Guia completo de hiperconvergência com Proxmox VE 8 e Ceph Reef

Aprenda passo a passo a configurar um cluster HCI de alta disponibilidade com 3 nós, Proxmox VE 8 e Ceph Reef. Guia prático de instalação, rede e troubleshooting.
A convergência de computação e armazenamento em uma única camada de software transformou radicalmente o datacenter moderno. Ao utilizar o Proxmox VE 8 em conjunto com o Ceph Reef, você elimina a necessidade de SANs proprietárias caras, criando uma infraestrutura hiperconvergente (HCI) resiliente, escalável e de nível empresarial, utilizando hardware padrão de mercado.
Neste guia, vamos construir um cluster de armazenamento distribuído do zero, focando nas melhores práticas de rede, seleção de discos e configuração de resiliência.
Resumo em 30 segundos
- Hiperconvergência (HCI): O Proxmox com Ceph permite que seus servidores processem VMs e armazenem dados simultaneamente, sem storage externo.
- Regra de Ouro: Um cluster Ceph estável exige no mínimo 3 nós para garantir quórum e evitar corrupção de dados (split-brain).
- Rede é Gargalo: Jamais misture tráfego de replicação de dados (Ceph Backend) com tráfego de usuários/VMs. Use redes físicas ou VLANs separadas, preferencialmente 10GbE+.
O conceito de arquitetura hiperconvergente no Proxmox
Diferente do armazenamento tradicional (RAID via Hardware), o Ceph é um Software Defined Storage (SDS). Ele não depende de controladoras RAID; na verdade, ele as detesta. O Ceph gerencia os dados diretamente no disco físico, distribuindo cópias (réplicas) através da rede para outros nós do cluster.
Se um disco falha, o Ceph recupera os dados de outros discos. Se um servidor inteiro falha, os dados continuam acessíveis nos nós remanescentes.
 Figura: Arquitetura lógica de um cluster de 3 nós: os dados são replicados via rede, eliminando o ponto único de falha.
Figura: Arquitetura lógica de um cluster de 3 nós: os dados são replicados via rede, eliminando o ponto único de falha.
Requisitos de hardware e preparação
Para este laboratório, assumimos um cenário de 3 nós (servidores). A performance do seu cluster será ditada pelo componente mais lento.
1. Discos e controladoras (HBA)
O erro mais comum ao iniciar com Ceph é usar controladoras RAID.
Obrigatório: Configure sua controladora de disco em modo IT Mode (Initiator Target) ou HBA (Host Bus Adapter). O Proxmox precisa ver o disco "cru" (raw device).
Enterprise vs. Consumer: SSDs de consumo (QLC/TLC sem DRAM cache) sofrem com a latência de escrita do Ceph. Para produção, use SSDs Enterprise (PLP) ou NVMe.
2. Topologia de rede
A latência de rede é o maior inimigo do Ceph.
Rede Pública (Front-end): Por onde as VMs e o Proxmox se comunicam.
Rede de Cluster (Back-end): Exclusiva para replicação de dados do Ceph (OSD replication). Se esta rede saturar, suas VMs travam.
💡 Dica Pro: Se você não possui switches 10GbE, mas tem portas 10GbE livres nos servidores, você pode criar uma rede Full Mesh (conexão direta cabo-a-cabo) entre os 3 nós para o tráfego de backend, economizando no switch.
Tabela comparativa: RAID Hardware vs. Ceph (HCI)
| Característica | RAID Hardware (Tradicional) | Ceph (Hiperconvergente) |
|---|---|---|
| Proteção | Contra falha de disco local. | Contra falha de disco E falha de servidor. |
| Hardware | Exige controladora RAID cara. | Exige HBA simples (Pass-through). |
| Expansão | Difícil (reconstrução lenta). | Ilimitada (basta adicionar nós/discos). |
| Recuperação | Lenta (gargalo no disco único). | Rápida (paralelizada por todos os discos). |
Passo 1: Preparação da rede
Antes de criar o cluster, defina IPs estáticos para a rede de armazenamento em cada nó. Vamos editar o arquivo /etc/network/interfaces.
Suponha que a interface eth1 seja sua placa dedicada de 10GbE para o Ceph:
auto eth1
iface eth1 inet static
address 10.10.10.1/24
# MTU 9000 (Jumbo Frames) é recomendado para Storage se o switch suportar
mtu 9000
Repita para pve2 (10.10.10.2) e pve3 (10.10.10.3).
Passo 2: Criando o cluster Proxmox
Com as redes configuradas, unifique os servidores em um cluster Proxmox. No console do pve1:
pvecm create cluster-lab
Nos outros nós (pve2 e pve3), solicite a entrada no cluster (use o IP da rede de gerenciamento, não a do Ceph ainda):
pvecm add IP_DO_PVE1
Verifique o status do quórum:
pvecm status
Você deve ver "Total votes: 3".
Passo 3: Instalando o Ceph Reef
O Proxmox VE 8 facilita drasticamente a instalação do Ceph via interface web, mas entender o processo é vital.
Acesse a GUI do Proxmox em qualquer nó.
Selecione o nó > Ceph > Install Ceph.
Escolha a versão Reef (18.2).
Repositório: Se não tiver licença Enterprise, certifique-se de alterar os repositórios para "No-Subscription" em Updates > Repositories antes de iniciar.
Configuração de rede do Ceph (Crítico)
O assistente perguntará sobre as redes. Aqui definimos a separação de tráfego:
Public Network: Selecione a rede de gerenciamento (ex: 192.168.1.0/24).
Cluster Network: Selecione a rede dedicada que criamos no Passo 1 (ex: 10.10.10.0/24).
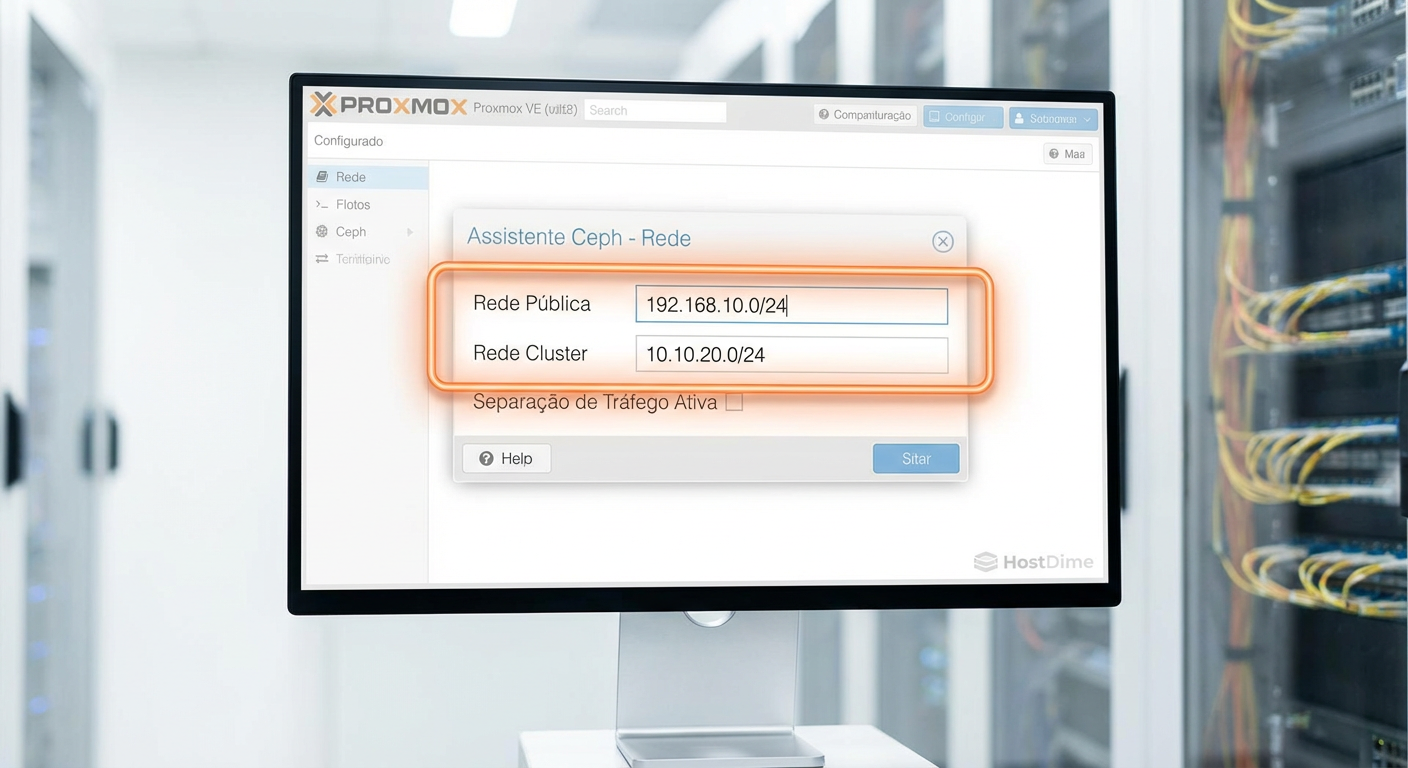 Figura: A separação física ou lógica das redes é vital para a estabilidade do cluster.
Figura: A separação física ou lógica das redes é vital para a estabilidade do cluster.
Após concluir o assistente no primeiro nó, o Proxmox instalará os pacotes. Repita o processo de instalação do Ceph (menu Ceph > Install) nos outros dois nós para que todos tenham os binários necessários. Em seguida, crie os Monitores (MON) e Managers (MGR) nos nós 2 e 3 através da aba "Monitor".
⚠️ Perigo: Um cluster Ceph deve ter sempre um número ímpar de Monitores (MONs) para estabelecer quórum. Em um setup de 3 nós, você deve ter 3 MONs ativos (um em cada servidor).
Passo 4: Provisionando OSDs (Object Storage Daemons)
Agora vamos entregar os discos físicos ao Ceph.
Vá em Ceph > OSD.
Clique em Create: OSD.
Selecione o disco físico disponível (ex:
/dev/sdb).DB/WAL Device (Opcional mas Recomendado): Se você tiver um SSD/NVMe sobrando e seus discos de dados forem HDDs mecânicos, você pode colocar o Database e o Write Ahead Log no disco rápido. Isso acelera drasticamente a performance de escrita.
- Se for tudo SSD, deixe em branco (o DB/WAL ficará no próprio disco).
Repita isso para todos os discos em todos os nós. Ao final, você verá uma lista de OSDs com status "up" e "in".
Passo 5: Pools e regras de replicação
O Ceph organiza dados em Pools. O Proxmox cria automaticamente um pool para armazenamento de VMs, geralmente com as seguintes configurações padrão:
Size: 3 (Três cópias do dado).
Min_size: 2 (Mínimo de cópias para aceitar escrita).
Isso significa que, se você gravar um arquivo, ele será copiado para o Nó 1, Nó 2 e Nó 3.
 Figura: O algoritmo CRUSH garante que as cópias dos dados nunca fiquem no mesmo servidor físico.
Figura: O algoritmo CRUSH garante que as cópias dos dados nunca fiquem no mesmo servidor físico.
Para verificar o status de saúde e a distribuição dos dados via terminal:
ceph -s
ceph osd tree
Passo 6: Validando a resiliência (Chaos Engineering)
Não confie na configuração até testá-la. Vamos simular uma falha.
Crie uma VM de teste e armazene-a no Ceph. Inicie a VM.
Enquanto a VM roda, desconecte o cabo de rede (ou desligue abruptamente) um dos nós (ex: pve3).
A VM deve continuar rodando sem interrupção no pve1 ou pve2.
Verifique o status no terminal de um nó sobrevivente:
ceph -s
O status mudará de HEALTH_OK para HEALTH_WARN. Você verá objetos marcados como degraded (degradados), pois agora existem apenas 2 cópias dos dados, não 3.
Ao religar o nó pve3, o Ceph detectará o retorno e iniciará o processo de Recovery/Rebalance, sincronizando apenas os dados que foram alterados durante o tempo de inatividade.
 Figura: O autocura (self-healing) é automático: assim que o nó retorna, o Ceph sincroniza os dados.
Figura: O autocura (self-healing) é automático: assim que o nó retorna, o Ceph sincroniza os dados.
O que fazer quando a saúde degrada?
Se o comando ceph -s retornar HEALTH_ERR (Erro Crítico), a operação de escrita pode ser bloqueada para proteger a integridade dos dados.
Verifique os OSDs:
ceph osd treemostrará qual disco está "down".Reinicie o serviço: Às vezes, um OSD trava por uso excessivo de memória.
systemctl restart ceph-osd@<ID>Disco Morto: Se o disco falhou fisicamente:
- Marque como out:
ceph osd out <ID> - Remova do mapa CRUSH:
ceph osd crush remove osd.<ID> - Remova a chave de autenticação:
ceph auth del osd.<ID> - Substitua o disco físico e recrie o OSD via GUI.
- Marque como out:
Perspectiva futura
A hiperconvergência com Proxmox e Ceph deixou de ser uma "alternativa barata" para se tornar uma escolha técnica superior em muitos cenários. Com a aquisição da VMware pela Broadcom em 2023/2024 e as mudanças drásticas de licenciamento, a migração para soluções baseadas em KVM e Ceph acelerou exponencialmente. Dominar esta stack não é apenas útil para seu Home Lab, é uma competência cada vez mais exigida no mercado Enterprise.
Perguntas Frequentes (FAQ)
Posso montar um cluster Ceph com apenas 2 nós?
Tecnicamente é possível ajustar omin_size para 1, mas é altamente desencorajado. O Ceph precisa de quórum (mínimo de 3 monitores) para evitar situações de "split-brain", onde ambos os nós acham que são o mestre e corrompem os dados. Se você tem apenas 2 servidores, use ZFS com replicação, não Ceph.
É obrigatório usar rede de 10GbE?
Para ambientes produtivos ou com SSDs, sim. A latência de redes 1GbE causa gargalos severos na replicação e, principalmente, durante a recuperação (rebalance) de falhas. Em 1GbE, a performance das VMs cairá drasticamente enquanto o cluster tenta se recuperar.Posso misturar SSDs e HDDs no mesmo pool?
Não é recomendado. O desempenho do pool será nivelado pelo disco mais lento (o HDD). A prática correta é criar pools separados (ex: um pool "Gold" só com SSDs para OS e Banco de Dados, e um "Silver" com HDDs para arquivos frios) e definir regras CRUSH específicas para cada um.
Roberto Sato
Planejador de Capacidade
"Traduzo métricas de consumo em modelos de crescimento sustentável. Minha missão é antecipar gargalos e garantir que sua infraestrutura escale matematicamente antes de atingir o limite crítico."