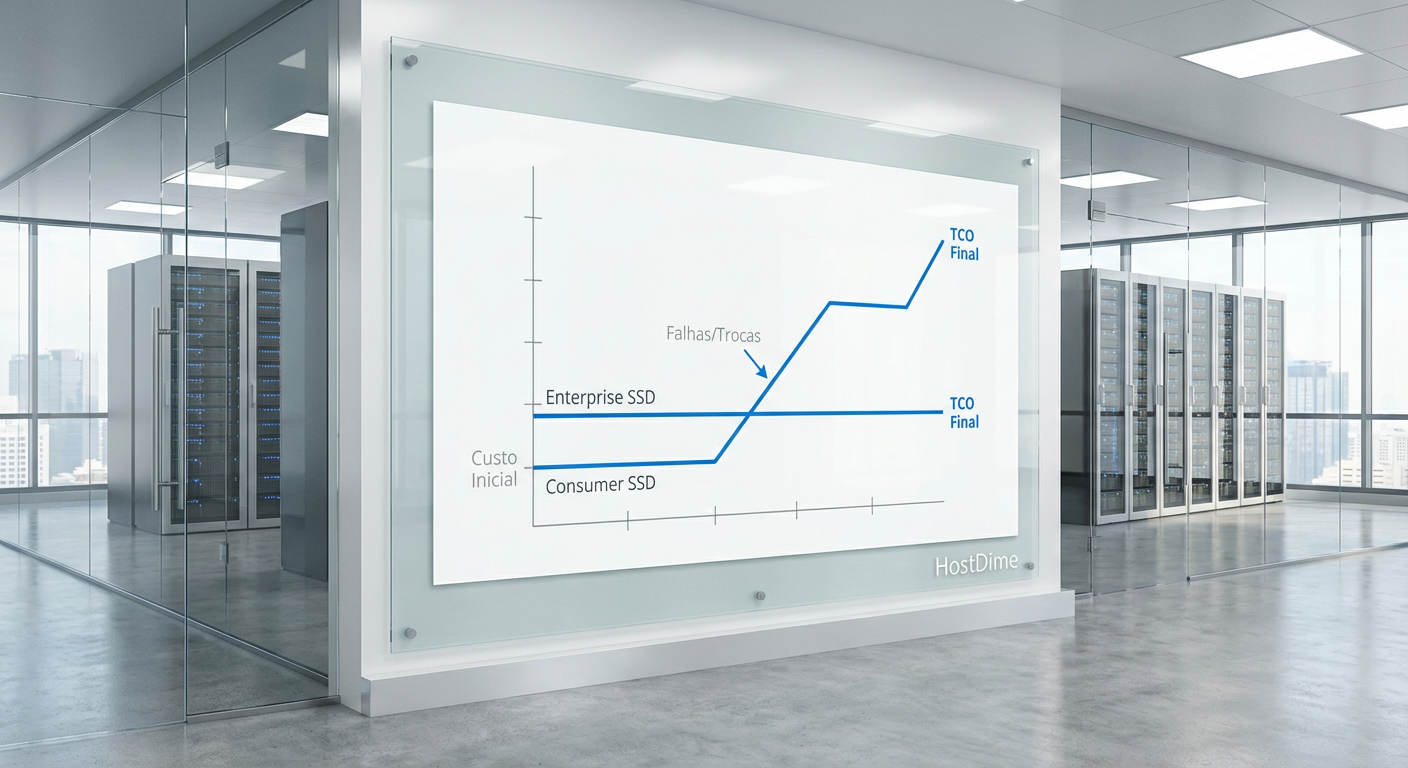 Fig. 1: A interseção onde o 'SSD barato' destrói o orçamento de OPEX em 36 meses.
Fig. 1: A interseção onde o 'SSD barato' destrói o orçamento de OPEX em 36 meses.
Calculando o custo por escrita: a fórmula de negociação
Quando sento para negociar renovação de storage, ignoro o slide de "Preço por Terabyte" do vendedor. Eu abro a planilha e calculo o Custo por Petabyte Escrito (CPPW).
A matemática é simples e destrói argumentos de venda baseados apenas em preço de etiqueta.
Fórmula:
Preço do Drive / TBW (em Petabytes) = Custo por PB Escrito
Vamos comparar dois cenários reais de cotação que recebi recentemente para um array All-Flash:
Cenário A: O "Barato" (QLC Read-Intensive)
Capacidade: 3.84 TB
Preço Unitário: R$ 2.500,00
DWPD: 0.1 (suporta escrever 10% da capacidade por dia)
TBW Total (5 anos): ~700 TB (0.7 PB)
Custo por PB Escrito: R$ 3.571,00
Cenário B: O "Caro" (TLC Mixed-Use)
Capacidade: 3.2 TB (sim, menor capacidade nominal devido ao overprovisioning)
Preço Unitário: R$ 4.200,00
DWPD: 3.0 (suporta escrever 3x a capacidade por dia)
TBW Total (5 anos): ~17.500 TB (17.5 PB)
Custo por PB Escrito: R$ 240,00
Olhe para os números. O drive "caro" é, na verdade, 14 vezes mais barato se considerarmos o custo por unidade de escrita garantida. Se sua aplicação for um banco de dados OLTP ou logs de ingestão de IA, o drive do Cenário A vai perder a garantia em menos de 8 meses de operação. Você terá que comprar esse drive 6 ou 7 vezes para cobrir o ciclo de vida do servidor.
💡 Dica Pro: Exija que o fornecedor inclua o TBW nominal no contrato de compra, não apenas o modelo do drive. Isso impede que eles troquem o part number por uma revisão mais barata com memória NAND inferior na entrega (o famoso "bait and switch").
Estratégia de tiering e alocação de durabilidade
Não estou dizendo para comprar DWPD 3.0 para tudo. Isso seria queimar orçamento. O segredo de um Procurement eficiente em 2026 é o alinhamento granular entre a durabilidade do disco e o workload real.
O erro comum é tratar "All-Flash" como uma categoria única.
1. Tier de Ingestão e IA (Write Intensive)
Aqui vivem seus bancos de dados Oracle/PostgreSQL, caches de escrita de ZFS/vSAN e diretórios de scratch para treinamento de modelos de IA.
Requisito: Mínimo de 3 DWPD. Idealmente memórias SLC ou eTLC.
Risco: Se economizar aqui, o drive entra em modo "Read Only" para se proteger quando o TBW estourar, parando sua operação.
2. Tier de Virtualização Geral (Mixed Use)
Servidores de arquivos, VMs de aplicação web, controladores de domínio.
Requisito: 1 DWPD.
Equilíbrio: É o ponto ideal de custo-benefício para 70% do data center.
3. Tier de Backup e Object Storage (Read Intensive)
Repositórios Veeam, MinIO, Data Lakes para leitura.
Requisito: 0.1 a 0.3 DWPD (QLC é aceitável aqui).
Atenção: O problema aqui não é a escrita diária, é a reidratação de dados ou rebuilds de RAID. Certifique-se de que o algoritmo de erasure coding do seu software de storage não pune excessivamente os discos durante a recuperação.
Garantia de uptime através do SLA de disco
Muitos gestores esquecem de ler a cláusula de "Uso Aceitável" nos contratos de garantia. Os fabricantes de storage (Dell, Pure, NetApp, Huawei) têm sistemas de telemetria que reportam o desgaste do SSD.
Se um disco falha e a telemetria mostra que você ultrapassou o TBW especificado, não é um caso de garantia. É considerado "uso indevido". O fornecedor pode se recusar a substituir a peça sem custo.
Em negociações de contratos grandes, eu insisto em uma cláusula de "Substituição Incondicional por Falha" ou garanto um pool de spares (discos de reposição) que já contemple o desgaste acelerado previsto.
Além disso, monitore o SMART dos seus discos via SNMP ou IPMI. Configure alertas quando o indicador de "Percentage Lifetime Used" atingir 80%. Não espere o disco falhar. Planeje a compra de reposição no budget do ano seguinte assim que a tendência de desgaste se confirmar.
Perguntas frequentes
1. O que acontece exatamente quando um SSD atinge o limite de TBW? Diferente de um HDD que começa a fazer barulho e falha mecanicamente, o SSD entra em um modo de proteção. O firmware bloqueia novas escritas (modo Read-Only). Se isso acontecer no disco de boot do seu hypervisor ou no log do banco de dados, o serviço para instantaneamente.
2. NVMe é sempre melhor que SAS/SATA SSD? Em performance, sim. Em durabilidade, não necessariamente. Um SSD SAS Enterprise antigo pode ter uma durabilidade muito superior a um NVMe de entrada. O protocolo (interface) não dita a qualidade da memória NAND. Verifique sempre o datasheet.
3. Posso misturar discos com DWPD diferentes no mesmo array? Tecnicamente sim, mas operacionalmente é um pesadelo. O controlador RAID/ZFS geralmente nivela a performance por baixo. Além disso, o desgaste desigual fará com que você tenha que trocar discos em momentos diferentes, aumentando a complexidade da manutenção física no data center.
4. O que é "Write Amplification" e como isso afeta meu bolso? É um fenômeno onde o SSD precisa escrever mais dados fisicamente do que o solicitado pelo sistema operacional, devido à gestão interna dos blocos de memória. Discos baratos têm controladores piores e maior amplificação de escrita, o que consome o TBW mais rápido. Discos Enterprise têm algoritmos eficientes e caches DRAM maiores para mitigar isso.
Alerta de orçamento
O mercado de storage em 2026 é hostil para quem compra baseado apenas em capacidade bruta. A ilusão do "SSD barato" é a maior ameaça ao seu OPEX de longo prazo.
Minha recomendação final: antes de assinar qualquer PO (Purchase Order), peça ao fornecedor o datasheet técnico exato dos part numbers cotados. Calcule o custo por PB escrito. Se o vendedor gaguejar ou disser que "para seu uso isso sobra", desconfie. No data center, a redundância protege contra falhas, mas apenas a matemática protege seu orçamento. Negocie durabilidade, não apenas gigabytes.

Ricardo Vilela
Especialista em Compras/Procurement
"Especialista em dissecar contratos e destruir argumentos de vendas. Meu foco é TCO, SLAs blindados e evitar armadilhas de lock-in. Se não está no papel, não existe."