Falhas cinzentas: por que um disco lento é mais perigoso que um disco morto

Entenda o conceito de Gray Failures em storage. Descubra como componentes degradados evadem health checks e derrubam a performance de clusters inteiros.
No gerenciamento de incidentes em infraestrutura de armazenamento, existe um axioma contra-intuitivo: um componente totalmente morto é preferível a um componente parcialmente funcional. Quando um disco rígido (HDD) ou SSD falha completamente (o chamado fail-stop), o sistema operacional, a controladora RAID ou o software de armazenamento distribuído (como Ceph ou vSAN) detecta o evento imediatamente. O componente é isolado, os alertas disparam e a recuperação começa.
O verdadeiro pesadelo operacional reside na "falha cinzenta" (gray failure). É o disco que responde, mas leva 800ms para completar uma leitura que deveria levar 2ms. É a placa de rede que descarta 5% dos pacotes silenciosamente. Esses componentes "zumbis" não disparam alarmes de indisponibilidade, mas envenenam a performance de todo o cluster, transformando uma arquitetura de alta disponibilidade em um gargalo sistêmico.
Resumo em 30 segundos
- Definição: Falhas cinzentas ocorrem quando componentes funcionam de forma degradada, evadindo a detecção binária de "up/down".
- Impacto: Um único disco lento em um array RAID ou cluster distribuído pode travar todas as requisições de I/O devido ao bloqueio de filas.
- Solução: Monitoramento baseado em latência de cauda (P99/P999) e comparação entre pares (outlier detection) são essenciais para isolar componentes degradados automaticamente.
A anatomia de uma falha cinzenta
Em ambientes Enterprise, a disponibilidade é frequentemente medida de forma binária: o serviço está online ou offline. No entanto, o hardware moderno raramente falha de forma limpa. Discos rígidos desenvolvem setores defeituosos que exigem múltiplas tentativas de leitura (retries) pelo firmware antes de entregar o dado. SSDs podem sofrer com garbage collection agressivo ou falhas no controlador que aumentam a latência de forma intermitente.
Esses comportamentos criam o cenário de falha cinzenta. O componente reporta ao sistema operacional que está "saudável" (status SMART OK, link UP), mas sua capacidade de processar I/O despenca.
💡 Dica Pro: Nunca confie cegamente no status "OK" do SMART ou na luz verde do chassi. Um disco pode reportar saúde perfeita enquanto tenta recuperar um setor por 10 segundos, bloqueando toda a fila de comandos do sistema operacional.
A sutileza desse problema reside na sua invisibilidade para ferramentas de monitoramento padrão. Se o seu health check apenas pinga o servidor ou verifica se o volume está montado, o incidente passará despercebido até que os usuários finais comecem a reportar lentidão extrema na aplicação.
O efeito cascata da latência de cauda
O perigo real da falha cinzenta não é a lentidão do componente em si, mas como ela se propaga. Em sistemas de armazenamento modernos, os dados são distribuídos (striping em RAID, sharding em bancos de dados ou objetos em Ceph). Para ler ou gravar um bloco de dados, o sistema frequentemente precisa interagir com múltiplos discos simultaneamente.
Considere um array RAID 5 ou um Erasure Coding 4+2. Uma operação de escrita requer confirmação de múltiplos drives. Se um único disco no grupo entra em estado de falha cinzenta e demora 2 segundos para responder, toda a operação de escrita é penalizada por esses 2 segundos. A performance do array inteiro cai para a velocidade do disco mais lento.
 Figura: Visualização do bloqueio de fila: como um único disco degradado (em amarelo) ociosa os discos saudáveis e cria uma fila de espera, elevando a latência global do sistema.
Figura: Visualização do bloqueio de fila: como um único disco degradado (em amarelo) ociosa os discos saudáveis e cria uma fila de espera, elevando a latência global do sistema.
Isso é conhecido como amplificação de latência de cauda. A latência média pode parecer aceitável, mas a latência no percentil 99 (P99) — as requisições mais lentas — dispara. Em sistemas de alta concorrência, essas requisições lentas seguram locks de banco de dados, threads de aplicação e conexões de rede, causando um efeito dominó que pode derrubar aplicações inteiras muito acima da camada de storage.
Por que health checks binários ignoram a degradação
A maioria dos sistemas de monitoramento legados opera no modelo de "batimento cardíaco" (heartbeat). Se o componente responde, ele é considerado vivo. Esse modelo é insuficiente para o hardware atual.
Um disco em falha cinzenta ainda responde aos heartbeats. Ele ainda aceita comandos SCSI ou NVMe. O problema é quando ele responde. Drivers de sistema operacional e controladoras de hardware têm timeouts conservadores, muitas vezes configurados para esperar 30, 60 ou até 180 segundos antes de declarar um comando como falho e resetar o dispositivo.
Durante esse tempo, o sistema operacional assume que o disco está funcionando e continua enviando requisições para a fila, agravando o problema.
Tabela Comparativa: Falha Binária vs. Falha Cinzenta
| Característica | Falha Binária (Fail-Stop) | Falha Cinzenta (Gray Failure) |
|---|---|---|
| Sintoma | Perda total de sinal/conectividade. | Latência alta, timeouts intermitentes, erros corrigíveis. |
| Detecção | Imediata (segundos). | Lenta ou inexistente (horas/dias sem métricas avançadas). |
| Impacto no Cluster | O sistema inicia failover ou rebuild imediatamente. | O sistema aguarda, filas enchem, performance global degrada. |
| Causa Comum | Queima de placa lógica, corte de energia. | Setores defeituosos, firmware bugado, vibração excessiva. |
| Resolução | Substituição física simples. | Requer isolamento lógico forçado antes da troca. |
Estratégias de detecção de outliers
Para combater falhas cinzentas, a equipe de operações deve mudar o foco de "disponibilidade" para "performance relativa". A chave é a detecção de outliers (pontos fora da curva).
Em um cluster de storage (como MinIO, Ceph ou vSAN), todos os discos deveriam, teoricamente, ter uma performance similar sob carga distribuída. Se o Disco A tem uma latência média de 2ms e o Disco B no mesmo servidor tem uma latência de 500ms, o Disco B é um ofensor, mesmo que não esteja reportando erros de I/O.
Monitoramento de Latência de Cauda (P99)
Médias mentem. Se você tem 1000 requisições a 1ms e 1 requisição a 10 segundos, sua média ainda parece ótima, mas um usuário teve uma experiência terrível. Configure seus alertas baseados no P99 ou P999 (o 0,1% das requisições mais lentas). Picos sustentados no P99 são a assinatura clássica de uma falha cinzenta.
⚠️ Perigo: Configurar timeouts muito longos no nível da aplicação para "tolerar falhas" é um erro. Isso apenas mascara a falha cinzenta e prolonga o sofrimento do sistema. É preferível falhar rápido (fail fast) e tentar em outro nó.
Protocolo de resposta: isolamento de componentes zumbis
Uma vez detectado o componente degradado, a ação deve ser decisiva. O objetivo do Comandante de Incidentes não é consertar o disco, mas restaurar o nível de serviço (SLA).
Detecção Comparativa: O sistema de monitoramento identifica que o dispositivo
/dev/sdXestá 10x mais lento que seus pares.Isolamento Lógico (Shoot the Straggler): Não espere o disco morrer. Force o status de "falha" via software. Em Linux, isso pode significar remover o dispositivo do array RAID (
mdadm --fail) ou marcar o OSD comooutno Ceph.Recuperação Automática: O sistema de storage inicia o processo de recuperação usando a redundância (réplicas ou paridade) para servir os dados a partir de drives saudáveis. A performance retorna ao normal imediatamente, mesmo que o sistema esteja em modo "degradado" (sem redundância total).
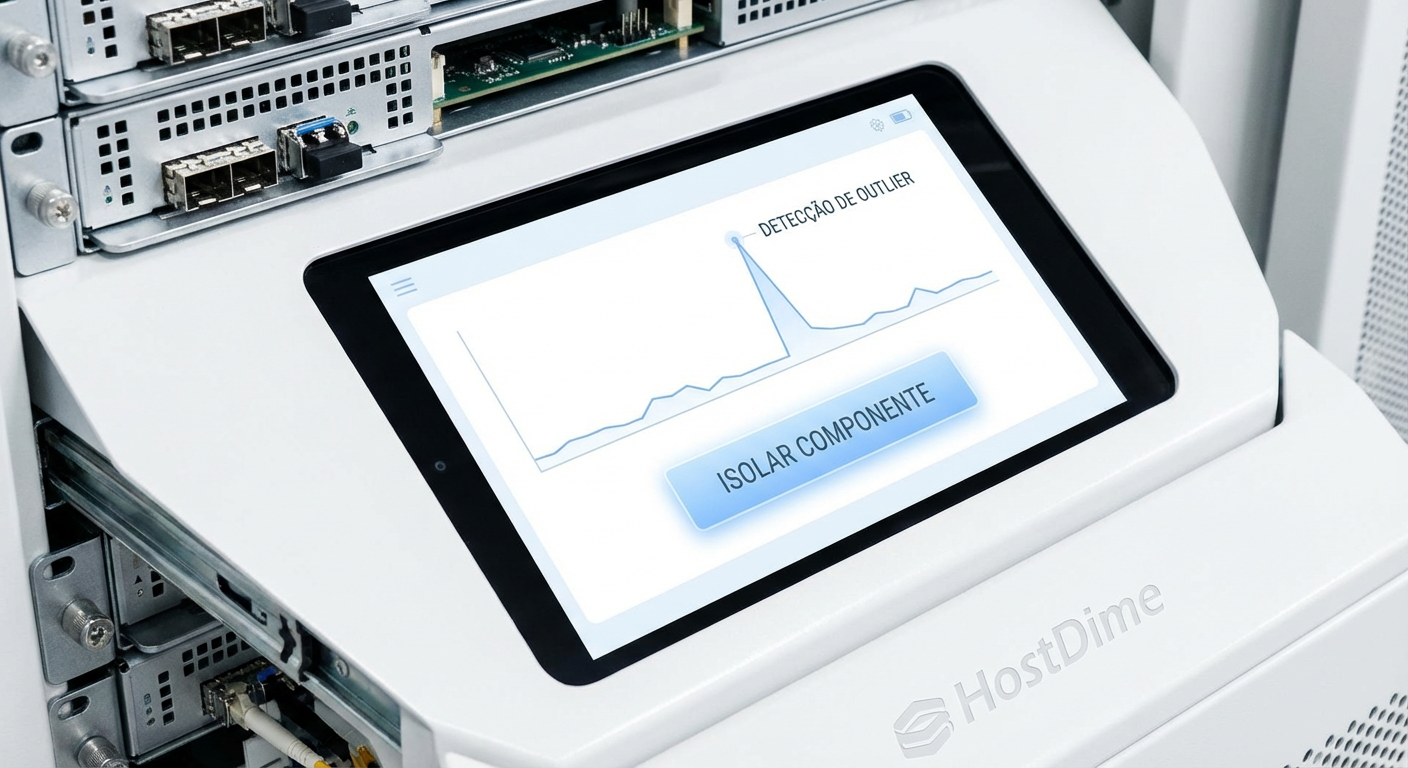 Figura: Interface de resposta a incidentes mostrando a detecção de um outlier de latência e a opção de isolamento imediato do componente degradado.
Figura: Interface de resposta a incidentes mostrando a detecção de um outlier de latência e a opção de isolamento imediato do componente degradado.
Timeouts Agressivos no Nível do Driver
Para infraestruturas críticas, ajustar os timeouts do driver SCSI/NVMe é vital. Reduzir o eh_deadline (error handling deadline) no Linux impede que um disco tente recuperar um erro por minutos. Se o disco não responder em 5 ou 10 segundos, o kernel deve resetá-lo ou marcá-lo como offline, forçando o failover para caminhos redundantes.
Alerta Operacional
A falha cinzenta é o teste definitivo para a maturidade de uma equipe de SRE e infraestrutura. Ela expõe a diferença entre "monitorar se as luzes estão acesas" e "monitorar a qualidade do serviço".
Não aguarde o fornecedor de hardware confirmar que o disco está com defeito. Se a performance do componente ameaça o SLA global, ele deve ser tratado como falho. A integridade do serviço sempre tem prioridade sobre a integridade de um único componente de hardware. Implemente detecção de outliers hoje e configure seus sistemas para "matar" processos e discos lentos sem piedade. Um sistema degradado, mas rápido, é sempre superior a um sistema completo, mas travado.
Referências & Leitura Complementar
"The Tail at Scale" (Dean & Barroso, Google) - Artigo seminal sobre como a latência de cauda afeta sistemas distribuídos e estratégias de mitigação.
"Gray Failure: The Achilles' Heel of Cloud-Scale Systems" (HotOS Workshop) - Pesquisa da Microsoft detalhando o conceito de falhas cinzentas.
NVMe Command Set Specification (NVM Express) - Documentação técnica sobre timeouts e tratamento de erros em drives NVMe modernos.
Perguntas Frequentes (FAQ)
O que é exatamente uma falha cinzenta em storage?
É uma condição de falha parcial onde um componente, como um disco rígido, SSD ou controladora, não para de funcionar totalmente (não fica offline), mas opera com performance severamente degradada ou apresenta erros intermitentes. Isso permite que ele evada a detecção padrão de "up/down" dos sistemas de monitoramento, enquanto prejudica a performance geral.Por que um disco lento é considerado pior que um disco morto?
Um disco morto (fail-stop) é detectado e removido imediatamente pelo sistema, acionando mecanismos de redundância. Já um disco lento (falha cinzenta) continua aceitando requisições, mas demora para processá-las. Isso mantém as requisições na fila, causando timeouts em cascata, bloqueando recursos e derrubando a performance de todo o array RAID ou cluster, muitas vezes tornando o sistema inutilizável.Quais são as melhores técnicas para detectar falhas cinzentas?
A detecção eficaz exige monitoramento de latência de cauda (métricas de percentil P99 ou P999), e não apenas médias. Além disso, é crucial usar a detecção de *outliers*, comparando a performance de um disco com seus pares no mesmo cluster. O monitoramento de logs para erros de I/O corrigíveis (soft errors) e retries excessivos também é um indicador forte.
Roberto Xavier
Comandante de Incidentes
"Lidero equipes em momentos críticos de infraestrutura. Priorizo a restauração rápida de serviços e promovo uma cultura de post-mortem sem culpa para construir sistemas mais resilientes."