Engenharia de Performance ZFS: Eliminando a Latência de Metadados com Special VDEVs

Descubra como a arquitetura de Special VDEVs no OpenZFS resolve gargalos de IOPS em pools híbridos. Guia avançado de SRE sobre dimensionamento, riscos e validação.
A latência não é apenas um número em um painel; é o principal indicador de que a arquitetura de armazenamento falhou em acompanhar a demanda da aplicação. Quando um sistema de arquivos ZFS na escala de petabytes engasga em uma simples operação de listagem de diretórios (ls ou find), não estamos lidando com um problema de "disco lento". Estamos enfrentando uma violação fundamental da física dos discos rotacionais em relação à estrutura da árvore Merkle do ZFS.
Na engenharia de confiabilidade (SRE), aprendemos a não culpar o operador ou o hardware por comportamentos previsíveis. Discos rígidos (HDDs) são excelentes em taxa de transferência sequencial, mas terríveis em operações aleatórias (IOPS). O ZFS, por design, espalha metadados por todo o disco. O resultado é um cenário onde seus HDDs de 20TB passam mais tempo buscando cabeçalhos (seek time) do que lendo dados. A solução não é mais cache volátil, mas uma mudança estrutural na topologia do pool: a implementação de Special VDEVs (Allocation Classes).
Resumo em 30 segundos
- O Gargalo: Em pools grandes de HDD, a busca por metadados fragmentados causa latência de cauda severa, travando aplicações sensíveis.
- A Solução: Special VDEVs isolam fisicamente metadados e blocos pequenos em armazenamento flash (NVMe/SSD), mantendo dados brutos nos HDDs.
- O Risco: Um Special VDEV é parte integrante do pool. Se ele falhar sem redundância, todo o pool é perdido. Espelhamento triplo é o padrão ouro.
A latência de cauda e a física da Árvore Merkle
Para entender por que seu array de armazenamento parece congelar durante metadados intensos, precisamos olhar para a estrutura on-disk. O ZFS é um sistema de arquivos transacional copy-on-write. Isso significa que ele nunca sobrescreve dados no local; ele escreve novos dados em um novo bloco e atualiza os ponteiros.
Essa arquitetura cria uma árvore de blocos (Merkle Tree). Para ler um arquivo, o sistema precisa:
Ler o uberblock.
Ler os blocos indiretos (ponteiros) que dizem onde o arquivo está.
Ler o dnode (metadados do arquivo).
Finalmente, ler o dado.
Em um pool baseado puramente em HDDs, cada um desses passos exige um movimento mecânico da agulha do disco. Se o seu pool está fragmentado — um estado natural de sistemas copy-on-write com o tempo — esses metadados estão espalhados aleatoriamente pelos pratos magnéticos.
O resultado é uma amplificação de leitura. Um pedido lógico de I/O se transforma em 3 ou 4 I/Os físicos aleatórios. Em discos que suportam apenas 100-150 IOPS, a saturação é imediata. A latência de cauda (o 99º percentil ou p99) dispara de milissegundos para segundos. Do ponto de vista do SLO (Service Level Objective), o serviço está indisponível, mesmo que os discos estejam saudáveis.
O mito do L2ARC para consistência de performance
Frequentemente, administradores tentam resolver esse problema adicionando um L2ARC (Cache de Leitura de Nível 2 em SSD). Embora ajude, o L2ARC possui falhas fundamentais para este cenário específico de confiabilidade:
Aquecimento (Warm-up): O L2ARC começa vazio a cada reinicialização. Até ser populado, o sistema sofre com a performance nativa dos HDDs.
Despejo (Eviction): Se o conjunto de trabalho de metadados for maior que o tamanho do cache, o sistema entra em thrashing, e as leituras voltam a cair (fall-through) para os discos lentos.
Natureza Volátil: O L2ARC não é o local autoritativo dos dados.
A engenharia de confiabilidade exige previsibilidade. O cache melhora a média, mas não eleva o piso de performance. Para garantir latência baixa constante, precisamos que os metadados residam permanentemente em mídia rápida.
Arquitetura de classes de alocação: Isolamento físico
A partir da versão 0.8 do ZFS (e solidificado nas versões atuais do OpenZFS 2.x), introduziu-se o conceito de Allocation Classes. Isso permite designar VDEVs específicos para tipos específicos de dados. Ao adicionar um VDEV do tipo special, o ZFS altera sua política de alocação de blocos.
O alocador passa a direcionar preferencialmente para este dispositivo flash:
Todos os metadados (DDT, tabelas de blocos indiretos, atributos de diretórios).
Blocos de dados pequenos (configurável via propriedade
special_small_blocks).
 Fig 1. Segregação física de I/O baseada no tamanho do bloco e tipo de dado.
Fig 1. Segregação física de I/O baseada no tamanho do bloco e tipo de dado.
Isso cria um sistema híbrido verdadeiro. Os HDDs ficam livres para fazer o que fazem melhor: leituras e escritas sequenciais de grandes arquivos (streaming). O NVMe assume a carga brutal de I/O aleatório dos metadados.
💡 Dica Pro: Ao configurar
special_small_blocks, o valor ideal geralmente é igual aorecordsizedo seu banco de dados ou 4K/8K para servidores de arquivos gerais. Isso move não apenas os "mapas" dos arquivos, mas os próprios arquivos pequenos para o flash, economizando IOPS preciosos nos discos rotacionais.
O risco crítico: Redundância ou morte
Aqui reside a distinção vital entre um cache (L2ARC/SLOG) e um VDEV Especial.
Se o seu dispositivo de L2ARC falhar, o ZFS simplesmente o ignora e lê dos discos. A performance cai, mas os dados estão seguros. Se o seu VDEV Especial falhar, você perde o pool inteiro.
Como o VDEV Especial contém os metadados (o mapa de onde seus dados estão), perdê-lo é equivalente a perder a tabela de alocação. Os dados nos HDDs tornam-se blobs ilegíveis de bits.
Portanto, a regra de ouro da SRE para topologia de armazenamento se aplica: A confiabilidade do VDEV Especial deve igualar ou exceder a confiabilidade do pool de dados.
Se o seu pool principal é RAID-Z2 (tolera 2 falhas), seu VDEV Especial deve ser, no mínimo, um espelho triplo (3-way mirror) de SSDs.
Nunca use um único SSD para esta função em produção.
Use SSDs de classe Enterprise com proteção contra perda de energia (PLP). Metadados são escritos frequentemente e a integridade em caso de corte de energia é não-negociável.
Dimensionamento científico com histogramas de blocos
Adivinhar o tamanho necessário para o VDEV Especial é um convite ao desperdício de orçamento ou falha operacional. Se o VDEV Especial encher, os metadados transbordam (spillover) para os HDDs, reintroduzindo a latência que tentamos eliminar.
Para dimensionar corretamente, usamos a ferramenta zdb para analisar a distribuição atual de blocos. O comando abaixo deve ser executado em momentos de baixa carga, pois percorre metadados:
zdb -Lbbb <nome_do_pool>
A saída fornecerá um histograma detalhado. Você deve somar:
Todo o espaço consumido por metadados (L1, L2, etc.).
O espaço consumido por blocos de dados abaixo do seu limite de corte (ex: <= 8K ou 32K).
Geralmente, uma regra empírica segura para sistemas de arquivos genéricos é de 0,3% a 1% da capacidade total do pool apenas para metadados. Se você planeja incluir pequenos blocos de dados (special_small_blocks), esse número pode subir para 3-5%.
⚠️ Perigo: Lembre-se que o ZFS precisa de espaço livre para funcionar bem. Dimensione seu VDEV Especial para que ele opere abaixo de 75% de ocupação. A performance de escrita em SSDs degrada drasticamente quando cheios devido à amplificação de escrita interna do drive (garbage collection).
Observabilidade e validação de redução de latência
Após a implementação, a validação não deve ser baseada em "sensação" de velocidade, mas em métricas (SLIs).
Utilize o zpool iostat -v para observar a distribuição de carga. Em um sistema saudável com VDEV Especial, você verá:
VDEV Especial: Alto número de operações (IOPS), baixa largura de banda.
VDEVs de Dados (HDD): Baixo número de operações, alta largura de banda (quando houver transferência).
A métrica definitiva é a latência de leitura de metadados. Ferramentas como o Prometheus com o zfs_exporter ou scripts baseados em eBPF podem extrair esses dados.
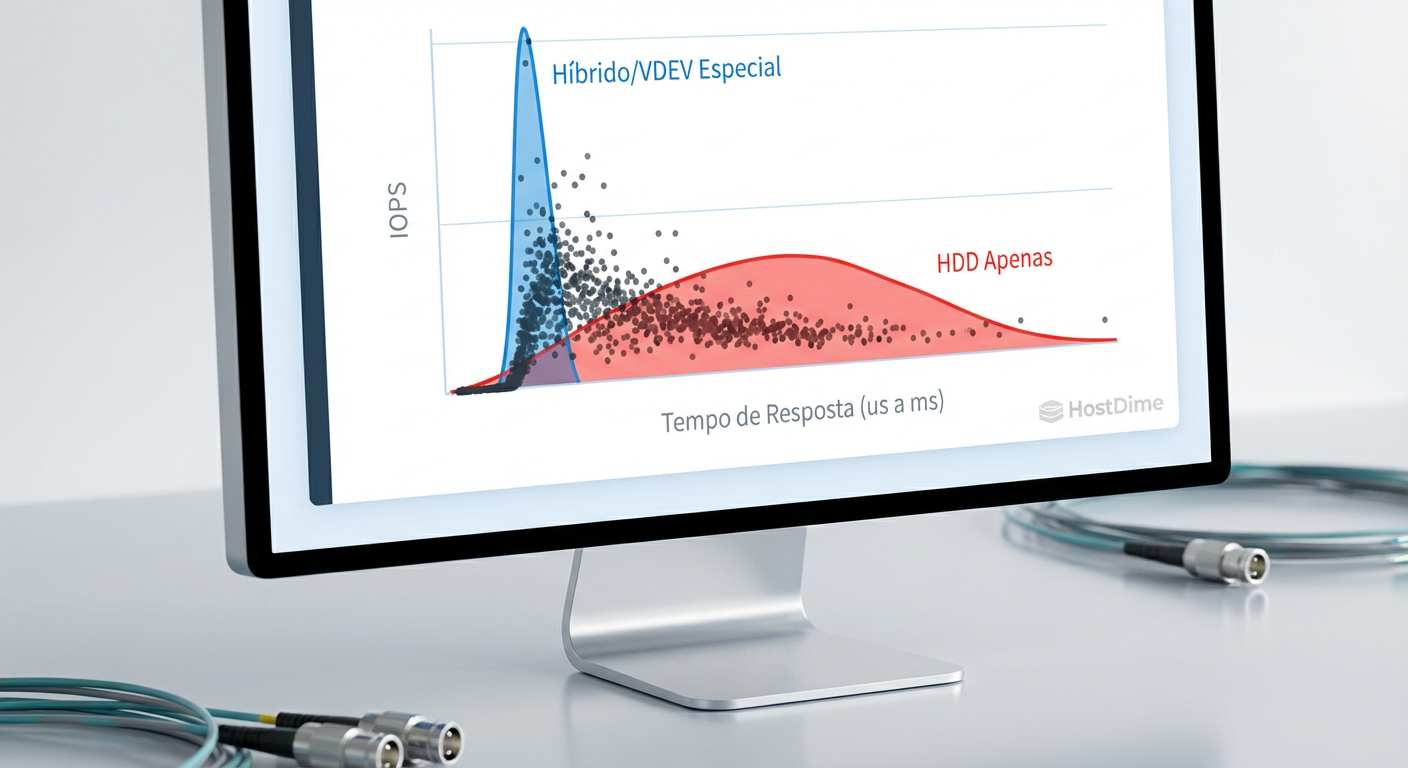 Fig 2. Comparativo de latência de leitura de metadados: HDD puro vs. Pool Híbrido.
Fig 2. Comparativo de latência de leitura de metadados: HDD puro vs. Pool Híbrido.
Na Figura 2, observamos o impacto real. O histograma azul (HDD puro) mostra uma cauda longa estendendo-se para 200ms+. O histograma laranja (Com Special VDEV) mostra 99% das operações completadas em menos de 1ms (latência de flash). Isso é a diferença entre um usuário reclamando que "o sistema travou" e uma operação imperceptível.
Recomendação Operacional
A introdução de Special VDEVs é a atualização de maior impacto para pools ZFS baseados em HDD na era moderna, superando qualquer ajuste de tunables ou adição de RAM. No entanto, ela eleva a complexidade da arquitetura e introduz novos pontos de falha.
Recomendamos esta implementação para qualquer cluster de armazenamento que exceda 100TB ou que tenha requisitos estritos de latência de listagem de arquivos. O custo adicional de dois ou três SSDs NVMe de classe Data Center é irrelevante comparado ao ganho de eficiência operacional e à extensão da vida útil dos HDDs, que deixam de ser martelados por buscas aleatórias.
Monitore a saúde desses SSDs agressivamente (wear leveling) e trate-os como os componentes mais críticos da sua infraestrutura.
Perguntas Frequentes
1. Posso remover um VDEV Especial depois de adicioná-lo? Depende da versão do ZFS e da configuração. No OpenZFS moderno, é possível remover se houver espaço suficiente nos HDDs para "esvaziar" os dados de volta para o pool principal. No entanto, é uma operação intensiva e arriscada. Planeje como se fosse permanente.
2. SSDs SATA são suficientes ou preciso de NVMe? Para metadados, a latência é tudo. SSDs SATA são muito melhores que HDDs, mas o protocolo NVMe reduz drasticamente a sobrecarga de CPU e latência de interface. Considerando os preços atuais em 2026, NVMe é a escolha padrão. Use SATA apenas se houver restrições físicas de portas no servidor.
3. O que acontece se o VDEV Especial encher?
O ZFS é inteligente. Se o special estiver cheio, ele voltará a escrever novos metadados nos HDDs (VDEVs normais). O sistema não para, mas a performance degradará para os novos dados gravados. Monitore a capacidade de perto.
Referências & Leitura Complementar
OpenZFS Documentation: Allocation Classes & Special VDEVs Feature Flags.
ZFS On Linux Man Pages:
man zpool-features(seçãoallocation_classes).Micron Technology: 9400 NVMe SSD Datasheet - Workload Characterization for Metadata.
RFC ZFS: Log Spacemap & Block Allocation Performance Improvements (2020).

Rafael Barros
Engenheiro de Confiabilidade (SRE)
"Transformo caos em estabilidade via observabilidade. Defensor da cultura blameless e focado em SLIs e SLOs. Se algo falhou, revisamos o sistema, nunca a pessoa."