Guia de servidor de IA caseiro: hardware e armazenamento para LLMs locais

Monte seu próprio ChatGPT privado. Guia prático de hardware para Home Lab: do dilema RTX 3090 vs Tesla P40 ao impacto do NVMe no carregamento de modelos Llama 3.
Guia de servidor de IA caseiro: hardware e armazenamento para LLMs locais
A nuvem é conveniente, mas a fatura no final do mês não é. Se você, assim como eu, cansou de pagar mensalidades para a OpenAI ou Anthropic apenas para testar prompts ou rodar automações simples, bem-vindo ao clube. Construir um servidor de IA em casa (Home Lab) deixou de ser um sonho distante de quem tem orçamento de datacenter e se tornou uma realidade acessível, suja de graxa térmica e incrivelmente divertida.
A soberania dos dados é o grande atrativo aqui. Nada sai da sua rede local. Seus documentos, suas fotos e seus segredos permanecem nos seus discos. Mas para fazer isso rodar sem engasgos, precisamos falar sério sobre hardware. Não adianta ter o melhor processador se o gargalo está na velocidade de leitura do disco ou na falta de memória de vídeo. Vamos montar esse monstrinho.
Resumo em 30 segundos
- VRAM é Rei: A memória da placa de vídeo define o tamanho do modelo que você pode rodar. 24GB é o "sweet spot" atual.
- Armazenamento Rápido: Modelos de IA são arquivos gigantes. NVMe é essencial para trocar de modelos rapidamente sem esperar minutos de carregamento.
- Largura de Banda: Para inferência local, a velocidade da memória (VRAM/RAM) importa mais que o clock do processador.
O gargalo da VRAM e a barreira dos 24GB
No mundo dos LLMs (Large Language Models), a memória de vídeo (VRAM) é o recurso mais escasso e valioso. Diferente de jogos ou renderização 3D, onde a GPU pode buscar texturas na RAM do sistema com pouca penalidade, na IA, se o modelo não couber inteiro na VRAM, a performance despenca de um penhasco.
Para nós, entusiastas de home lab, a barreira mágica são os 24GB de VRAM. Por que esse número? Porque é o limite das placas de consumo "acessíveis" (RTX 3090 e 4090) e permite rodar modelos de tamanho médio (como o Llama-3 70B) com uma quantização agressiva, ou modelos de 8B e 13B com folga total e alta precisão.
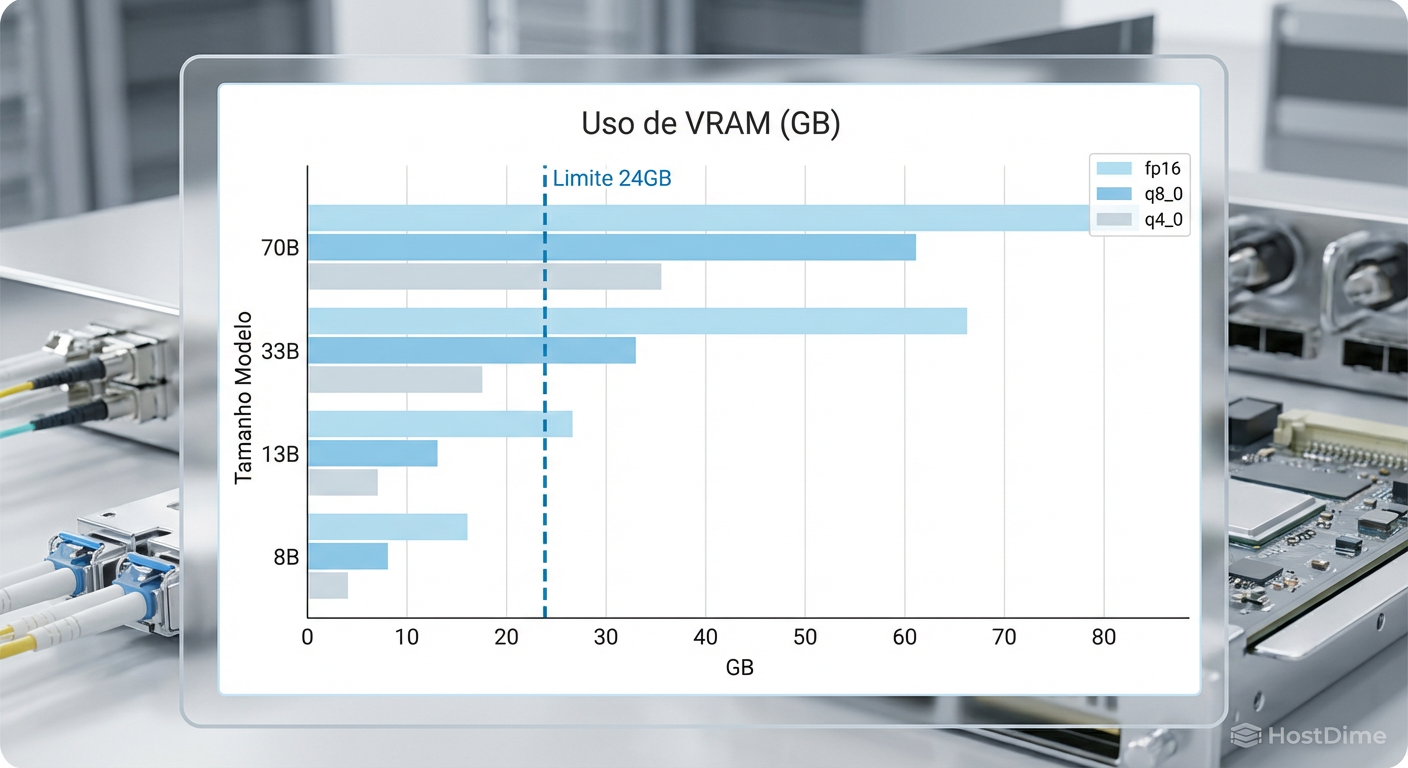 Figura: Gráfico comparativo de uso de VRAM por tamanho de modelo e nível de quantização, destacando o limite crítico de 24GB.
Figura: Gráfico comparativo de uso de VRAM por tamanho de modelo e nível de quantização, destacando o limite crítico de 24GB.
Se você tentar rodar um modelo maior do que sua placa aguenta, o sistema fará o "offloading" para a memória RAM do sistema (DDR4 ou DDR5). O resultado? A geração de texto cai de ágeis 50 tokens por segundo para dolorosos 2 ou 3 tokens por segundo. É a diferença entre conversar com alguém e esperar um telegrama.
Escolhendo a GPU: o mercado de usados e as gambiarras
Aqui é onde a mágica do custo-benefício acontece. Você não precisa hipotecar a casa para comprar uma RTX 4090 nova se o seu foco é apenas inferência (rodar a IA) e não treinamento pesado.
A Nvidia RTX 3090 usada é, sem dúvida, a rainha do home lab atual. Ela possui os mesmos 24GB de VRAM da 4090, mas custa uma fração do preço no mercado de segunda mão. A largura de banda da memória é excelente (quase 1 TB/s), o que é crucial para a velocidade da IA.
Mas se você gosta de viver perigosamente e economizar muito, existe a rota das GPUs de servidor antigas, como a Nvidia Tesla P40. Ela tem 24GB de VRAM e custa muito barato (frequentemente encontrada por menos de 200 dólares no eBay/AliExpress). O problema? Ela não tem ventoinhas. Ela foi feita para servidores com fluxo de ar de turbina.
💡 Dica Pro: Para usar uma Tesla P40 em um gabinete comum, você precisará imprimir em 3D um adaptador (shroud) e acoplar uma ventoinha de alta pressão estática (como uma ventoinha de servidor de 120mm). É barulhento, é feio, mas funciona maravilhosamente bem por um terço do preço de uma placa gamer.
 Figura: Uma Nvidia Tesla P40 com um adaptador de ventoinha impresso em 3D e preso com abraçadeiras: a solução clássica do home lab.
Figura: Uma Nvidia Tesla P40 com um adaptador de ventoinha impresso em 3D e preso com abraçadeiras: a solução clássica do home lab.
Comparativo de GPUs para IA Local
| GPU | VRAM | Largura de Banda | Custo (Estimado) | Veredito |
|---|---|---|---|---|
| RTX 4090 | 24GB GDDR6X | 1.008 GB/s | Alto | O sonho de consumo. Rápida e eficiente. |
| RTX 3090 | 24GB GDDR6X | 936 GB/s | Médio (Usada) | Melhor Custo-Benefício. A escolha padrão. |
| Tesla P40 | 24GB GDDR5 | 346 GB/s | Baixo | Requer gambiarra de refrigeração. Mais lenta, mas capaz. |
| RTX 3060 | 12GB GDDR6 | 360 GB/s | Baixo | Boa para começar com modelos pequenos (7B/8B). |
Armazenamento: onde o NVMe brilha
Muitos guias ignoram o armazenamento, focando apenas na GPU. Esse é um erro fatal. Os modelos de IA modernos são arquivos pesados. Um modelo de 70 bilhões de parâmetros quantizado pode ter 40GB. Se você gosta de testar vários modelos (o que você vai fazer), a velocidade de carregamento do disco para a VRAM é crítica.
Aqui, a latência e a taxa de transferência sequencial importam.
Cold Start (Partida a Frio): Quando você chama o Ollama para carregar um modelo que não está na memória, ele precisa ler gigabytes do disco e jogar na VRAM.
HDD Mecânico: Vai levar quase um minuto para carregar um modelo grande. A experiência é frustrante. O disco fica "moendo" enquanto você espera o cursor piscar.
SSD SATA: Melhor, reduzindo o tempo para 15-20 segundos.
NVMe Gen3/Gen4: A experiência é quase instantânea. O modelo carrega em poucos segundos.
⚠️ Perigo: Evite usar SSDs DRAM-less (sem cache DRAM) baratos para armazenar seus modelos se você faz muitas trocas. A leitura sustentada de arquivos grandes pode saturar o cache SLC desses discos, derrubando a velocidade para níveis de HDD.
Para um servidor de IA dedicado, recomendo um NVMe de 1TB ou 2TB exclusivo para os modelos. O diretório do Ollama (/usr/share/ollama/.ollama/models no Linux) cresce assustadoramente rápido. Separe o sistema operacional dos dados dos modelos. Isso facilita backups e reinstalações.
 Figura: Comparação visual do tempo de carregamento de modelos: NVMe vs SATA vs HDD.
Figura: Comparação visual do tempo de carregamento de modelos: NVMe vs SATA vs HDD.
Infraestrutura de suporte: PCIe e energia
Se você está montando um servidor com múltiplas GPUs (para somar VRAM e rodar modelos gigantescos de 120B+), as linhas PCIe (PCI Express) começam a importar.
Para inferência, a largura de banda do slot PCIe não é tão crítica quanto para treinamento. Você pode rodar uma RTX 3090 em um slot PCIe 3.0 x8 ou até x4 com uma perda de performance negligenciável na geração de texto. O modelo é carregado uma vez (uso de banda alto) e depois a comunicação é apenas de tokens de texto (uso de banda baixíssimo).
Isso é uma ótima notícia para quem usa placas-mãe antigas de servidores (Xeon v3/v4) ou quer usar "risers" (extensores) para pendurar as GPUs fora do gabinete por questões térmicas.
No entanto, a fonte de alimentação (PSU) não aceita desaforo. GPUs como a 3090 têm picos transientes de energia que podem desarmar fontes de baixa qualidade. Calcule o TDP da sua GPU, some 50% de margem e compre uma fonte de marca respeitável (Corsair, Seasonic, EVGA). Se for usar múltiplas GPUs, considere fontes de servidor com "breakout boards" para alimentar apenas as placas de vídeo, é mais barato e seguro.
Software: o caminho do pinguim
Esqueça o Windows para um servidor dedicado. O Linux (Ubuntu Server ou Debian) é a língua nativa da IA. O gerenciamento de memória é melhor, e o overhead do sistema é mínimo, deixando mais RAM livre para o offloading se necessário.
A ferramenta padrão-ouro hoje é o Ollama. Ele abstrai toda a complexidade de configurar o llama.cpp, baixar pesos e configurar parâmetros. É basicamente um Docker para LLMs.
A instalação no Linux é trivial, mas o "pulo do gato" está na instalação correta dos drivers proprietários da Nvidia. Sem eles, o Ollama vai rodar na CPU e você vai chorar.
nvidia-smi
Se esse comando retornar uma tabela bonita com o nome da sua placa e a versão do CUDA, você está pronto. Se der erro, pare tudo e corrija os drivers. Não tente rodar IA sem o nvidia-smi funcionando.
 Figura: O comando nvidia-smi é o batimento cardíaco do seu servidor de IA. Se ele aparece, está tudo vivo.
Figura: O comando nvidia-smi é o batimento cardíaco do seu servidor de IA. Se ele aparece, está tudo vivo.
Interpretando métricas: TPS e latência
Depois de tudo montado, como saber se está bom? Olhamos para duas métricas:
Tokens por Segundo (t/s): É a velocidade de leitura. Para leitura humana, qualquer coisa acima de 10 t/s é confortável. Acima de 30 t/s, a IA escreve mais rápido do que você consegue ler. Se estiver abaixo de 5 t/s, verifique se você não estourou a VRAM.
Time to First Token (TTFT): É a latência. O tempo entre você apertar "Enter" e a primeira letra aparecer. Isso é fortemente influenciado pela velocidade do seu processador (CPU) e pela latência da memória RAM/VRAM.
Se o seu TTFT é alto (demora para começar), mas o t/s é rápido (escreve rápido depois que começa), o problema geralmente é o processamento do prompt inicial (prefill), que depende bastante da computação bruta.
Recomendação final
Montar um servidor de IA local é um caminho sem volta. Você começa com um modelo pequeno de 8GB, se impressiona, e logo está procurando no eBay por mais uma placa de vídeo para fazer um par via NVLink ou apenas para somar VRAM e rodar o "Grok" ou o "Llama-3-70B" sem quantização.
Minha recomendação: comece com o armazenamento. Garanta um bom NVMe de 2TB e uma máquina base sólida com bastante RAM DDR4/DDR5 (mínimo 64GB se quiser brincar de offloading). A GPU você pode escalar depois. E cuidado com a conta de luz: esses modelos pensam rápido, mas o medidor de energia gira mais rápido ainda.
Perguntas Frequentes (FAQ)
Preciso de uma RTX 4090 ou 5090 para rodar IA local?
Não necessariamente. Para inferência (uso) de modelos, a quantidade de VRAM é mais crítica que o poder bruto de processamento. Uma RTX 3090 usada (24GB) oferece o melhor custo-benefício atual para home labs, entregando performance muito similar por uma fração do preço.Qual a diferença de performance entre SSD SATA e NVMe para IA?
A diferença é sentida principalmente no 'cold start' (carregamento inicial). Um modelo de 70B parâmetros pode levar quase um minuto para carregar via SATA, mas apenas alguns segundos via NVMe Gen4. Isso muda drasticamente a fluidez da experiência ao trocar de modelos.É possível rodar modelos maiores que a memória da minha placa de vídeo?
Sim, através do 'CPU Offloading', onde parte do modelo fica na RAM do sistema. Porém, a velocidade cai drasticamente (de 20+ tokens/s para 2-3 tokens/s) devido à menor largura de banda da memória DDR4/DDR5 comparada à VRAM da placa de vídeo.
Ricardo Garcia
Especialista em Virtualização (VMware/KVM)
"Vivo na camada entre o hypervisor e o disco. Ajudo administradores a entenderem como a performance do storage define a estabilidade de datastores, snapshots e migrações críticas."