Erasure Coding vs. Replicação: A Armadilha de Performance em Clusters Pequenos

Erasure Coding economiza disco, mas cobra caro em latência e CPU. Entenda a matemática do overhead, os riscos de rebuild e por que clusters pequenos devem evitar EC.
Todo arquiteto de storage enfrenta, mais cedo ou mais tarde, o conflito entre o departamento financeiro e a engenharia. A planilha de custos aponta que o Erasure Coding (EC) oferece 1.5x a 1.7x mais capacidade útil pelo mesmo preço de hardware. A engenharia, por outro lado, teme a latência.
Em clusters de escala petabyte (como S3 ou Backblaze), o Erasure Coding é mandatório. Mas em clusters pequenos (3 a 5 nós) rodando workloads mistos ou de alta performance (bancos de dados, VMs), a economia de disco do EC é frequentemente paga com a moeda mais cara do data center: a latência de I/O e a instabilidade operacional.
Neste artigo, vamos dissecar a física por trás dessa troca, medir o impacto real e definir quando a matemática da redundância joga contra você.
O que é Erasure Coding e Replicação?
Erasure Coding (EC) é um método de proteção de dados que divide a informação em fragmentos ($k$) e cria paridades calculadas ($m$), permitindo recuperar dados perdidos via matemática, otimizando espaço (ex: 1.5x overhead). Replicação é a cópia exata dos dados em múltiplos discos ou nós (ex: 3x overhead), priorizando a velocidade de recuperação e baixa latência de escrita em detrimento da eficiência de armazenamento.
A Ilusão da Economia: O Custo Oculto do Modelo k+m
Para entender o problema de performance, precisamos primeiro desmontar a matemática de proteção.
Na Replicação (Ex: 3 Réplicas), a lógica é binária e simples. Se você grava um bloco A, o sistema grava A no nó 1, A no nó 2 e A no nó 3.
Eficiência: 33% (1TB útil custa 3TB físicos).
Custo Computacional: Quase zero. É um fluxo de bytes direto.
No Erasure Coding (Ex: 4+2), o dado é fatiado. O sistema pega o bloco, divide em 4 pedaços de dados ($k$) e calcula 2 pedaços de paridade ($m$).
Eficiência: 66% (1TB útil custa 1.5TB físicos).
Custo Computacional: Alto. Exige cálculo de álgebra linear (frequentemente Reed-Solomon) para cada operação de escrita.
O erro comum é olhar apenas para a eficiência de armazenamento (o "CapEx"). O problema real surge quando o workload não é sequencial, mas sim aleatório e pequeno, o que nos leva ao pesadelo da amplificação de escrita.
O Ciclo Read-Modify-Write: Por que a Latência Explode no Erasure Coding
A maior armadilha de performance em storage distribuído (seja Ceph, MinIO ou vSAN) é tratar EC como se fosse RAID 5/6 tradicional, ignorando a penalidade de rede.
O Erasure Coding funciona bem quando você escreve "stripes" (faixas) completas. Se o seu esquema é 4+2 e você grava um arquivo grande que preenche exatamente os 4 blocos de dados, o sistema calcula a paridade em memória e descarrega tudo para os discos de uma vez. O throughput é alto.
Porém, bancos de dados e sistemas de virtualização raramente fazem isso. Eles fazem escritas aleatórias pequenas (4k, 8k, 16k). Quando você altera apenas alguns bytes de uma faixa existente, ocorre o fenômeno Read-Modify-Write (RMW).
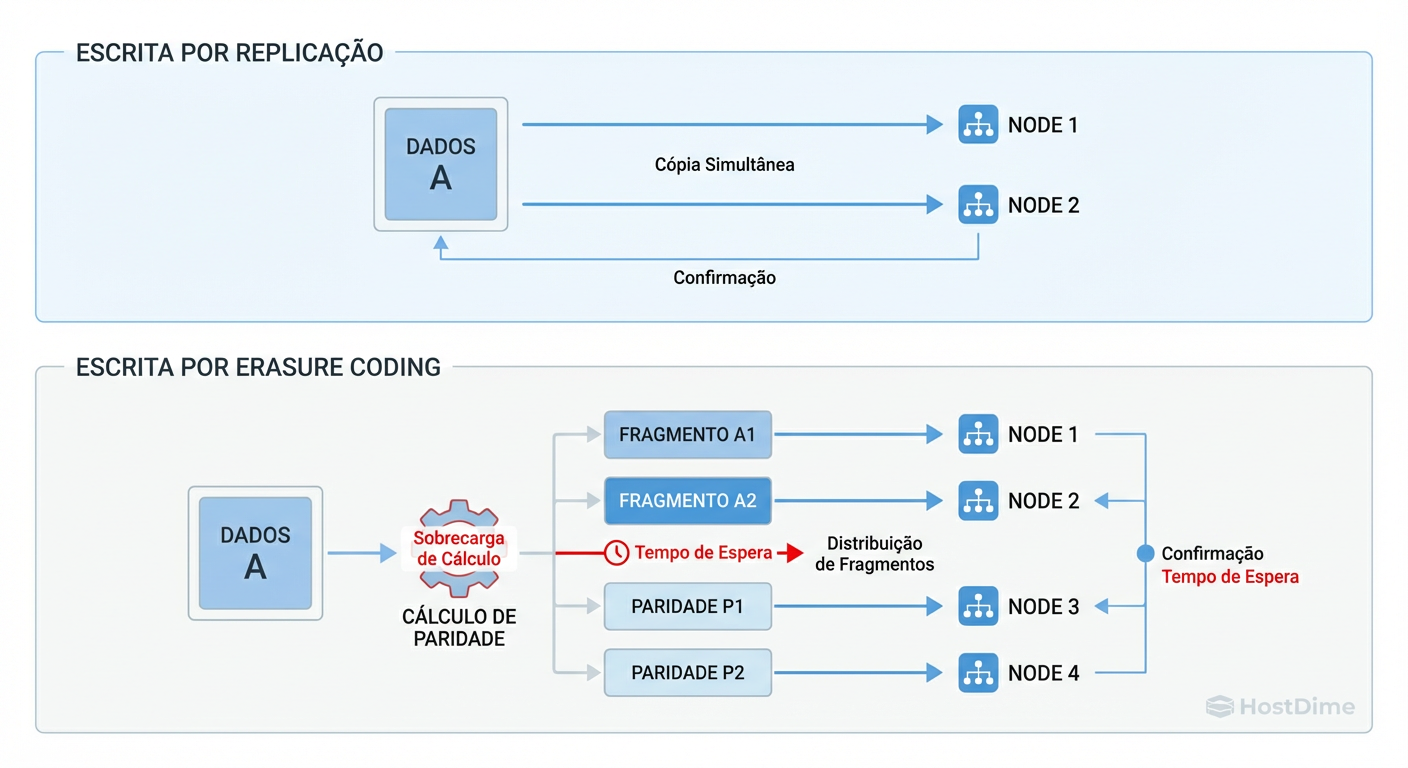 Figura: A Penalidade de Escrita: Enquanto a replicação é um espelhamento simples, o Erasure Coding exige cálculo e distribuição complexa, gerando latência.
Figura: A Penalidade de Escrita: Enquanto a replicação é um espelhamento simples, o Erasure Coding exige cálculo e distribuição complexa, gerando latência.
Para modificar um pequeno pedaço de dado em um esquema EC, o storage não pode simplesmente sobrescrever o bloco. Ele precisa:
Ler o dado antigo do disco.
Ler a paridade antiga do disco (frequentemente em outro nó).
Calcular a diferença (XOR/Álgebra) para gerar a nova paridade.
Escrever o novo dado.
Escrever a nova paridade.
O que seria 1 IOPS na replicação transforma-se em múltiplas operações de leitura e escrita, somadas à latência de CPU para o cálculo. Em clusters pequenos, onde a latência de cauda (p99) é crítica, isso destrói a performance percebida pela aplicação.
Amplificação de Rede: O Gargalo Esquecido na Nuvem Privada
Engenheiros de performance iniciantes olham para o disco (iostat). Engenheiros experientes olham para o switch.
No cenário de Read-Modify-Write descrito acima, o tráfego não fica confinado ao barramento PCIe do servidor. Como o Erasure Coding distribui fragmentos e paridade entre diferentes nós para garantir resiliência (Failure Domains), a operação de leitura e escrita de paridade atravessa a rede.
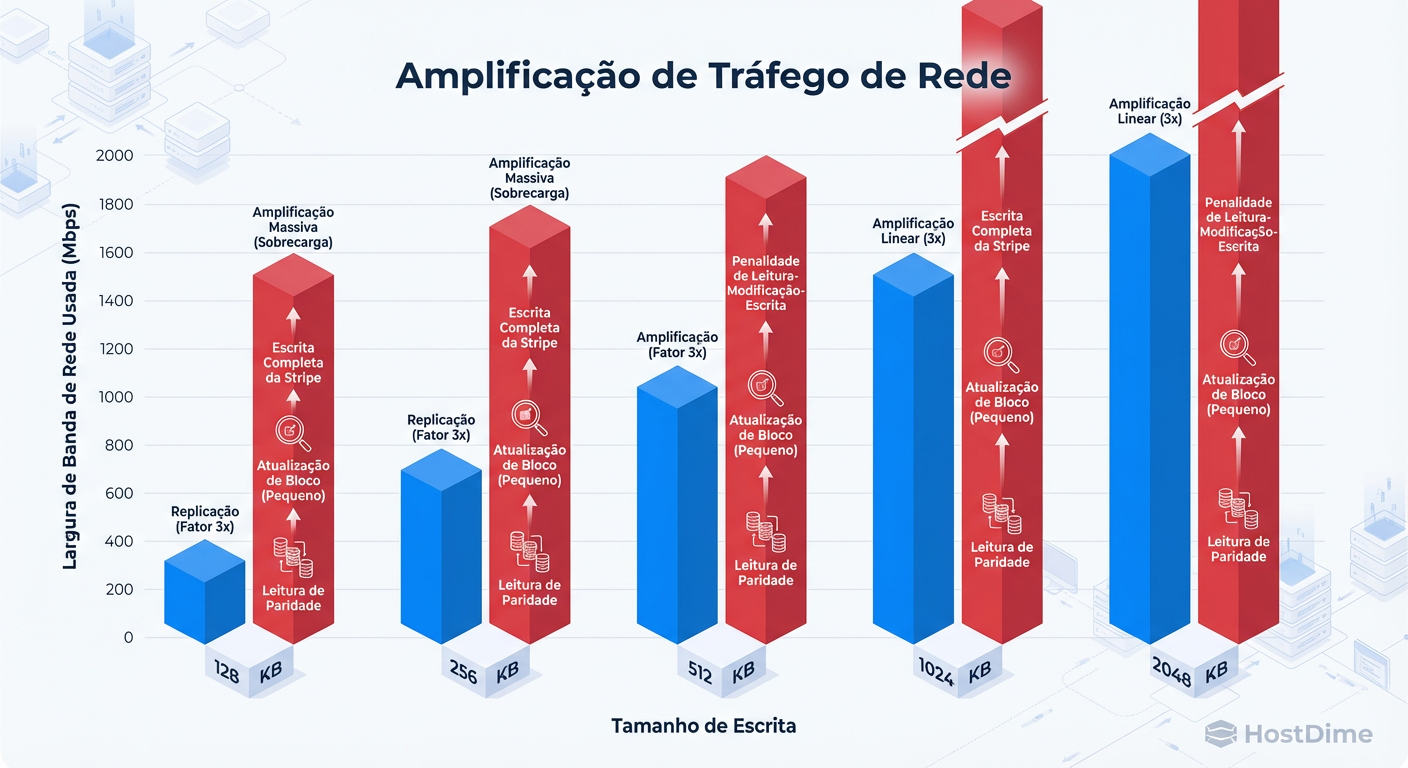 Figura: Amplificação de Tráfego: Em escritas pequenas (bancos de dados, logs), o Erasure Coding pode gerar tráfego de rede muito superior ao tamanho do dado original.
Figura: Amplificação de Tráfego: Em escritas pequenas (bancos de dados, logs), o Erasure Coding pode gerar tráfego de rede muito superior ao tamanho do dado original.
Isso gera uma amplificação de tráfego de rede (Network Amplification) massiva. Uma escrita de 4KB no banco de dados pode gerar 40KB ou mais de tráfego "East-West" (inter-nós) para coordenar as leituras e escritas das paridades.
Se o seu cluster utiliza rede de 10Gbps compartilhada entre public e cluster network, o Erasure Coding pode saturar o link com tráfego de backend, causando jitter na aplicação frontend.
Tabela Comparativa: O Impacto Real
| Característica | Replicação (3x) | Erasure Coding (4+2) | Veredito de Performance |
|---|---|---|---|
| Eficiência de Espaço | 33% (Caro) | 66% (Econômico) | EC vence no bolso. |
| Latência de Escrita (Small Block) | Baixa (1x RTT) | Alta (2x RTT + CPU + Leitura prévia) | Replicação vence (crítico para DBs). |
| Uso de CPU | Irrisório | Intenso (Cálculo de CRC/Paridade) | Replicação vence. |
| Tempo de Rebuild (Recovery) | Rápido (Cópia sequencial) | Lento (Leitura de todos os nós + Cálculo) | Replicação é mais segura. |
| Resiliência em Cluster Pequeno | Alta (Tolera nós inteiros facilmente) | Risco (Rebuilds degradam performance global) | Replicação é mais estável. |
Métricas de Decisão: O Que Medir Antes de Abandonar a Replicação
Não acredite em "best practices" de vendedores. Valide o comportamento do seu hardware com o workload específico. Se você está cogitando migrar de Replicação para EC para economizar disco, execute um teste de estresse focado em Random Write.
Abaixo, um exemplo de metodologia usando fio para expor a latência de RMW.
O Teste de Aferição (FIO)
O objetivo não é ver o número máximo de IOPS, mas a latência de conclusão (clat) sob carga.
# Simula workload de banco de dados: IO aleatório, blocos pequenos, sincronismo forçado.
fio --name=teste_latencia_ec \
--ioengine=libaio --direct=1 --sync=1 \
--rw=randwrite --bs=4k --numjobs=4 \
--iodepth=1 --size=10G --runtime=60 \
--time_based --group_reporting \
--filename=/mnt/seu_volume_ec/testfile
O que analisar nos resultados:
clat (Completion Latency) - 99.00th percentile: Se este número passar de 10ms-20ms em SSDs, sua aplicação sentirá lentidão. No EC, é comum ver o p99 saltar drasticamente comparado à replicação.
IOPS: Compare o IOPS deste teste no volume EC versus um volume Replicado. A queda costuma ser de 50% ou mais em configurações 4+2.
Domínios de Falha: O Risco Matemático em Clusters de 3 a 5 Nós
Além da performance pura, existe um risco operacional severo ao usar EC em clusters pequenos.
Imagine um cluster Ceph ou MinIO de 4 nós usando EC 2+2 (ou similar). Se você perder 1 nó:
O cluster entra em estado degradado.
Para ler qualquer dado que estava no nó falho, o sistema precisa ler os outros 3 fragmentos e recalcular em tempo real. A latência de leitura dispara.
O processo de "rebuild" (cura) começa. Ele vai ler massivamente os discos restantes e saturar a CPU para reconstruir a paridade.
Em clusters pequenos, não há "vizinhos silenciosos". O tráfego de reconstrução compete diretamente com a produção. Em Replicação, a recuperação é apenas uma cópia de arquivos, muito menos custosa para a CPU.
Callout de Risco: Em clusters com menos de 6 nós, o uso de Erasure Coding aumenta significativamente a probabilidade de uma "tempestade de I/O" durante falhas, podendo tornar o cluster inacessível (IO Hang) mesmo que não haja perda de dados.
Veredito Pragmático: Quando a Economia de Espaço Vale o Risco
A decisão entre EC e Replicação não deve ser baseada apenas no custo do TB, mas na natureza do dado.
Use Replicação (3x) Quando:
O Cluster é Pequeno: Menos de 6 nós físicos.
O Workload é Quente: Block Storage para VMs (RBD/iSCSI), Bancos de Dados (Postgres, MySQL), Filas (Kafka).
A Latência é KPI: Se o SLA exige tempos de resposta abaixo de 5ms.
Use Erasure Coding Quando:
O Cluster é Médio/Grande: 6+ nós, idealmente 10+.
Object Storage (S3): Backups, Arquivos de Mídia, Logs, Data Lakes.
Dados "Write-Once-Read-Many" (WORM): Onde a escrita é sequencial e a leitura é esporádica.
O Tamanho do Objeto é Grande: Arquivos > 1MB sofrem menos com a penalidade de RMW.
A engenharia de performance é a arte de gerenciar gargalos. O Erasure Coding remove o gargalo de capacidade de disco, mas introduz gargalos de CPU e Rede. Em clusters pequenos, essa troca raramente compensa para dados de produção ativos. Pague o "imposto" da replicação e durma tranquilo.
Referências & Leitura Complementar
Ceph Documentation - Erasure Code Profiles: Detalhes sobre algoritmos jerasure e lrc e seus impactos em overhead.
Google File System (2003): O paper seminal que discute os trade-offs originais de replicação em sistemas distribuídos.
Intel ISA-L Library: Documentação técnica sobre a aceleração de instruções AVX para cálculo de Reed-Solomon (essencial para entender o custo de CPU).
RFC 9656 (Erasure Coding in Storage): Discussões teóricas sobre implementação de códigos de correção de erro em redes.

Roberto Sato
Planejador de Capacidade
"Traduzo métricas de consumo em modelos de crescimento sustentável. Minha missão é antecipar gargalos e garantir que sua infraestrutura escale matematicamente antes de atingir o limite crítico."