Expansão de RAIDZ no OpenZFS: O custo oculto da geometria mista

Adicionar discos ao RAIDZ parece mágica, mas cria um vdev híbrido. Entenda o impacto na paridade, a armadilha do 'reflow' e como recuperar a performance real.
Durante mais de uma década, a regra de ouro do ZFS foi imutável: uma vez criado um vdev RAIDZ, sua largura era eterna. Se você construísse um array com 4 discos, ele morreria com 4 discos. A única forma de crescer era adicionar um novo vdev ou substituir todos os discos por maiores e resilverar. Era uma limitação arquitetural rígida que frustrava desde administradores de datacenters até entusiastas de Home Labs.
Com a chegada do OpenZFS 2.3 (e a fundação lançada anteriormente), o recurso de RAIDZ Expansion finalmente se tornou realidade. O "Santo Graal" do armazenamento chegou. Você pode conectar um novo disco e rodar zpool attach. O pool cresce. O espaço livre aparece.
Mas, como tudo em sistemas de arquivos Copy-on-Write (CoW), não existe mágica, apenas engenharia. E a engenharia por trás dessa expansão traz um detalhe crítico que muitos ignoram: a geometria mista. Se você acha que adicionar um disco redistribui magicamente seus dados antigos para aproveitar a nova eficiência de paridade, você está enganado. E esse engano está custando terabytes de capacidade que você acha que tem, mas não tem.
Resumo em 30 segundos
- Não é um Rebalanceamento: A expansão RAIDZ apenas disponibiliza espaço extra; ela não reescreve os dados existentes para a nova largura de stripe.
- Eficiência Estagnada: Dados antigos mantêm a proporção de paridade antiga (ex: 25% de perda), enquanto apenas novos dados ganham a nova eficiência (ex: 20% de perda).
- A Solução é Reescrever: Para recuperar a capacidade real e normalizar a performance, você deve forçar a reescrita dos dados antigos após a expansão.
A Ilusão da Capacidade Imediata
Quando operamos com RAID tradicional (como o mdadm no Linux), a expansão de um array envolve um processo excruciante de "reshaping". O sistema lê cada bloco, recalcula a paridade para a nova quantidade de discos e grava tudo de novo. É lento, perigoso, mas resulta em um array perfeitamente uniforme.
O ZFS, fiel à sua filosofia de integridade e CoW, recusa-se a fazer isso dessa forma.
No OpenZFS, a expansão funciona através de um mecanismo de Reflow. O sistema aloca o espaço do novo disco e atualiza os metadados para saber que o vdev agora é maior. No entanto, os blocos de dados que já estavam gravados no disco permanecem exatamente onde e como estavam.
 Figura: Diagrama visualizando a persistência da geometria antiga: os dados originais não ocupam o novo disco automaticamente.
Figura: Diagrama visualizando a persistência da geometria antiga: os dados originais não ocupam o novo disco automaticamente.
Isso cria um cenário de Geometria Mista. Imagine que você tinha um RAIDZ1 de 4 discos (3 dados + 1 paridade).
Antes: Cada stripe ocupava 4 setores físicos.
Depois: O vdev agora tem 5 discos. Novos stripes ocuparão 5 setores físicos.
O problema? Os dados antigos continuam ocupando 4 setores. O ZFS não "estica" o stripe antigo para cobrir o novo disco. O novo disco fica, essencialmente, vazio para os dados antigos, sendo usado apenas para novas alocações.
O Matemático e o Contador de Espaço
Aqui reside a dissonância cognitiva. O comando zpool list mostrará o aumento da capacidade bruta (RAW). Mas a eficiência de armazenamento dos seus dados antigos não mudou.
Vamos aos números, pois a matemática não mente:
Cenário: Expansão de 4-wide para 5-wide (RAIDZ1)
| Estado | Largura do Stripe | Dados : Paridade | Eficiência de Armazenamento | Custo de Paridade |
|---|---|---|---|---|
| Dados Antigos | 4 Discos | 3 : 1 | 75% | 25% |
| Dados Novos | 5 Discos | 4 : 1 | 80% | 20% |
Se você tem 40TB de dados gravados na geometria antiga e expande o pool, esses 40TB continuam "pagando" 25% de imposto de paridade. Se eles fossem convertidos para a nova geometria, pagariam apenas 20%.
⚠️ Perigo: Se você expandir um pool cheio (90%+) esperando liberar espaço imediatamente para os dados existentes, vai se decepcionar. Você ganha espaço para novas gravações, mas não recupera a eficiência perdida nos dados arquivados.
Por que o Scrub não resolve?
Existe um mito persistente nos fóruns de TrueNAS e Reddit: "Basta rodar um scrub depois de expandir".
Isso é falso.
O zpool scrub é uma ferramenta de verificação de integridade. Ele percorre a Merkle Tree, lê os blocos, calcula o checksum SHA-256 (ou o que você estiver usando) e compara com o metadado. Se o bloco estiver íntegro, o scrub fica feliz e segue em frente.
O scrub não realoca blocos saudáveis. Ele não olha para um stripe de 4 discos e diz: "Ei, agora temos 5 discos, deixe-me reescrever isso para ser mais eficiente". Ele apenas valida que os bits estão corretos na sua forma atual. Para o ZFS, a geometria mista é um estado válido, não um erro a ser corrigido.
A Estratégia de Normalização (Reescrita Forçada)
Para obter o benefício real da expansão — ou seja, aumentar a proporção de dados úteis em relação à paridade — você precisa forçar o ZFS a tirar os dados do "molde" antigo e gravá-los no "molde" novo.
Como o ZFS é Copy-on-Write, qualquer reescrita de dados alocará novos blocos. E, como o vdev agora é maior, o alocador usará a nova largura de stripe (5-wide no nosso exemplo) para esses novos blocos.
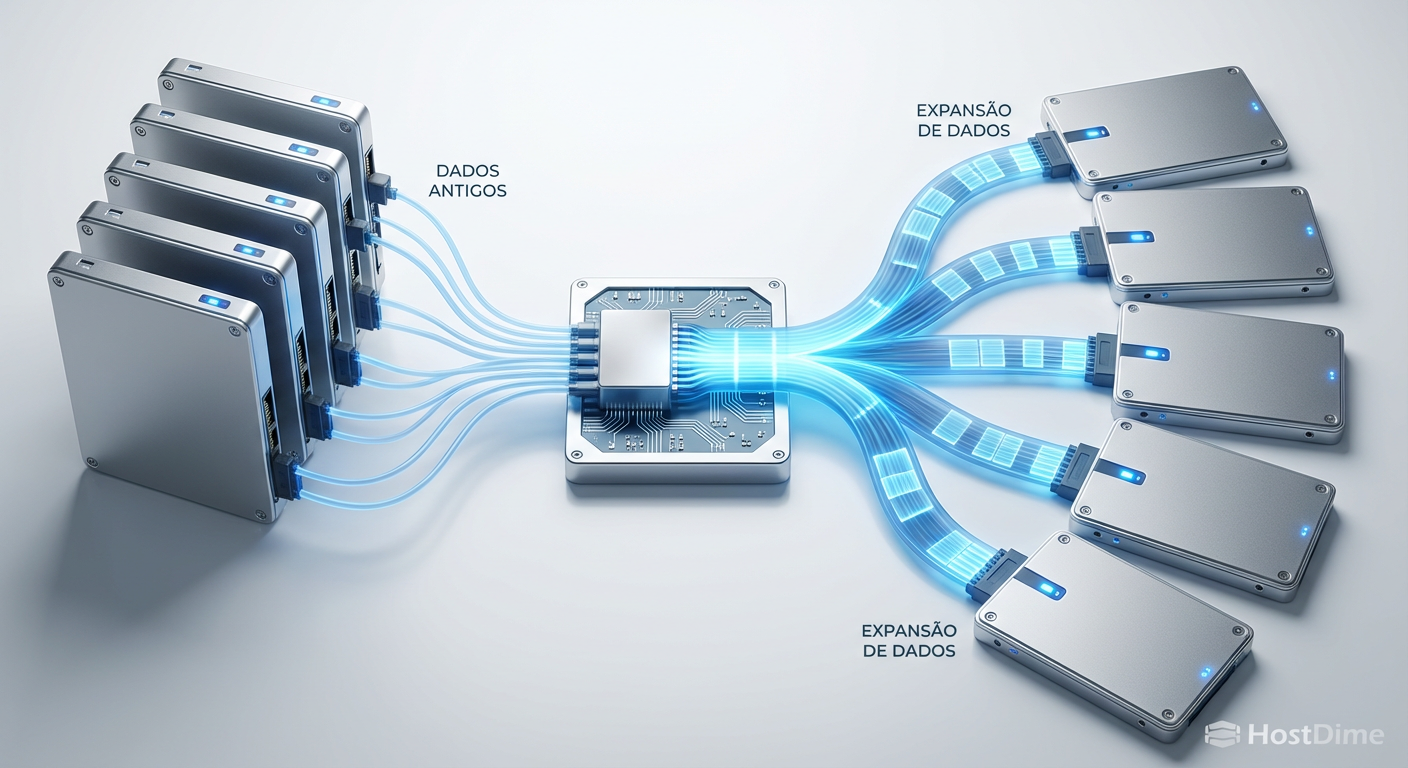 Figura: O fluxo de reescrita: transformando stripes estreitos e ineficientes em stripes largos e otimizados através do Copy-on-Write.
Figura: O fluxo de reescrita: transformando stripes estreitos e ineficientes em stripes largos e otimizados através do Copy-on-Write.
Métodos de Reescrita
Existem duas abordagens principais para normalizar sua geometria:
ZFS Send | ZFS Recv (O Método Atômico) A forma mais limpa. Você cria um snapshot, envia para um novo dataset (no mesmo pool) e destrói o antigo.
zfs snapshot tank/dados@migracao zfs send tank/dados@migracao | zfs recv tank/dados_novos # Após verificar, troque os nomesIsso garante que cada byte seja gravado sequencialmente com a nova geometria.
Rebalanceamento In-Place (CP Reflink) Se você não tem espaço para duplicar o dataset, pode ser necessário reescrever arquivo por arquivo. Ferramentas que leem e reescrevem o arquivo (sem usar
reflink) forçarão a nova alocação.💡 Dica Pro: Simplesmente mover arquivos dentro do mesmo dataset não funciona se for apenas uma operação de renomeação de ponteiros. Você precisa efetivamente ler o conteúdo e gravar novos blocos.
Impacto na Performance e Fragmentação
Operar com geometria mista não é apenas uma questão de espaço; é uma questão de desempenho. O alocador do ZFS agora tem que lidar com regiões de larguras diferentes.
Quando você expande o RAIDZ, o novo espaço livre está majoritariamente no novo disco e nas regiões liberadas por exclusões futuras. Isso pode aumentar a fragmentação lógica. O ZFS terá que buscar "buracos" de tamanhos variados para encaixar novos stripes.
Em discos mecânicos (HDD), isso pode se traduzir em maior latência de busca (seek time) se o pool estiver muito cheio e fragmentado. Em SSDs/NVMe, o impacto é menor, mas o custo de CPU para o alocador encontrar blocos contíguos livres aumenta.
 Figura: Gráfico de eficiência temporal: o ganho real de capacidade ocorre durante a fase de reescrita, não no momento da expansão.
Figura: Gráfico de eficiência temporal: o ganho real de capacidade ocorre durante a fase de reescrita, não no momento da expansão.
Validação Técnica
Como saber se seus dados estão na geometria antiga ou nova? O comando zdb (ZFS Debugger) é seu amigo, mas use-o com cautela (preferencialmente em modo somente leitura com -e se o pool estiver exportado, ou com cuidado em produção).
Você pode verificar a distribuição de tamanho de blocos e a largura dos stripes. Se após a expansão você ainda vir uma predominância massiva de alocações com a largura antiga (ex: asize que corresponde a 3 discos de dados + paridade), você sabe que seu trabalho de reescrita ainda não terminou.
O Veredito do Guru
A expansão de RAIDZ é uma ferramenta poderosa, mas perigosa para o administrador desatento. Ela resolve o problema de "preciso adicionar um disco", mas cria uma dívida técnica na forma de ineficiência de paridade.
Minha recomendação direta: Planeje a expansão acompanhada de uma janela de manutenção para reescrita. Não trate a expansão como um botão de "mais espaço grátis". Trate-a como uma mudança de infraestrutura que requer uma migração de dados interna para ser concluída com sucesso. Se você expandir e esquecer, estará desperdiçando a vida útil dos seus discos e a capacidade pela qual pagou.
No mundo do armazenamento, a preguiça é punida com ineficiência. Reescreva seus dados.
Referências & Leitura Complementar
OpenZFS Pull Request #12225: A implementação técnica original do recurso de expansão RAIDZ.
Fundação OpenZFS: Documentação sobre "RAIDZ Expansion Reflow Mechanism".
Matt Ahrens (Delphix): Apresentações sobre a alocação de blocos e o desafio da geometria mista no ZFS Developer Summit.
Perguntas Frequentes (FAQ)
O comando zpool attach reescreve a paridade dos dados antigos?
Não. O OpenZFS apenas realoca os metadados para reconhecer o novo dispositivo e disponibilizar o espaço bruto. Os dados existentes permanecem com a largura de stripe original (ex: 3 dados + 1 paridade) e a eficiência antiga. Apenas novos dados gravados após a expansão aproveitarão a nova largura (ex: 4 dados + 1 paridade).Posso expandir um vdev RAIDZ1 para RAIDZ2?
Não. A expansão de RAIDZ permite adicionar discos para aumentar a capacidade e a largura do stripe (ex: de 4 para 5 discos), mas não altera o nível de redundância (paridade) do vdev. Um vdev RAIDZ1 continuará sendo RAIDZ1 (tolerância a 1 falha), mesmo que tenha 20 discos.O desempenho de leitura é afetado após a expansão?
Sim, marginalmente. O vdev passa a operar com geometrias mistas, exigindo que o alocador gerencie blocos com larguras diferentes. Isso pode introduzir latência em cargas de trabalho aleatórias e aumentar a fragmentação até que os dados sejam reescritos e normalizados.
Roberto Holanda
Guru de Sistemas de Arquivos (ZFS/Btrfs)
"Dedico minha carreira à integridade dos dados. Para mim, o bit rot é o inimigo e o Copy-on-Write é a salvação. Exploro a fundo ZFS, Btrfs e a beleza dos checksums."