Falhas Silenciosas em SSDs NVMe: O Abismo da Recuperação de Dados

Entenda por que SSDs NVMe falham sem aviso prévio. Uma análise técnica sobre FTL, corrupção de controlador e por que a recuperação é exponencialmente mais difícil que em HDDs.
A transição da indústria de discos rígidos mecânicos (HDDs) para o armazenamento de estado sólido (SSDs) trouxe uma revolução de latência e throughput, mas também introduziu uma opacidade perigosa na confiabilidade dos dados. Enquanto um HDD frequentemente anuncia sua morte com ruídos mecânicos e degradação progressiva de performance, um SSD NVMe moderno opera em um silêncio binário: ele funciona perfeitamente a 3.000 MB/s, até o microssegundo em que deixa de existir.
Para o engenheiro de performance ou administrador de sistemas, tratar um SSD NVMe como apenas "um disco mais rápido" é um erro metodológico grave. A complexidade do firmware, a física das células NAND de alta densidade (TLC/QLC) e a abstração lógica criam cenários de falha onde a recuperação de dados não é apenas difícil, é matematicamente impossível.
Falhas silenciosas em SSDs NVMe ocorrem quando o controlador ou a camada FTL corrompem o mapeamento lógico sem emitir códigos de erro ao host, ou quando o dispositivo sofre um colapso súbito de firmware. Diferente da falha mecânica gradual, a degradação eletrônica em células NAND e a corrupção da tabela de tradução tornam a perda de dados instantânea e, devido a tecnologias como TRIM e criptografia de hardware, frequentemente irreversível.
Por que SSDs NVMe falham sem aviso prévio
A intuição que desenvolvemos ao longo de décadas gerenciando spindles (discos rotativos) nos trai ao lidar com memória flash. Em um HDD, um setor defeituoso é uma falha física localizada; a agulha pode tentar reler, o sistema operacional percebe a latência (IO wait) e o ruído é audível. Há sinais.
No ecossistema NVMe, a falha raramente é progressiva no sentido observável pelo usuário final. O dispositivo depende inteiramente de elétrons presos em gates flutuantes e de um controlador complexo para interpretá-los. Se o controlador encontra uma exceção não tratada em seu firmware ou se a tabela de mapeamento na DRAM do SSD se corrompe, o drive não "fica lento". Ele entra em modo de pânico e desaparece do barramento PCIe, ou pior, reporta que a gravação foi um sucesso quando, na verdade, os dados foram descartados.
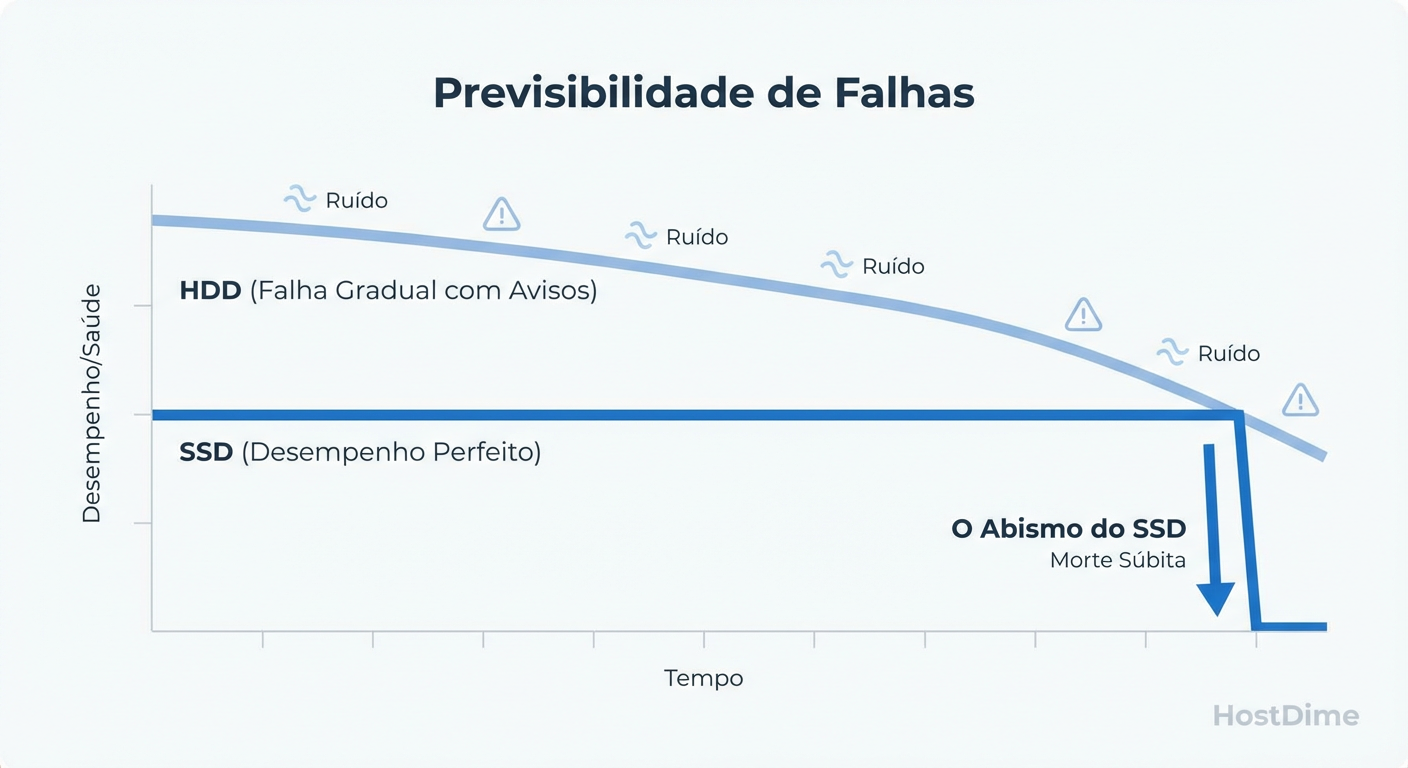 Figura: O Penhasco do SSD: A falha em estado sólido raramente é gradual. O drive funciona a 100% até o milissegundo em que o controlador entra em pânico e trava o acesso.
Figura: O Penhasco do SSD: A falha em estado sólido raramente é gradual. O drive funciona a 100% até o milissegundo em que o controlador entra em pânico e trava o acesso.
Este comportamento cria o "Penhasco do SSD". Não existe a curva suave de degradação que nos permite migrar dados calmamente. A métrica de "Health Percentage" no SMART é apenas uma estimativa de desgaste das células (wear leveling), não um preditor de falhas catastróficas do controlador ou de capacitores de proteção de energia.
A Camada de Tradução de Flash (FTL) e o Mapeamento Lógico
Para entender a irreversibilidade da perda de dados em NVMe, precisamos dissecar a Flash Translation Layer (FTL). O sistema operacional acredita estar escrevendo em blocos lógicos sequenciais (LBA 0, LBA 1, LBA 2). Fisicamente, isso é uma mentira.
Devido à necessidade de wear leveling (nivelamento de desgaste) e às características de write amplification da memória NAND, o SSD espalha os dados pelos chips de memória de forma caótica e fragmentada. O LBA 0 pode estar na página 400 do chip A, e o LBA 1 na página 12 do chip B. A FTL é o mapa que conecta essa bagunça.
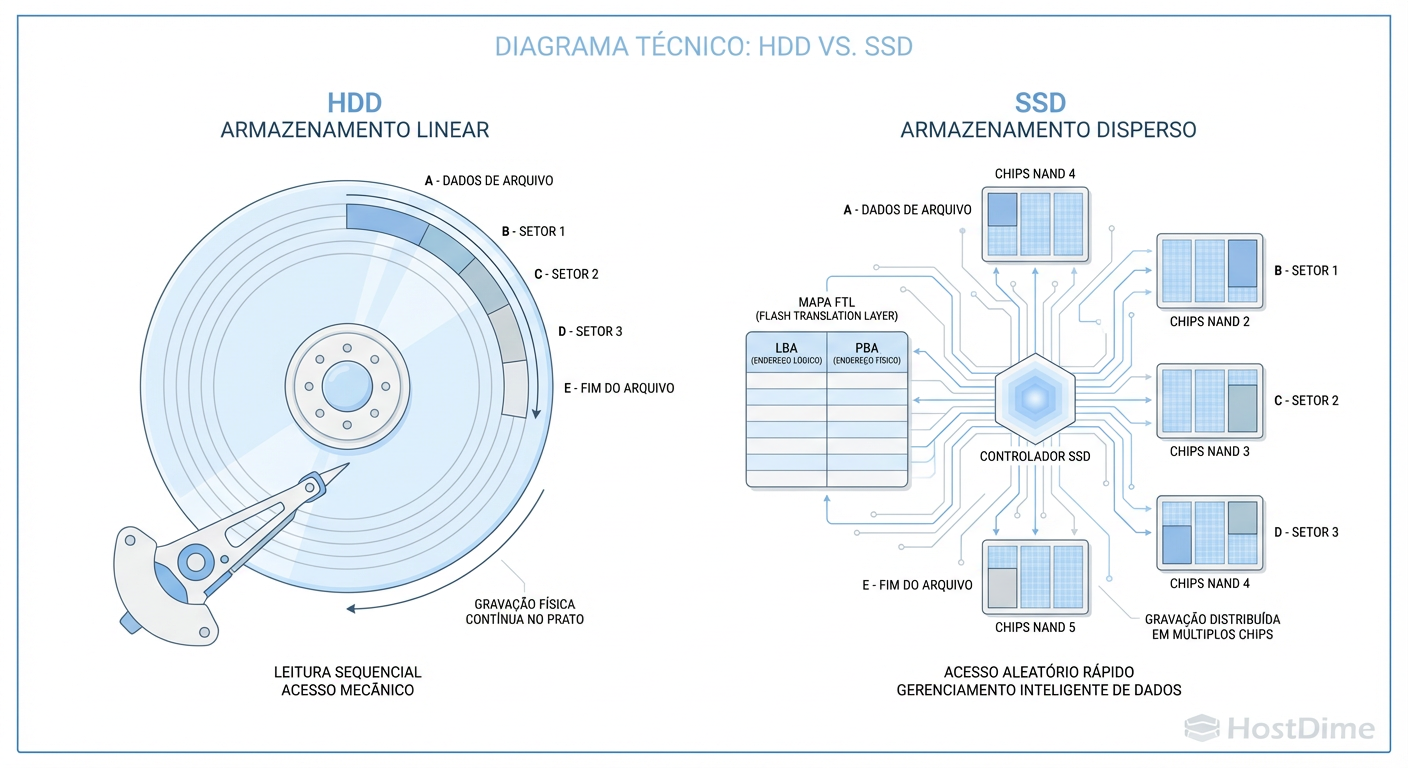 Figura: O Labirinto da FTL: Enquanto HDDs gravam linearmente, SSDs fragmentam intencionalmente os dados para nivelar o desgaste, tornando a recuperação crua (raw recovery) impossível sem o mapa.
Figura: O Labirinto da FTL: Enquanto HDDs gravam linearmente, SSDs fragmentam intencionalmente os dados para nivelar o desgaste, tornando a recuperação crua (raw recovery) impossível sem o mapa.
Se o controlador do SSD falha ou se a FTL é corrompida, você não tem mais um sistema de arquivos; você tem um sopão de bits criptografados e embaralhados. Em um HDD, a recuperação crua (raw recovery) funciona porque os dados são gravados linearmente. Em um SSD, sem a FTL intacta, a recuperação crua é impossível. Os dados não têm contiguidade física.
Bugs de Firmware e Colapsos Térmicos no Controlador NVMe
É vital internalizar este conceito: Um SSD NVMe não é um componente passivo; é um computador completo. Ele possui processadores multi-core (geralmente ARM), sua própria memória RAM (DRAM cache), um sistema operacional interno (firmware) e gerenciamento térmico complexo.
Como qualquer software complexo, o firmware de SSDs contém bugs. Em testes de estresse com cargas de trabalho mistas (leitura/escrita aleatória 4K com alta queue depth), observamos controladores entrarem em race conditions que resultam em:
Deadlocks: O drive para de responder a comandos NVMe, exigindo um power cycle físico para voltar (se voltar).
Silent Data Corruption (SDC): O drive confirma a gravação para o SO (ack), mas falha ao descarregar o buffer da DRAM para a NAND antes de um evento de energia ou falha lógica.
Throttling Térmico Agressivo: Controladores NVMe modernos operam em temperaturas altíssimas. Se o dissipador for inadequado, o controlador pode desligar subsistemas abruptamente para evitar danos físicos, interrompendo escritas em voo.
O Impacto do TRIM na Recuperação de Dados NVMe
A funcionalidade TRIM é excelente para a performance de longo prazo, mas é o carrasco da recuperação de dados. Quando você deleta um arquivo em um HDD, o sistema de arquivos apenas marca o ponteiro como "livre"; os dados magnéticos permanecem lá até serem sobrescritos.
Em um SSD NVMe com TRIM ativado (padrão na maioria dos OS modernos):
O SO envia o comando "deletar".
O comando TRIM notifica o controlador do SSD que aquelas páginas são inválidas.
O controlador, visando preparar células para futuras escritas rápidas, executa o Garbage Collection.
O resultado: As células são fisicamente apagadas ou desconectadas do mapa lógico quase imediatamente.
Se você tentar ler esses setores segundos após a deleção, o controlador retornará zeros determinísticos, não os dados antigos. Ferramentas de "undelete" são, na maioria dos casos, placebos em ambientes NVMe modernos. A exclusão é lógica e fisicamente finalizada em questão de segundos.
Bit Rot e a Física de Retenção em Células QLC e TLC
A densidade aumentou, e a confiabilidade física da célula individual diminuiu.
SLC (Single Level Cell): 1 bit por célula. Dois estados de voltagem. Robusto.
TLC (Triple Level Cell): 3 bits. 8 estados de voltagem.
QLC (Quad Level Cell): 4 bits. 16 níveis de voltagem distintos em uma carga microscópica de elétrons.
A diferença de voltagem entre um "0011" e um "0100" em uma célula QLC é infíma. Com o tempo, elétrons vazam (electron leakage). O mecanismo de ECC (Error Correction Code) do controlador trabalha furiosamente para corrigir esses erros de leitura em tempo real.
O problema surge em dados "frios" (arquivos gravados e nunca mais lidos). O Bit Rot silencioso ocorre quando a degradação da carga excede a capacidade do ECC. O drive não avisa que o arquivo está corrompido até você tentar lê-lo. Se o SSD ficar desligado (sem energia) por meses em um ambiente quente, a aceleração desse vazamento pode corromper dados massivamente, um fenômeno conhecido como degradação de retenção de dados.
Diagnóstico Avançado com nvme-cli e Logs Estendidos
Não confie em ferramentas gráficas genéricas que mostram apenas "SMART OK". Para diagnósticos reais em Linux, utilizamos o nvme-cli. Precisamos olhar para os contadores de erro brutos.
Instalação básica (Debian/Ubuntu/RHEL):
# Instalação da ferramenta padrão de mercado
sudo apt install nvme-cli # ou dnf install nvme-cli
O que medir para comprovar falhas
Execute o comando abaixo e procure pelos campos críticos:
sudo nvme smart-log /dev/nvme0n1
Interpretação Científica dos Campos:
media_errors: Se este número for maior que 0, entre em estado de alerta. Indica que o controlador tentou recuperar dados via ECC e falhou. O dado foi perdido.num_err_log_entries: Indica quantas vezes o controlador registrou um erro interno. Um aumento rápido aqui precede a morte do drive.critical_warning: Um bitmask. Qualquer valor diferente de 0 é inaceitável em produção.unsafe_shutdowns: Mostra quantas vezes o drive perdeu energia sem o comando de flush do buffer. Se alto, a integridade do sistema de arquivos é suspeita.
Para um teste de estresse controlado (cuidado: destrutivo se não isolado), ferramentas como fio podem verificar a consistência sob carga, mas o monitoramento passivo dos logs do controlador via nvme-cli é a melhor defesa diária.
Mitigando Riscos com Checksums de Sistema de Arquivos (ZFS)
Diante da natureza "caixa preta" do controlador NVMe e da possibilidade de corrupção silenciosa (onde o drive entrega lixo mas diz que entregou dados), a confiança cega no hardware é inaceitável para dados críticos.
Sistemas de arquivos tradicionais (ext4, XFS) confiam que o dispositivo de bloco é honesto. Se o SSD entrega um bit virado, o ext4 o aceita. A única defesa robusta é a validação de integridade na camada de software, acima do hardware.
A Necessidade do ZFS/Btrfs: O ZFS, por exemplo, grava um checksum de cada bloco de dados no ponteiro do bloco pai (Árvore de Merkle). Ao ler os dados:
O ZFS lê o bloco do NVMe.
Calcula o checksum em memória.
Compara com o checksum gravado.
Se houver divergência, ele sabe matematicamente que o SSD mentiu ou corrompeu o dado.
Sem essa camada de verificação, você está operando com base na fé de que milhões de células QLC microscópicas estão segurando seus elétrons perfeitamente.
Comparativo de Falha e Mitigação: HDD vs SSD NVMe
| Característica | HDD (Mecânico) | SSD NVMe (Eletrônico) |
|---|---|---|
| Modo de Falha | Frequentemente gradual, ruidoso, latência alta. | Súbito, silencioso, binário (funciona/morre). |
| Recuperação Crua | Possível (dados lineares nos pratos). | Impossível sem o mapa FTL do controlador. |
| Efeito do TRIM | Baixo (dados permanecem até sobrescrita). | Alto (dados zerados/descartados em segundos). |
| Sinal de Perigo | Reallocated Sectors, ruído. | media_errors, critical_warning, pânicos de IO. |
| Mitigação Ideal | RAID tradicional + Monitoramento SMART. | RAID Z (ZFS) + Checksums + Backups frequentes. |
Veredito Técnico
A performance do NVMe é sedutora, mas esconde um abismo de complexidade. Não projete sistemas de armazenamento baseados na premissa de que SSDs são apenas "discos rápidos". Eles são computadores complexos propensos a bugs de software e vazamento quântico de elétrons.
Para sobreviver a este cenário:
Monitore
media_errorsvianvme-cli, não apenas o status "OK" da GUI.Desconfie do hardware: use sistemas de arquivos com checksum (ZFS) sempre que a integridade for mais valiosa que a performance bruta.
Aceite que em NVMe, deletar é destruir. Backups 3-2-1 não são opcionais, são a única garantia contra a volatilidade da FTL.
Referências & Leitura Complementar
NVM Express Base Specification (Revision 2.0) - Detalhes sobre o conjunto de comandos e logs de erro SMART.
JEDEC JESD218 - Solid-State Drive (SSD) Requirements and Endurance Test Method.
Manpages:
man nvme,man nvme-smart-log.Schroeder, B. et al. - "Flash Reliability in Production: The Expected and the Unexpected" (USENIX FAST). Estudo de campo sobre taxas de erro reais em datacenters.

Alexandre Tavares
Operador de Storage em Rede (SAN/NAS)
"Respiro Fibre Channel e NVMe-oF. Meu foco é eliminar gargalos de I/O e otimizar rotas multipath para garantir que seus dados trafeguem com a menor latência possível."