Erasure Coding vs RAID: A Verdade Sobre Integridade e Performance em Storage

Descubra quando o Erasure Coding supera o RAID e quando a latência torna o RAID (especialmente ZFS RAIDZ) a escolha superior. Uma análise profunda de arquitetura de dados.
O disco rígido mente. O SSD engana. O controlador de armazenamento omite a verdade. Se há uma lição que aprendi após décadas depurando kernel panics e analisando despejos hexadecimais de sistemas de arquivos corrompidos, é esta: seus dados estão em constante estado de decaimento. A entropia não perdoa bits magnéticos nem células NAND.
Como arquitetos de sistemas e guardiões da integridade dos dados, nossa única defesa contra o caos é a redundância matemática. Durante anos, o RAID (Redundant Array of Independent Disks) foi o padrão ouro. Mas, com o crescimento exponencial dos volumes de dados (Petabytes são o novo Terabyte), o RAID tradicional começou a mostrar fissuras estruturais. Entra em cena o Erasure Coding (EC).
Não se engane: esta não é uma batalha de popularidade. É uma escolha fundamental sobre como a matemática protege seus bits. Vamos dissecar a arquitetura, a mecânica no disco e a realidade brutal da recuperação de desastres entre essas duas tecnologias.
Arquitetura de Redundância: Do RAID 1 ao Reed-Solomon
Para entender para onde vamos, precisamos entender as limitações de onde estivemos. A redundância de armazenamento existe em um espectro que equilibra três pilares: Custo de Capacidade, Performance de I/O e Probabilidade de Perda de Dados.
A Simplicidade Bruta do Espelhamento (RAID 1/10)
No extremo esquerdo do espectro, temos o espelhamento. O conceito é trivial: $A = B$. Se eu escrevo um bloco no disco 1, escrevo o mesmo bloco no disco 2.
Vantagem: A leitura é rápida (pode vir de qualquer cópia) e a penalidade de escrita é mínima (apenas a latência do disco mais lento). A reconstrução é apenas uma cópia sequencial.
O Problema: A eficiência espacial é atroz (50%). Para armazenar 1 PB, você compra 2 PB. Em escala, isso quebra qualquer orçamento de TI.
A Evolução da Paridade (RAID 5/6 e RAIDZ)
Para resolver o custo, inventamos a paridade. Em vez de copiar os dados, calculamos uma soma de verificação. No RAID 5, usamos XOR. Se $A \oplus B = P$, e perdemos $A$, podemos recuperar $A$ fazendo $P \oplus B$. O ZFS evoluiu isso com o RAIDZ, que resolve o problema do "buraco de escrita" (write hole) do RAID tradicional integrando a paridade ao sistema transacional de Copy-on-Write (CoW). O RAIDZ2 (semelhante ao RAID 6) usa dois blocos de paridade, permitindo a falha de dois discos quaisquer.
O Salto para Erasure Coding
O Erasure Coding é a generalização matemática do RAID. Enquanto o RAID 6 é essencialmente um EC com parâmetros fixos ($N+2$), o Erasure Coding moderno permite definir arbitrariamente $k$ fragmentos de dados e $m$ fragmentos de codificação. Isso nos permite esquemas como $10+4$ (dividir o objeto em 10 pedaços, criar 4 de paridade), suportando a perda de quaisquer 4 discos (ou nós inteiros) com uma eficiência de armazenamento muito superior ao espelhamento.
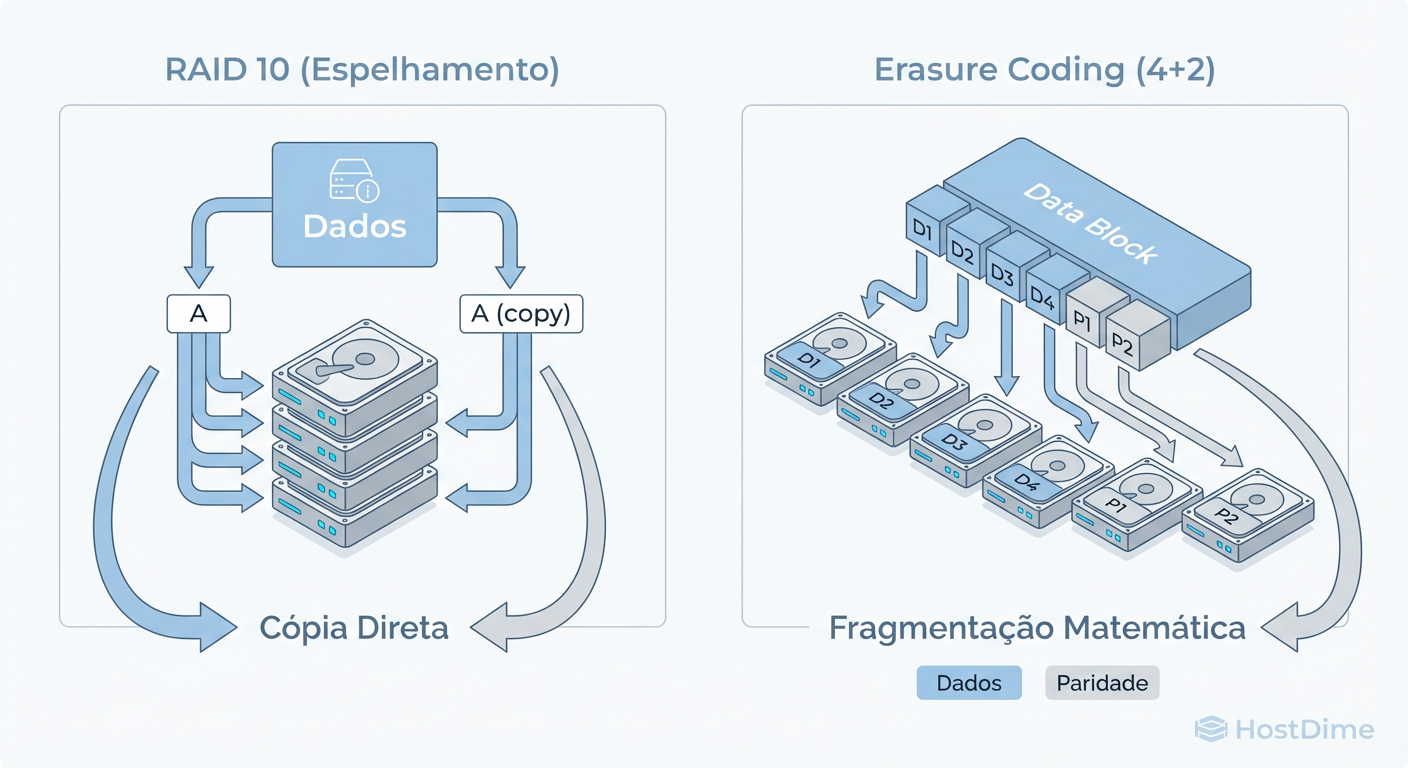 Figura: Fig. 1: A diferença fundamental de alocação: A simplicidade do Espelhamento vs. a Eficiência Algorítmica do Erasure Coding.
Figura: Fig. 1: A diferença fundamental de alocação: A simplicidade do Espelhamento vs. a Eficiência Algorítmica do Erasure Coding.
A diferença fundamental ilustrada acima é a granularidade. O RAID tradicional opera no nível do volume ou disco físico. O Erasure Coding, especialmente em sistemas distribuídos (como Ceph ou MinIO) e implementações modernas de ZFS (dRAID), opera frequentemente no nível do objeto ou do chunk, distribuindo a matemática através de uma topologia de rede, não apenas cabos SAS/SATA.
Matemática no Disco: Reed-Solomon e a Paridade do ZFS
Aqui é onde a mágica acontece. Não basta dizer "tem paridade". Precisamos entender como os bits aterrissam no prato do disco. A integridade dos dados depende da robustez dessa matemática.
A Elegância dos Campos de Galois
Tanto o RAIDZ2/Z3 quanto o Erasure Coding baseiam-se na matemática de Reed-Solomon. Não usamos aritmética simples de inteiros; operamos em um Campo Finito (ou Campo de Galois), especificamente $GF(2^8)$.
Por que isso importa? Porque em $GF(2^8)$, todas as operações de adição, subtração, multiplicação e divisão (exceto por zero) resultam em outro elemento dentro do campo (0-255). Isso significa que podemos realizar operações complexas em bytes sem nunca causar overflow.
Quando o ZFS escreve uma faixa (stripe) de RAIDZ2:
Ele pega os blocos de dados variáveis.
Calcula a paridade $P$ (XOR simples).
Calcula a paridade $Q$ usando coeficientes do Campo de Galois ($A \cdot x^0 + B \cdot x^1...$).
Grava tudo atomicamente como parte de um Transaction Group (TXG).
O Custo Computacional Oculto
No Erasure Coding, a complexidade aumenta. Se configurarmos um esquema $8+3$ (8 dados, 3 paridades), o processador deve resolver equações polinomiais para gerar esses 3 fragmentos. Ao ler, se os dados estiverem intactos, é apenas leitura. Mas se houver perda, a CPU deve interpolar o polinômio para regenerar os dados faltantes em tempo real.
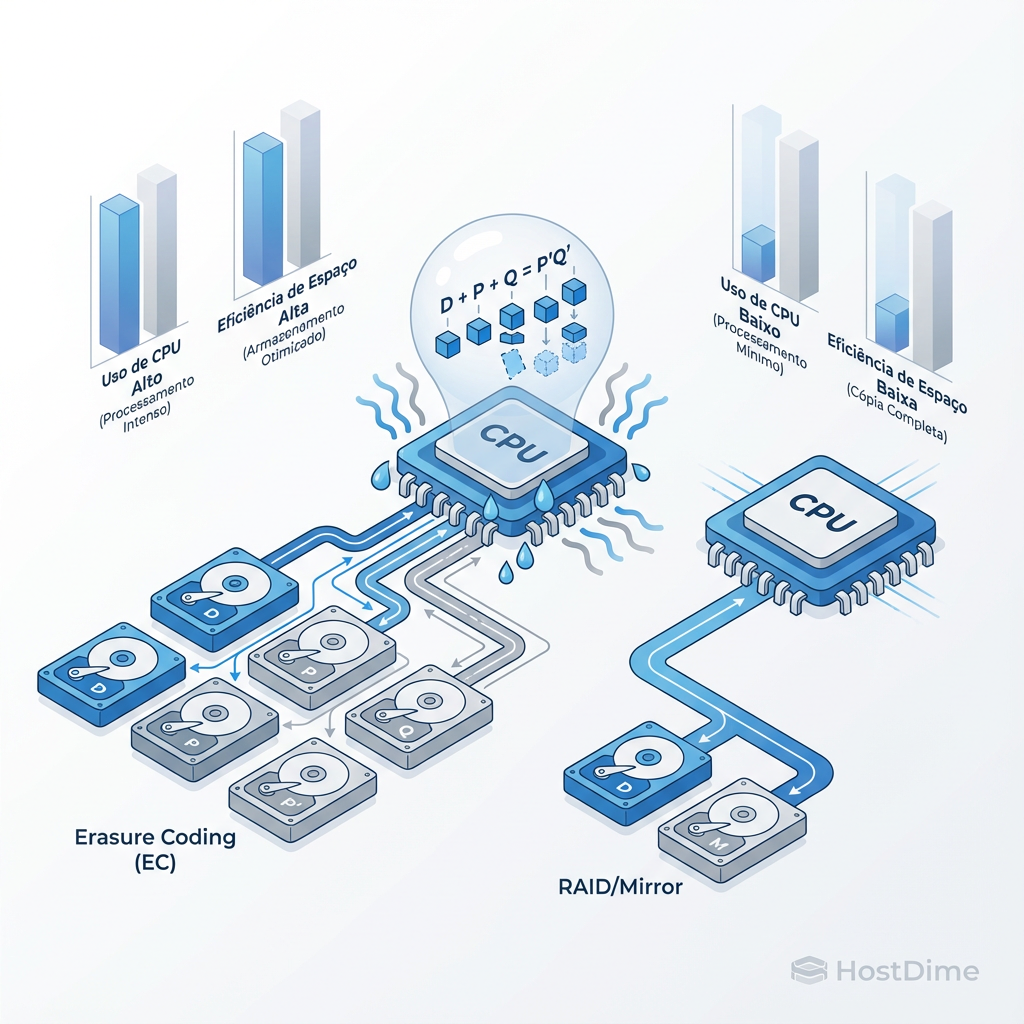 Figura: Fig. 2: O Trade-off Inevitável: Onde você paga a conta? No processador (EC) ou na capacidade bruta de disco (RAID).
Figura: Fig. 2: O Trade-off Inevitável: Onde você paga a conta? No processador (EC) ou na capacidade bruta de disco (RAID).
Como vemos na figura acima, há um trade-off inevitável. O RAID (espelhamento) consome espaço em disco, mas poupa a CPU. O Erasure Coding economiza espaço em disco, mas cobra o "imposto" na CPU. Em sistemas antigos, o cálculo de Reed-Solomon era um gargalo. Hoje, com instruções AVX2 e aceleração de hardware, esse custo é trivial para a maioria dos workloads, exceto os de latência ultra-baixa.
O Problema da Geometria e ashift
Um detalhe que vejo muitos administradores ignorarem é o alinhamento físico. Discos modernos mentem sobre o tamanho do setor (reportam 512 bytes, mas usam 4K internamente).
No ZFS e em sistemas de EC, se você não alinhar suas escritas (propriedade ashift=12 no ZFS para setores de 4K), você incorre em uma penalidade de "Read-Modify-Write".
No RAIDZ: Uma escrita parcial força o sistema a ler o resto da faixa, recalcular a paridade e escrever tudo de novo.
No EC: É ainda pior. Escrever um pequeno arquivo de 4KB num esquema que espera chunks de 1MB obriga o sistema a ler os blocos vizinhos ou usar padding excessivo, destruindo a eficiência que o EC prometia.
Implementação Prática: Configurando ZFS RAIDZ e Erasure Coding
A teoria é bela, mas precisamos digitar comandos. Abaixo, comparo a criação de um pool resiliente em ZFS (RAIDZ2) com a definição de um perfil de Erasure Coding (conceitual, aplicado a sistemas como MinIO ou Ceph, já que o dRAID do OpenZFS ainda está em maturação para o público geral).
1. ZFS: A Abordagem Robusta Local
Ao criar um pool ZFS, você está definindo a topologia imutável do vdev (na maioria das versões atuais).
# Criação de um pool RAIDZ2 (Tolerância a falha de 2 discos)
# ashift=12 garante alinhamento de 4K (crucial para performance)
zpool create -o ashift=12 tank raidz2 \
/dev/disk/by-id/wwn-0x5000cca03c0a1 \
/dev/disk/by-id/wwn-0x5000cca03c0a2 \
/dev/disk/by-id/wwn-0x5000cca03c0a3 \
/dev/disk/by-id/wwn-0x5000cca03c0a4 \
/dev/disk/by-id/wwn-0x5000cca03c0a5 \
/dev/disk/by-id/wwn-0x5000cca03c0a6
# Verificando o status e a integridade
zpool status -v
O que observar: O ZFS distribui os dados dinamicamente. Diferente do RAID 5 hardware, o tamanho da faixa (stripe width) no RAIDZ é variável. Isso significa que ele comprime e aloca apenas o necessário, evitando o desperdício de espaço com padding em arquivos pequenos.
2. Erasure Coding: A Abordagem Definida por Software
Em sistemas de armazenamento de objetos, você define o EC via perfis ou classes de armazenamento.
# Exemplo conceitual (Sintaxe genérica de CLI de Storage Distribuído)
# Definindo um perfil EC 4+2 (4 dados, 2 paridades)
storage-cli profile create my-ec-profile \
--data-chunks 4 \
--parity-chunks 2 \
--algorithm reed-solomon-vanilla
# Aplicando ao bucket/pool
storage-cli bucket create archive-data --profile my-ec-profile
A Diferença Crucial: No ZFS RAIDZ, a paridade está atrelada aos discos físicos daquele vdev. No EC distribuído, os chunks são espalhados por nós diferentes na rede. Se um nó cai, o EC reconstrói os dados lendo de outros nós via rede. Isso introduz latência de rede na equação de integridade.
Desmistificando Armazenamento: A Falácia do "RAID Morreu" e o Custo de CPU
Existem muitos mitos perigosos circulando em blogs de tecnologia. Vamos derrubar os dois maiores.
Mito 1: "RAID Morreu, viva o Erasure Coding"
Ouço isso constantemente. É falso. O RAID (especificamente RAID 10 e RAIDZ) ainda é o rei para Workloads de Baixa Latência e Random I/O. O Erasure Coding tem um custo de amplificação de escrita e latência de reconstrução. Se você está rodando um banco de dados transacional (PostgreSQL, MySQL) com muitas escritas pequenas e aleatórias, o Erasure Coding vai destruir sua performance devido ao overhead de cálculo e fragmentação.
Use RAID/Mirroring para: Máquinas Virtuais, Bancos de Dados, Boot drives.
Use EC/RAIDZ para: Backups, Mídia, Data Lakes, Arquivos imutáveis.
Mito 2: "Erasure Coding é Gratuito"
A eficiência de espaço do EC (conseguir 80% de utilização útil vs 50% do RAID 10) vem com um custo: Latência. Toda vez que você lê um dado, o sistema deve montar os fragmentos. Se houver degradação (um disco lento ou falho), o sistema precisa calcular matematicamente os dados faltantes em tempo real. Isso cria "latência de cauda" (tail latency).
Comparativo Técnico de Sobrecarga
| Característica | RAID 10 (Mirror Stripe) | RAIDZ2 (ZFS Parity) | Erasure Coding (4+2 Distribuído) |
|---|---|---|---|
| Eficiência de Espaço | 50% | ~66-80% (dep. largura) | 66% |
| Custo de CPU na Escrita | Quase Zero | Médio (Checksum + Parity) | Alto (Hash + Reed-Solomon) |
| Performance Random I/O | Excelente | Bom (limitado por IOPS do vdev) | Ruim (Amplificação de escrita) |
| Tempo de Reconstrução | Rápido (Cópia 1:1) | Lento (Varre metadados) | Variável (Depende da Rede) |
Cenário de Desastre: Resilvering, Rebalanceamento e Reconstrução
Aqui é onde o arquiteto ganha seu salário. Tudo funciona bem quando as luzes estão verdes. Mas o que acontece quando um disco de 18TB morre?
O Pesadelo do URE (Unrecoverable Read Error)
No RAID tradicional (hardware), reconstruir um array RAID 5 de discos grandes é roleta russa. A probabilidade matemática de encontrar um erro de leitura (URE) no disco restante durante a reconstrução é estatisticamente alta. Se isso acontece, o controlador RAID tradicional falha o array inteiro. Adeus dados.
O ZFS e sistemas de EC modernos não falham o array inteiro. Graças ao Checksumming Hierárquico (Merkle Tree), se o ZFS encontra um bloco corrompido durante o resilvering (reconstrução), ele marca apenas aquele arquivo como corrompido, salvando o resto do pool. Ele sabe exatamente quais dados são válidos.
Reconstrução: Local vs. Distribuída
Aqui reside a maior vantagem arquitetural do Erasure Coding distribuído sobre o RAID local.
No RAID tradicional (e até no RAIDZ local), se um disco falha, o disco "hot spare" torna-se o gargalo de escrita. Todos os discos sobreviventes leem freneticamente para escrever naquele único disco novo. A velocidade de reconstrução é limitada pela velocidade de escrita de um drive.
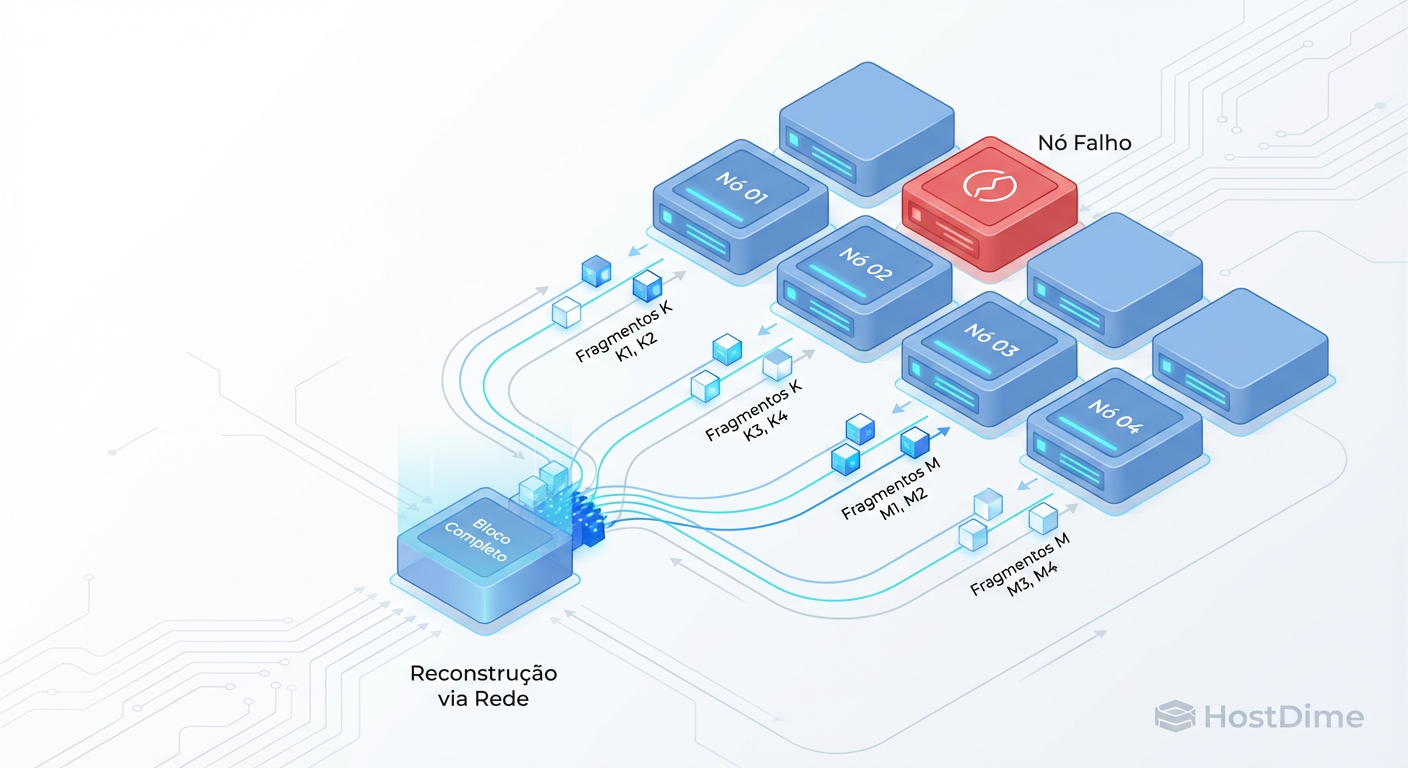 Figura: Fig. 3: A Reconstrução Distribuída. Ao contrário do RAID tradicional que estressa um único disco par, o EC distribuído utiliza a largura de banda de todo o cluster.
Figura: Fig. 3: A Reconstrução Distribuída. Ao contrário do RAID tradicional que estressa um único disco par, o EC distribuído utiliza a largura de banda de todo o cluster.
No Erasure Coding Distribuído (como mostrado na Fig. 3), a reconstrução é Muitos-para-Muitos. Quando um drive morre, os dados que estavam nele são reconstruídos e espalhados por todos os outros drives/nós restantes no cluster. Não há um único disco de destino. A largura de banda de reconstrução é a soma da largura de banda de todo o cluster.
- Resultado: Um cluster Ceph bem dimensionado pode recuperar um drive de 10TB em minutos, enquanto um RAID tradicional levaria dias (deixando você vulnerável a uma segunda falha durante esse tempo).
O Processo de Resilvering do ZFS
O ZFS melhorou isso com o Sequential Resilver (nos OpenZFS mais novos). Em vez de varrer a árvore de blocos aleatoriamente, ele ordena os blocos para minimizar o movimento da cabeça do disco. Isso trouxe o RAIDZ de volta à competição em termos de tempo de reconstrução, mas ainda é limitado pela física do disco local.
Veredito do Arquiteto: Escolhendo a Ferramenta Certa para o Workload
Não existe "melhor". Existe o adequado. Como alguém que já viu empresas perderem dados por escolherem a tecnologia da moda em vez da tecnologia correta, aqui está meu guia de decisão:
Integridade é inegociável: Seja RAIDZ ou EC, você precisa de um sistema que faça checksum de dados e metadados (como ZFS ou Btrfs). RAID de hardware sem checksum é negligência profissional em 2024. O bit rot é real.
Onde usar ZFS RAIDZ (1/2/3):
- Servidores de arquivos locais ("Big Iron").
- Workloads que exigem alta integridade e simplicidade de gestão.
- Cenários onde a latência de rede do armazenamento distribuído é inaceitável.
- Regra de Ouro: Use RAIDZ2 no mínimo. RAIDZ1 (paridade simples) é arriscado demais com discos grandes.
Onde usar Erasure Coding (Ceph/MinIO):
- Armazenamento de Objetos (S3) em escala de Petabytes.
- Sistemas onde a tolerância a falhas deve ser no nível do Node ou Rack, não apenas do disco.
- Arquivamento de longo prazo (Cold Storage).
Onde usar Espelhamento (RAID 10):
- Bancos de dados de alta performance.
- Discos de boot e sistemas operacionais.
- Qualquer lugar onde IOPS aleatórios (Random I/O) sejam o KPI principal.
O Erasure Coding é o futuro da escala, mas o RAID (inteligentemente implementado via ZFS) continua sendo o guardião da performance local. Escolha baseado na física e na matemática, não no marketing. E lembre-se: RAID não é backup. Replicação não é backup. Snapshots locais não são backup. Backup é ter seus dados em outro lugar, preferencialmente imutável, longe do alcance da entropia do seu sistema principal.
Referências Técnicas
Bonwick, J., & Ahrens, M. (2005). ZFS: The Last Word in File Systems. Sun Microsystems. (O paper seminal sobre a arquitetura do ZFS).
Plank, J. S. (1997). A Tutorial on Reed-Solomon Coding for Fault-Tolerance in RAID-like Systems. University of Tennessee. (A base matemática para EC).
OpenZFS Documentation. RAIDZ vs Mirroring Performance Analysis.
Ceph Documentation. Erasure Coding Profiles and Data Durability.
Lucas, M. W., & Jude, A. (2016). FreeBSD Mastery: ZFS. Tilted Windmill Press. (Leitura obrigatória para operadores).

Viktor Kovac
Investigador de Incidentes de Segurança
"Não busco apenas o invasor, mas a falha silenciosa. Rastreio vetores de ataque, preservo a cadeia de custódia e disseco logs até que a verdade digital emerja das sombras."