Engenharia do Caos em Storage: Por que seu backup imutável provavelmente vai falhar

Imutabilidade não é mágica. Descubra como aplicar Engenharia do Caos para quebrar travas WORM, simular ransomware e validar se seus dados sobrevivem ao mundo real.
A imutabilidade tornou-se a palavra de segurança favorita da indústria de armazenamento de dados. Vendedores de SAN, NAS e soluções de backup vendem a ideia de "WORM" (Write Once, Read Many) como um escudo mágico contra ransomware. A premissa é sedutora: se os dados não podem ser alterados ou deletados por um período fixo, você está seguro. Certo? Errado.
Como engenheiros do caos, sabemos que sistemas complexos — e um ecossistema de storage moderno é extremamente complexo — falham de maneiras que os datasheets não preveem. A imutabilidade é apenas um atributo de software. Ela roda sobre hardware falível, depende de relógios de sistema sincronizados e obedece a regras de permissão que humanos configuram (e configuram mal). Acreditar que seu repositório Linux endurecido (Hardened Repository) ou seu bucket S3 com Object Lock vai salvar sua empresa sem nunca tê-lo submetido a um cenário de destruição controlada não é estratégia. É esperança. E esperança não restaura petabytes.
Resumo em 30 segundos
- Imutabilidade não é disponibilidade: Seus dados podem estar intactos, mas se o array de discos estiver saturado (IOPS starvation), o RTO (Tempo de Recuperação) será infinito.
- O tempo é vulnerável: Travas de retenção baseadas em datas (WORM) podem ser enganadas por ataques de NTP ou desvios de relógio de hardware, "envelhecendo" o bloqueio prematuramente.
- A falha humana persiste: Configuracões de "Governance Mode" em vez de "Compliance Mode" permitem que administradores (ou hackers com credenciais de admin) removam a proteção.
A falácia do "configure e esqueça"
A maioria das implementações de armazenamento imutável falha na camada 8 do modelo OSI: o ser humano. Existe uma distinção técnica crítica em sistemas de Object Storage (como MinIO, AWS S3 ou implementações Ceph) e appliances de backup dedicados: a diferença entre Modo de Governança e Modo de Conformidade.
No modo de governança, a imutabilidade existe, mas usuários com permissões especiais (como s3:BypassGovernanceRetention) podem sobrescrever ou deletar objetos bloqueados. É a configuração padrão em muitos ambientes porque os administradores de storage têm pavor de "bloquear algo errado" e encher o pool de discos com lixo eterno. O resultado? Um atacante que comprometa as credenciais de root ou do administrador de backup desliga a imutabilidade e apaga os volumes.
⚠️ Perigo: Se o seu repositório de backup "imutável" possui uma interface de gerenciamento (IPMI/iDRAC) acessível na mesma VLAN de produção, a imutabilidade lógica é irrelevante. Um comando de "Reinitialize RAID" ou "Secure Erase" no nível da controladora física ignora qualquer flag de software WORM.
Ataque 1: Viagem no tempo e deriva de NTP
A imutabilidade baseada em retenção temporal (ex: "proteger este snapshot por 30 dias") depende de uma única fonte de verdade: o relógio do sistema. Se o sistema de storage acredita que hoje é o ano de 2035, aquele bloqueio de 30 dias que você configurou ontem já expirou há muito tempo.
Em um cenário de Engenharia do Caos, testamos a resiliência do storage contra a manipulação do tempo (Time Travel). Vetores de ataque reais incluem o envenenamento de NTP (Network Time Protocol) ou acesso físico à BIOS do servidor de storage para alterar o RTC (Real Time Clock).
Muitos sistemas de arquivos modernos, como ZFS ou Btrfs, e softwares de Object Lock, possuem tolerâncias para desvios de tempo (clock skew), mas raramente são testados contra saltos agressivos. Se um atacante consegue avançar o relógio do seu servidor de backup, o daemon de limpeza (garbage collector) pode interpretar que os arquivos protegidos já cumpriram seu tempo de retenção e permitir sua exclusão.
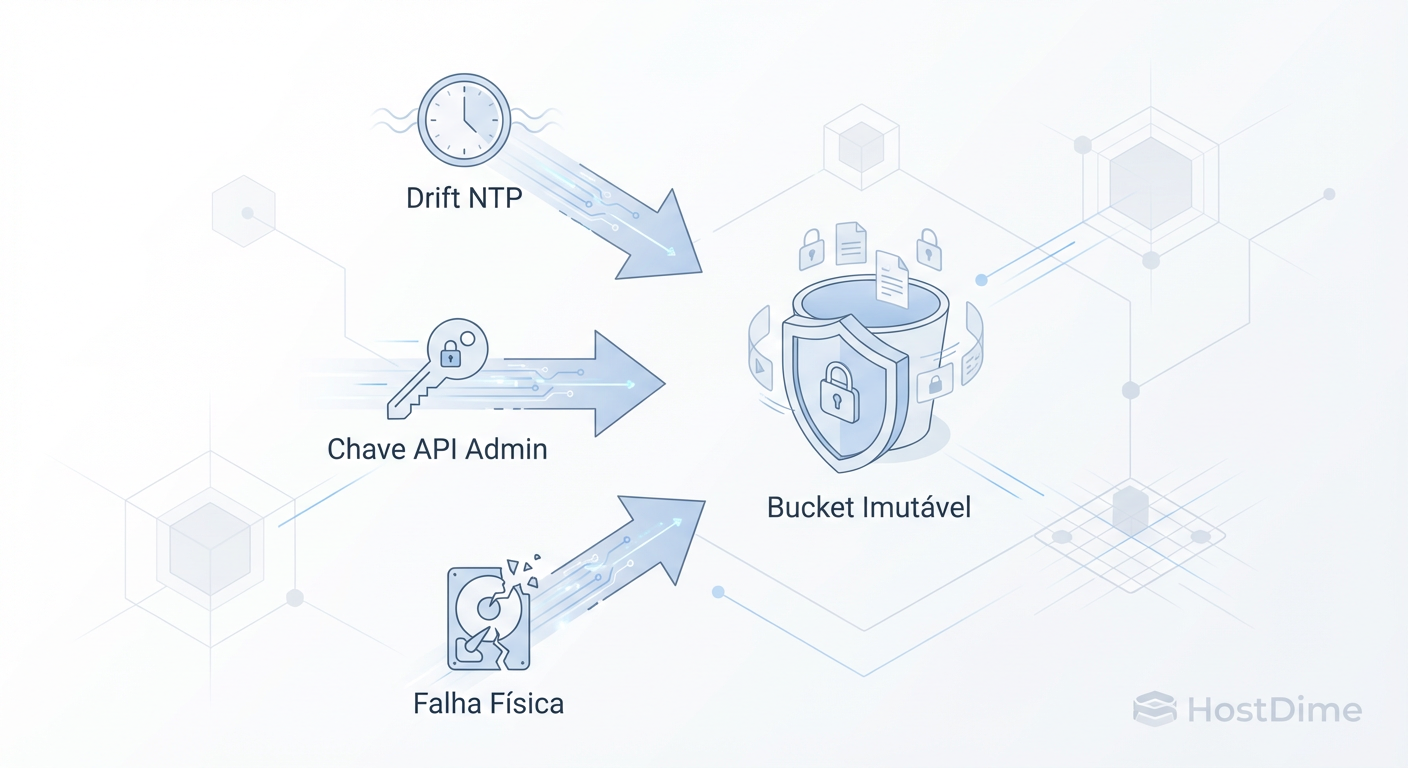 Fig. 1: Vetores de ataque lógicos e físicos que podem comprometer um backup teoricamente imutável.
Fig. 1: Vetores de ataque lógicos e físicos que podem comprometer um backup teoricamente imutável.
Experimento de caos sugerido
Não confie no vendor. Em um ambiente de laboratório (não em produção), isole seu servidor de armazenamento imutável da rede NTP externa. Injete uma data futura no sistema operacional. Tente deletar um arquivo WORM. Se o arquivo for deletado, sua "imutabilidade" é apenas um relógio glorificado.
Ataque 2: O teste de stress de IOPS
Este é o cenário onde a teoria da resiliência colide violentamente com a física dos discos rígidos e SSDs. Imagine que você tem um backup imutável perfeito. O ransomware atacou, criptografou a produção e agora você precisa restaurar 500 TB de dados críticos.
O problema? O ataque de ransomware não parou. O malware continua tentando criptografar arquivos, gerando uma carga massiva de IOPS (Input/Output Operations Per Second) e throughput na rede. Simultaneamente, você está tentando ler do backup e gravar no storage de produção.
Se o seu storage de backup utiliza discos mecânicos (HDD) de alta densidade (ex: 22TB NL-SAS) em RAID 6 ou RAIDZ2, o desempenho de leitura aleatória (random read) é pífio. Durante uma restauração, se houver qualquer outra atividade no pool (como tarefas de scrubbing, reconstrução de disco ou o próprio ataque persistente), a latência dispara.
💡 Dica Pro: O RTO (Recovery Time Objective) calculado no papel assume um sistema ocioso. Em um GameDay, sature o link de rede e a fila de disco com ferramentas como
fioouvdbenchenquanto tenta realizar um restore. Você descobrirá que seu restore de 4 horas pode levar 4 dias.
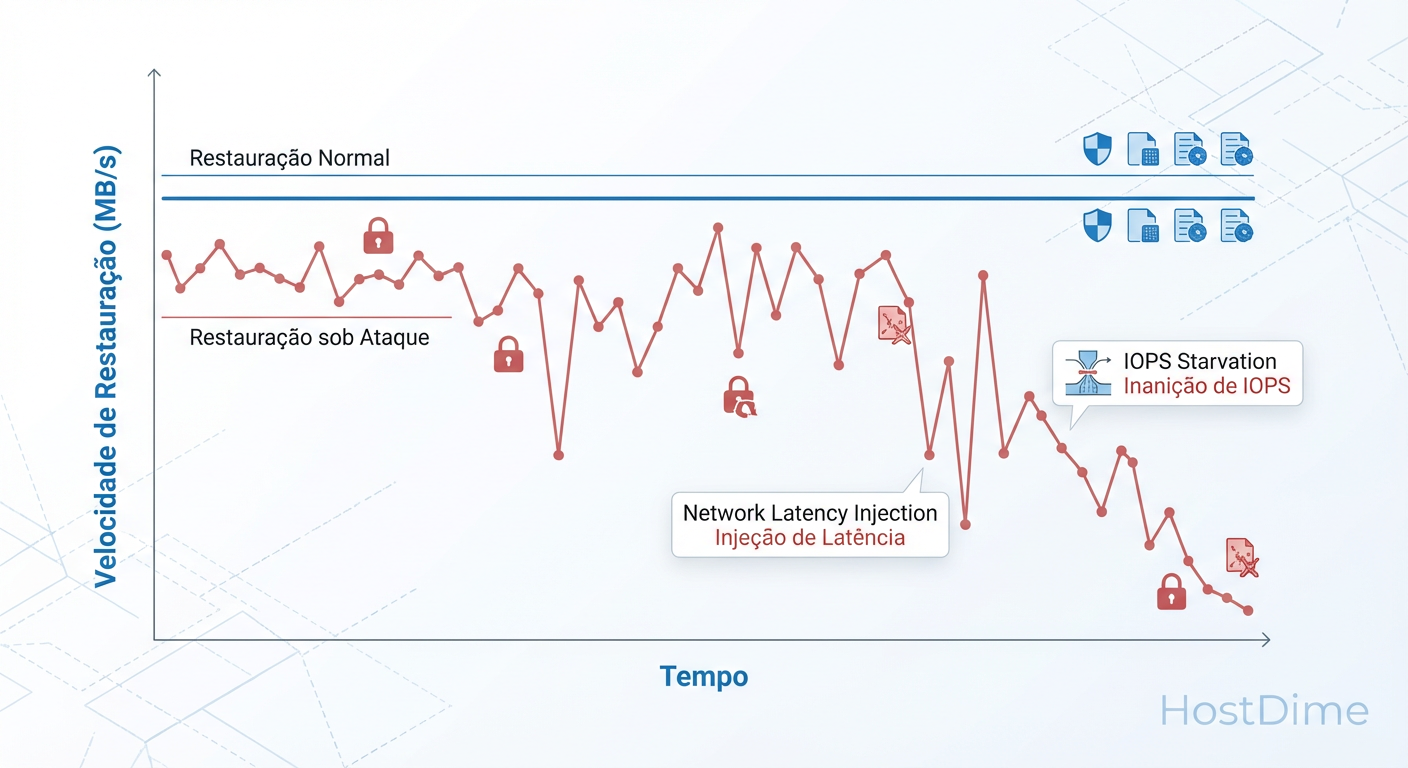 Fig. 2: O impacto invisível. Como a saturação de IOPS (vizinho barulhento ou criptografia em andamento) pode tornar seu RTO inalcançável.
Fig. 2: O impacto invisível. Como a saturação de IOPS (vizinho barulhento ou criptografia em andamento) pode tornar seu RTO inalcançável.
A criptografia em massa gera um padrão de escrita sequencial ou aleatória agressiva, dependendo do malware. Se o seu storage de destino (onde os dados estão sendo restaurados) não tiver QoS (Quality of Service) para priorizar o tráfego de restore sobre o tráfego de "ruído", o sistema trava. Imutabilidade sem performance de recuperação é apenas um arquivo morto inacessível.
Ataque 3: A ilusão da governança e delete markers
Em arquiteturas de nuvem híbrida ou storage compatível com S3 on-premise, a imutabilidade frequentemente falha devido a nuances de versionamento. Quando você deleta um objeto em um bucket com versionamento ativado, o sistema não apaga os dados; ele insere um "Delete Marker" (marcador de exclusão) como a versão mais recente.
Para a aplicação que consome esses dados, o arquivo sumiu (erro 404). Os dados ainda estão lá, protegidos pela imutabilidade nas versões anteriores, mas o serviço parou. O tempo para remover milhões de Delete Markers via API pode ser proibitivo.
Além disso, atacantes astutos não tentam deletar os dados. Eles alteram as políticas de Ciclo de Vida (Lifecycle Policies). Imagine uma regra injetada que move todos os seus dados "imutáveis" para uma camada de arquivamento frio (como Glacier Deep Archive ou fitas virtuais) com tempo de recuperação de 12 a 48 horas. Os dados não foram deletados, mas tornaram-se inutilizáveis para a continuidade de negócios imediata. Isso é negação de serviço através de tiering.
GameDay de storage: O framework
Não espere o incidente para descobrir essas falhas. A Engenharia do Caos propõe a execução de "GameDays" — dias dedicados a quebrar coisas propositalmente. Para storage, o framework deve ser rígido para evitar perda real de dados.
Defina o Raio de Explosão (Blast Radius): Nunca comece testando no pool principal de produção. Crie um pool isolado ou um bucket específico que espelhe as configurações de produção.
Estabeleça a Hipótese: "Se eu cortar a conexão NTP e adiantar o relógio em 1 ano, o bloqueio WORM deve persistir e impedir a deleção."
Execute o Experimento: Use scripts automatizados. Tente deletar, tente sobrescrever, tente mudar as permissões de ACL.
Meça o Impacto: O sistema permitiu a ação? Ocorreu corrupção silenciosa? O sistema de monitoramento (Zabbix, Prometheus) alertou sobre a tentativa de violação?
Exemplo de injeção de falha
Use ferramentas nativas para simular degradação. No Linux (para servidores de storage baseados em ZFS/MDADM), use o tc (Traffic Control) para injetar latência de rede ou perda de pacotes na interface iSCSI/NFS durante um restore de teste.
tc qdisc add dev eth0 root netem delay 200ms
Observe como seu software de backup lida com isso. Ele timeout? Ele corrompe o índice? Ele continua, mas a uma velocidade inaceitável?
O alerta final
A indústria de storage vende caixas pretas com promessas de invencibilidade. A função do Engenheiro do Caos é abrir essas caixas e expor as engrenagens frágeis. Se o seu backup imutável nunca enfrentou um relógio desajustado, uma credencial de root comprometida ou um disco saturado por IOPS, ele não é uma estratégia de recuperação de desastres. É uma bomba-relógio.
A resiliência não vem da compra de hardware mais caro ou de licenças de software "Enterprise Plus". Ela vem da prática contínua de tentar destruir sua própria infraestrutura antes que um adversário o faça. Teste seus bloqueios. Desafie seus relógios. Sature seus discos. Só então você poderá dizer que seus dados são, de fato, imutáveis.
Referências & Leitura Complementar
NIST SP 800-209: Security Guidelines for Storage Infrastructure. Um guia fundamental para entender a superfície de ataque em nível de bloco e objeto.
AWS S3 Object Lock Consistency Model: Documentação técnica sobre como o modelo de consistência eventual interage com travas de retenção.
Veeam Hardened Repository RFCs: Especificações técnicas sobre como repositórios Linux imutáveis gerenciam flags de imutabilidade (
chattr +i) e a separação de credenciais.Principles of Chaos Engineering: O manifesto original (principlesofchaos.org), aplicado aqui ao contexto de infraestrutura de dados.
Perguntas Frequentes
1. Snapshots ZFS são considerados backups imutáveis?
Snapshots são excelentes para recuperação rápida, e quando configurados como read-only e replicados para um segundo host com credenciais diferentes, oferecem alto nível de proteção. No entanto, se o atacante tiver acesso root ao sistema operacional do host ZFS, ele pode destruir o zpool inteiro (zpool destroy), levando os snapshots junto. A verdadeira imutabilidade exige separação física e lógica de gerenciamento.
2. Fitas LTO ainda são relevantes nesse cenário? Absolutamente. Fitas LTO oferecem "Air Gap" físico real. Um hacker não pode deletar dados de uma fita que está em uma caixa em outro prédio. A desvantagem é o RTO (tempo de recuperação) elevado devido à natureza sequencial da fita e à necessidade de robótica ou manuseio manual.
3. Com que frequência devo rodar testes de caos em storage? Recomenda-se rodar testes automatizados de integridade (como validação de checksums e tentativas de deleção não autorizada) semanalmente. GameDays completos, envolvendo simulação de falha de hardware e manipulação de tempo, devem ser trimestrais ou semestrais.

Magnus Vance
Engenheiro do Caos
"Quebro sistemas propositalmente porque a falha é inevitável. Transformo desastres simulados em vacinas para sua infraestrutura. Se não sobrevive ao meu caos, não merece estar em produção."