Expansão de RAIDZ online: dissecando a mecânica de reflow e a fragmentação no OpenZFS 2.3

Entenda a engenharia por trás da expansão de vdevs RAIDZ no OpenZFS. Descubra como o sistema evita o restriping perigoso, gerencia stripes de largura mista e o impacto real na fragmentação.
Durante quase duas décadas, a regra de ouro do ZFS foi imutável: uma vez criado um vdev RAIDZ, sua largura (o número de discos) era eterna. Se você construísse um RAIDZ2 com 6 discos e precisasse de mais espaço, suas opções eram adicionar um vdev inteiramente novo ou substituir todos os discos por maiores, um a um. Era uma rigidez arquitetural que frustrava desde administradores de homelabs até arquitetos de storage enterprise.
Com a chegada do OpenZFS 2.3, essa barreira foi finalmente derrubada. A expansão de RAIDZ (RAIDZ Expansion) é real. No entanto, diferentemente de sistemas de arquivos legados que simplesmente "movem blocos para a direita", o ZFS realiza essa operação mantendo sua filosofia de Copy-on-Write (CoW) e integridade transacional. Isso introduz conceitos complexos de geometria variável e fragmentação de largura mista que todo engenheiro de dados precisa compreender antes de digitar zpool attach.
Resumo em 30 segundos
- Sem Reescrita Automática: A expansão não redistribui (rebalanceia) os dados antigos automaticamente. Dados velhos mantêm a proporção de paridade antiga; apenas novos dados usam a nova largura.
- Fragmentação Lógica: O vdev passa a conter regiões com larguras de stripe diferentes (ex: blocos de 4 discos coexistindo com blocos de 5 discos), criando complexidade nos metadados.
- Custo de Paridade: Você não ganha espaço livre equivalente à capacidade total do novo disco imediatamente para os dados existentes. O ganho de eficiência de paridade só ocorre ao reescrever os arquivos.
O bloqueio arquitetural da topologia RAIDZ clássica
Para entender a elegância da solução atual, precisamos dissecar o problema original. No RAID tradicional (como o RAID 5 de hardware), a geometria do stripe é fixa e agnóstica ao sistema de arquivos. O controlador apenas vê blocos LBA.
No ZFS, o RAIDZ é ciente do sistema de arquivos. O tamanho do stripe é dinâmico, variando de acordo com o tamanho do bloco de dados (recordsize) sendo gravado. Cada gravação é uma transação atômica completa, com seus próprios setores de dados e paridade calculados on-the-fly.
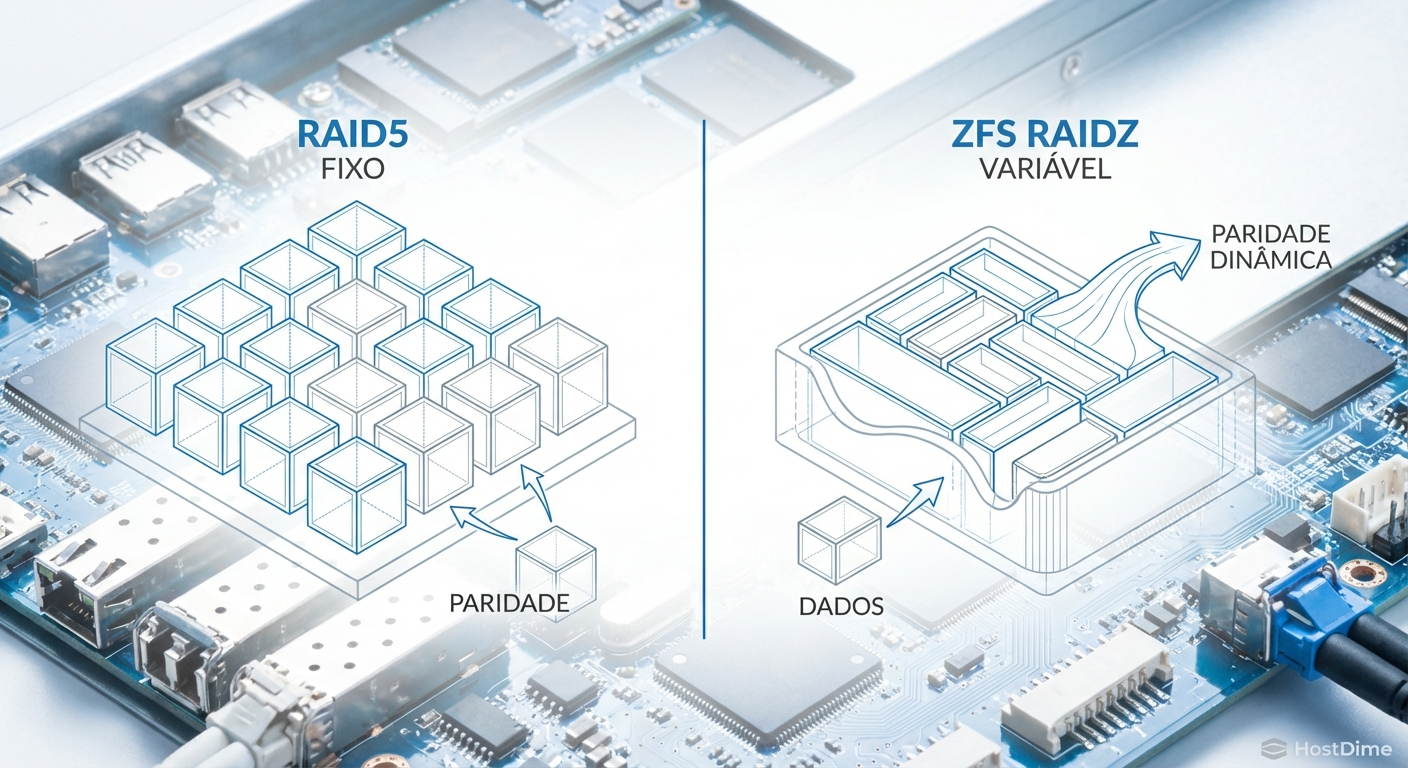 Figura: Comparativo visual: A rigidez do stripe fixo tradicional versus a alocação dinâmica de largura variável do ZFS.
Figura: Comparativo visual: A rigidez do stripe fixo tradicional versus a alocação dinâmica de largura variável do ZFS.
Historicamente, a matemática de alocação do ZFS dependia de saber, de antemão, quantos discos existiam no grupo para calcular onde a paridade cairia. Alterar esse número ($N$) invalidaria a localização de cada bloco existente no disco, exigindo uma reescrita total de petabytes de dados, o que seria perigoso e inviável em produção.
A nova geometria: expansão sem reescrita
A inovação trazida pela Fundação OpenZFS, liderada pelo trabalho de Matt Ahrens, reside em dissociar a geometria física da lógica. Quando você adiciona um disco a um grupo RAIDZ existente, o ZFS não tenta "consertar" o passado.
Em vez disso, ele cria uma nova região de alocação. O vdev entra em um estado híbrido. Imagine que você tem um RAIDZ1 de 3 discos (3-wide) e adiciona um quarto disco.
Dados Antigos: O ZFS lembra que esses blocos foram gravados na geometria "3-wide". Eles continuam ocupando espaço apenas nos 3 discos originais. O quarto disco, nessas regiões lógicas, é ignorado ou preenchido com zeros virtuais para fins de cálculo.
Dados Novos: Qualquer nova gravação (ou reescrita de dados antigos via CoW) agora enxerga uma geometria "4-wide". O alocador de espaço distribui o stripe e a paridade através dos 4 discos, aproveitando a nova eficiência.
O mito do "Reflow" automático
Muitos administradores esperam que, ao expandir o array, o sistema inicie um processo de "restriping" em background, similar ao que ocorre em storages SAN tradicionais ou no mdadm do Linux.
⚠️ Perigo: O OpenZFS NÃO faz reflow automático dos dados existentes. Se o seu pool está 90% cheio e você adiciona um disco, os dados antigos continuam comprimidos na geometria ineficiente anterior. O espaço "ganho" só é totalmente utilizável para novos dados.
Para converter dados antigos para a nova geometria (e recuperar a eficiência da proporção dados/paridade), você deve reescrevê-los manualmente. Isso pode ser feito via zfs send | zfs recv ou simplesmente copiando os arquivos. O zpool scrub não realiza essa conversão; ele apenas verifica a integridade dos checksums baseados na geometria original de gravação.
Fragmentação de largura mista e metadados
A introdução de larguras de stripe variáveis dentro do mesmo vdev cria um fenômeno que chamo de "Fragmentação de Largura Mista".
O alocador do ZFS (o componente que decide onde os blocos vivem) agora precisa gerenciar espaços livres que têm "pesos" diferentes. Um setor livre na região antiga do disco vale menos (em termos de eficiência de paridade) do que um setor livre na região nova, mas o ZFS abstrai isso apresentando um espaço livre unificado.
 Figura: Mapa de calor lógico de um vdev expandido: Regiões azuis representam dados legados (largura antiga), enquanto regiões laranjas mostram novos dados utilizando a largura expandida.
Figura: Mapa de calor lógico de um vdev expandido: Regiões azuis representam dados legados (largura antiga), enquanto regiões laranjas mostram novos dados utilizando a largura expandida.
Isso gera um overhead de metadados. O ZFS precisa rastrear não apenas onde o bloco está, mas qual era a topologia do vdev no momento daquela gravação específica. Embora o impacto na CPU seja negligenciável em processadores modernos (graças às instruções AVX para cálculo de RAIDZ), há um custo em IOPS. Ler um arquivo antigo fragmentado e misturado com arquivos novos pode exigir buscas em padrões de disco ligeiramente diferentes.
Tabela Comparativa: Expansão Tradicional vs. Expansão RAIDZ
| Característica | Adicionar Novo Vdev (Método Antigo) | Expandir Vdev Existente (Novo Método) |
|---|---|---|
| Redundância | Aumenta pontos de falha (se um vdev falha, o pool falha) | Mantém o nível de redundância (RAIDZ1/2/3) |
| Espaço Útil | Disponível imediatamente | Disponível imediatamente (para novos dados) |
| Eficiência de Paridade | Fixa por vdev | Mista (dados velhos = baixa, novos = alta) |
| IOPS | Aumenta (mais vdevs = mais IOPS) | Mantém similar (limitado pelo vdev único) |
| Recomendação | Para performance | Para capacidade e custo-benefício |
Validando a eficiência com zdb
Como gurus de sistemas de arquivos, não confiamos apenas na documentação; verificamos os bits no disco. A ferramenta zdb (ZFS Debugger) é nossa lente de aumento para observar essa nova estrutura.
Ao expandir um pool, você pode observar a mudança na distribuição dos metaslabs. Se você executar um comando para listar a estrutura interna de blocos após uma expansão e algumas gravações, verá uma mistura de asize (allocated size).
Um teste prático revela a mecânica:
Crie um pool RAIDZ1 com 3 discos.
Grave um arquivo de 1GB. O
ratiode compressão/paridade será baseado em $N=3$.Execute
zpool attach pool raidz1-0 novo_disco.Grave outro arquivo de 1GB.
Ao inspecionar com
zdb -bb, você notará que o primeiro arquivo mantém seus endereços de dispositivo originais (DVA), enquanto o segundo arquivo espalha seus DVAs pelo quarto dispositivo.
💡 Dica Pro: Use o comando
zpool list -vpara monitorar a capacidade bruta versus alocada. Após a expansão, você verá a capacidade total aumentar, mas observe a colunaFRAG. A expansão tende a aumentar artificialmente as métricas de fragmentação devido à descontinuidade do espaço de endereçamento lógico.
O impacto no Resilvering e Scrub
Uma preocupação legítima é a segurança durante a reconstrução. A expansão do RAIDZ foi projetada para ser robusta. Se um disco falhar durante ou após a expansão, o processo de resilvering (reconstrução) é capaz de entender a geometria mista.
O resilver lerá os metadados para saber: "Ah, este bloco pertence à era de 4 discos, então preciso ler a paridade dos discos 1, 2 e 3 para reconstruir o 4". Para blocos novos: "Este é da era de 5 discos, preciso ler 1, 2, 3 e 5 para reconstruir o 4".
Essa inteligência adiciona uma leve sobrecarga computacional ao processo de scrub/resilver, mas garante que a integridade matemática dos dados — a alma do ZFS — permaneça inviolável. Não há "buracos" na proteção de paridade durante a transição.
 Figura: O fluxo de verificação: O scrub do ZFS validando checksums através de gerações diferentes de geometria de stripe sem interromper o acesso.
Figura: O fluxo de verificação: O scrub do ZFS validando checksums através de gerações diferentes de geometria de stripe sem interromper o acesso.
Considerações finais e cenário de uso
A expansão de RAIDZ no OpenZFS 2.3 não é mágica; é engenharia de precisão com compromissos calculados. Ela resolve o problema de "custo de degrau" para pequenos e médios arrays, permitindo o crescimento orgânico do armazenamento.
No entanto, minha recomendação técnica é cautela no planejamento de capacidade. Não use essa funcionalidade para transformar um RAIDZ1 de 3 discos em um de 20 discos ao longo de 5 anos. A sobrecarga de metadados e a ineficiência acumulada de paridade (se você não reescrever os dados) podem degradar a performance a longo prazo.
Use a expansão para ajustes táticos — adicionar um ou dois discos para estender a vida útil de um servidor — mas continue planejando arquiteturas de vdevs balanceados para o longo prazo. O ZFS lhe dá a corda; cabe a você não fazer um nó nela.
Referências & Leitura Complementar
OpenZFS Pull Request #15022: A implementação técnica original da expansão RAIDZ, detalhando as mudanças no ponteiro de bloco e lógica de alocação.
Matt Ahrens (2023): "RAIDZ Expansion: How it works and how to use it" – Apresentação técnica no OpenZFS Developer Summit.
RFC ZFS-0003: Documentação sobre a estrutura de alocação dinâmica e geometria de vdevs variáveis.
A expansão do RAIDZ reequilibra os dados antigos automaticamente?
Não. O OpenZFS não reescreve dados antigos automaticamente (sem restriping). Os dados existentes permanecem com a largura de stripe original, e apenas novos dados utilizam a nova largura e eficiência de paridade, a menos que você force uma reescrita manual.O que é o overhead de fragmentação na expansão RAIDZ?
Ao expandir um vdev, cria-se uma mistura de larguras de stripe (ex: dados antigos em 4-wide, novos em 5-wide). Isso gera metadados adicionais para rastrear onde cada bloco começa e qual geometria ele usa, resultando em um leve aumento no uso de CPU e fragmentação lógica do espaço livre.É seguro expandir um RAIDZ durante carga alta de IO?
Sim, a operação é projetada para ser segura e online. No entanto, como qualquer operação de metadados intensiva em sistemas de arquivos Copy-on-Write, haverá um impacto na latência e no throughput durante o processo de integração do novo disco e alocação das novas tabelas de mapeamento.
Roberto Holanda
Guru de Sistemas de Arquivos (ZFS/Btrfs)
"Dedico minha carreira à integridade dos dados. Para mim, o bit rot é o inimigo e o Copy-on-Write é a salvação. Exploro a fundo ZFS, Btrfs e a beleza dos checksums."