Guia prático de Ceph: princípios operacionais para um cluster estável com Cephadm

Aprenda a implantar e operar um cluster Ceph resiliente (Reef/Squid). Tutorial passo a passo cobrindo cephadm, tuning de BlueStore, especificações de OSD e troubleshooting de performance.
O Ceph se consolidou como o padrão de fato para armazenamento definido por software (SDS) em ambientes Linux, oferecendo escalabilidade quase infinita para objetos, blocos e arquivos. No entanto, sua complexidade arquitetural muitas vezes intimida administradores de sistemas. Com a introdução do Cephadm, o gerenciamento do ciclo de vida do cluster foi simplificado, utilizando contêineres para orquestrar os serviços.
Este guia foca na construção de um cluster Ceph robusto, priorizando decisões de design que garantem estabilidade a longo prazo e facilidade de manutenção.
Resumo em 30 segundos
- Orquestração via Contêineres: O Cephadm elimina a necessidade de ferramentas externas como Ansible para o deploy básico, gerenciando daemons dentro de contêineres isolados.
- Rede é Crítica: A separação física ou lógica entre a "Public Network" (clientes) e a "Cluster Network" (replicação) é obrigatória para evitar latência em momentos de rebalance.
- Híbrido é Melhor: Em setups com HDDs, mover o WAL e o DB (metadados do BlueStore) para SSDs/NVMe é a mudança de maior impacto na performance.
Entendendo a arquitetura de consenso e monitores
Antes de digitar qualquer comando, é vital entender o "cérebro" do Ceph. O cluster opera sob um sistema de consenso Paxos gerenciado pelos Monitores (MONs). Eles mantêm o mapa do cluster (Cluster Map), que dita onde os dados estão fisicamente.
Para um cluster estável, você precisa de um número ímpar de monitores para evitar situações de split-brain.
Laboratórios/Testes: 1 Monitor (não recomendado para produção, pois se cair, o cluster para).
Produção Mínima: 3 Monitores (permite a falha de 1 nó sem interromper o serviço).
Produção em Larga Escala: 5 Monitores.
Os monitores não armazenam dados do usuário, apenas metadados da topologia. Portanto, eles exigem baixa latência de disco (use SSDs para o SO) e, crucialmente, relógios sincronizados.
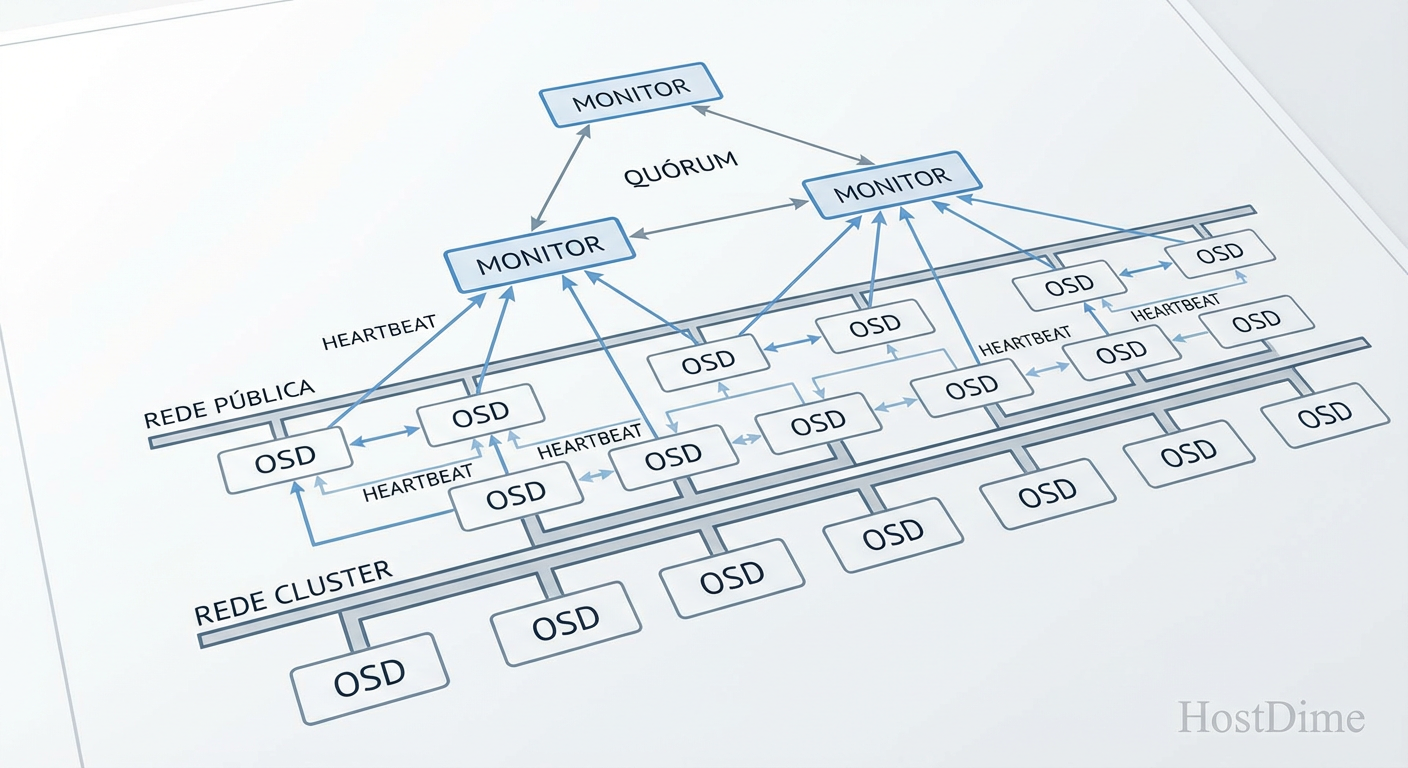 Figura: Arquitetura de alto nível: Monitores garantem o consenso enquanto OSDs gerenciam os dados.
Figura: Arquitetura de alto nível: Monitores garantem o consenso enquanto OSDs gerenciam os dados.
⚠️ Perigo: O Ceph é extremamente sensível à diferença de horário (clock skew). Se a diferença entre os nós for maior que 0.05 segundos, os monitores podem derrubar o quórum. Instale e configure o
chronyountpantes de qualquer outra coisa.
Preparação do ambiente e rede
A latência de rede é o maior inimigo do armazenamento distribuído. Quando um dado é gravado no Ceph, ele não é confirmado ao cliente até que todas as réplicas (geralmente 3) tenham sido gravadas nos discos dos outros nós.
Requisitos de hardware e SO
Para este guia, assumimos o uso de distribuições baseadas em Enterprise Linux (Rocky Linux 9, AlmaLinux 9) ou Ubuntu 22.04/24.04 LTS.
Runtime de Contêiner: O Cephadm exige Docker ou Podman.
Python 3: Necessário para a ferramenta de orquestração.
LVM2: Necessário para o provisionamento de discos.
sudo apt update && sudo apt install -y podman lvm2 chrony python3
# Exemplo no Rocky/AlmaLinux
sudo dnf install -y podman lvm2 chrony python3
Estratégia de rede dupla
Nunca misture tráfego de replicação (backend) com tráfego de clientes (frontend). Durante a recuperação de um disco falho, o tráfego de replicação pode saturar a rede, derrubando o acesso dos clientes se ambos compartilharem a mesma interface.
Public Network (Frontend): Onde seus servidores de aplicação (Proxmox, Kubernetes, etc.) acessam o storage.
Cluster Network (Backend): Onde os OSDs conversam entre si para replicar dados e enviar heartbeats.
💡 Dica Pro: Configure Jumbo Frames (MTU 9000) na Cluster Network. Isso reduz a sobrecarga da CPU ao transferir grandes blocos de dados durante a sincronização e recuperação (backfill).
Inicialização do cluster com cephadm
O cephadm cria um cluster funcional instalando o gerenciador e o monitor em um nó inicial (bootstrap node). Baixe o binário oficial:
curl --silent --remote-name --location https://github.com/ceph/ceph/raw/quincy/src/cephadm/cephadm
chmod +x cephadm
sudo ./cephadm add-repo --release quincy
sudo ./cephadm install
Nota: Substitua 'quincy' por 'reef' ou 'squid' conforme a versão desejada.
Agora, execute o bootstrap. Defina explicitamente o IP do monitor e a sub-rede do cluster para evitar que o Ceph tente adivinhar (e errar) qual interface usar.
sudo cephadm bootstrap --mon-ip 192.168.10.50 \
--cluster-network 10.10.10.0/24 \
--initial-dashboard-user admin \
--initial-dashboard-password 'SenhaForte123' \
--allow-fqdn-hostname
Após o comando finalizar, o Cephadm fornecerá a URL do dashboard e configurará as chaves SSH necessárias para adicionar outros nós.
Para adicionar novos nós ao cluster, copie a chave pública SSH gerada em /etc/ceph/ceph.pub para o authorized_keys dos novos servidores e execute:
# No nó de bootstrap (shell do cephadm)
sudo cephadm shell -- ceph orch host add node02 192.168.10.51
sudo cephadm shell -- ceph orch host add node03 192.168.10.52
Provisionamento declarativo de OSDs
O OSD (Object Storage Daemon) é a unidade fundamental de armazenamento. Geralmente, 1 disco físico = 1 OSD.
Em vez de adicionar discos manualmente um por um, o Cephadm utiliza especificações de serviço (Service Specs) em YAML. Isso permite definir regras como: "Todos os discos NVMe de 1TB em todos os nós devem ser OSDs".
Separação de WAL e DB (BlueStore)
O backend de armazenamento padrão, BlueStore, grava dados diretamente no disco bruto. No entanto, ele precisa de um pequeno espaço para Write Ahead Log (WAL) e metadados (DB).
Se você usa HDDs mecânicos (spinners), o desempenho de gravação aleatória será ruim. A solução é colocar o WAL e o DB em um SSD ou NVMe, enquanto os dados ficam no HDD.
 Figura: Diagrama esquemático: Offload de metadados para NVMe.
Figura: Diagrama esquemático: Offload de metadados para NVMe.
Crie um arquivo osd_spec.yaml:
service_type: osd
service_id: default_drive_group
placement:
host_pattern: '*'
data_devices:
rotational: 1
db_devices:
model: "Samsung SSD 980*"
Neste exemplo, o Ceph procurará em todos os hosts por discos rotacionais (HDD) para dados e usará qualquer SSD Samsung 980 disponível para armazenar o DB/WAL desses HDDs. O Ceph calcula automaticamente o particionamento do SSD.
Aplique a configuração:
sudo cephadm shell -- ceph orch apply -i osd_spec.yaml
Verifique o progresso:
sudo cephadm shell -- ceph orch ps --daemon_type osd
Ajuste fino de memória e placement groups
Um cluster recém-instalado raramente está otimizado para sua carga de trabalho específica. Dois parâmetros exigem atenção imediata: memória dos OSDs e o Autoscaler de PGs.
OSD Memory Target
O Ceph consome RAM para cache de leitura e estruturas internas. Por padrão, o osd_memory_target é conservador (cerca de 4GB). Se você tem RAM sobrando no servidor, aumente esse valor para melhorar a performance de leitura.
Para definir 8GB de RAM por OSD em todos os nós:
sudo cephadm shell -- ceph config set osd osd_memory_target 8589934592
💡 Dica Pro: A regra geral é: SO + (4GB por OSD) + (1GB por Monitor/MGR). Não aloque mais memória do que a física disponível, ou o servidor entrará em swap, destruindo a performance do storage.
Placement Groups (PGs)
Os PGs são baldes lógicos onde os objetos são agrupados antes de irem para os OSDs. PGs insuficientes causam má distribuição de dados; PGs demais desperdiçam CPU.
O Ceph moderno possui um autoscaler ativado por padrão. No entanto, ele é reativo. Se você sabe que vai encher o cluster rapidamente, avise o autoscaler.
Ao criar uma pool, defina o target_size_ratio. Por exemplo, se a pool rbd-vms vai ocupar 80% do cluster:
ceph osd pool create rbd-vms
ceph osd pool set rbd-vms target_size_ratio 0.8
Isso força o Ceph a pré-calcular o número ideal de PGs (geralmente visando 100 PGs por OSD) antes que os dados sejam gravados.
Validação de performance com rados bench
Não coloque o cluster em produção sem antes validar se ele entrega a velocidade esperada. O rados bench é a ferramenta nativa para isso. Ele testa a performance bruta do cluster, ignorando sistemas de arquivos ou camadas de bloco superiores.
Teste de Escrita (Write): Grava dados por 60 segundos.
# Dentro do shell do cephadm
ceph osd pool create benchmark 128
rados bench -p benchmark 60 write --no-cleanup
Observe o campo Average IOPS e Bandwidth.
Teste de Leitura (Read): Lê os dados gerados no teste anterior.
rados bench -p benchmark 60 seq
 Figura: Validação de throughput com rados bench.
Figura: Validação de throughput com rados bench.
Se a latência (latency) subir drasticamente durante o teste de escrita, verifique se seus discos de WAL/DB (NVMe) não estão saturados ou se a rede de cluster está engargalada.
Ao finalizar, limpe a sujeira:
ceph osd pool delete benchmark benchmark --yes-i-really-really-mean-it
Resolução de problemas comuns
Mesmo com um design perfeito, hardware falha. Veja como lidar com os cenários mais comuns.
OSD Degradado ou Falho
Se um disco morrer, o Ceph marcará o OSD como down e out. O cluster entrará em estado HEALTH_WARN.
Identifique o disco físico:
ceph osd treeProcure pelo OSD marcado como
down. Anote o ID (ex:osd.4) e o host.Verifique o LED do disco no servidor físico (se disponível):
ceph device light on osd.4Substituição segura com Cephadm: O Cephadm tenta automatizar a substituição se o
device_health_metricsdetectar falha. Se for manual, você deve "zapar" (limpar) o disco novo e o Cephadm, seguindo oosd_spec.yamlque criamos antes, irá automaticamente provisioná-lo como um novo OSD.# Liste os discos no host para confirmar o caminho do novo disco ceph orch device ls node02 # Limpe qualquer partição antiga se necessário ceph orch device zap node02 /dev/sdX --force
Monitores fora do Quórum
Se ceph -s mostrar mon_status: 2/3 mons, você perdeu um monitor.
Verifique espaço em disco no nó do monitor (
/var/lib/ceph). O banco de dados do monitor (RocksDB) pode corromper se o disco encher.Verifique a conectividade na porta 6789 e 3300.
Se o monitor estiver irremediavelmente corrompido, remova-o do cluster e adicione um novo em outro nó para restaurar a redundância.
Recomendação final
Operar um cluster Ceph exige disciplina. A automação do Cephadm removeu grande parte da dor de cabeça da instalação, mas não elimina a necessidade de monitoramento.
Para ambientes de produção, recomendo fortemente a integração do Prometheus e Grafana (que o Cephadm pode instalar com um comando) e a configuração de alertas para ocupação de disco acima de 75%. O Ceph começa a degradar performance e bloquear operações de escrita quando os discos ficam muito cheios, e recuperar um cluster 100% cheio é uma tarefa complexa e arriscada. Mantenha sempre capacidade de reserva.

Roberto Esteves
Especialista em Segurança Defensiva
"Com 15 anos de experiência em Blue Team, foco no que realmente impede ataques: segmentação, imutabilidade e MFA. Sem teatro de segurança, apenas defesa real e robusta para infraestruturas críticas."