HCI vs SAN: A verdade sobre TCO e complexidade além do marketing

Descubra quando a hiperconvergência simplifica e quando ela cria gargalos. Uma análise de arquiteto sobre HCI, SAN, NVMe-oF e o impacto do licenciamento Broadcom no TCO real.
A narrativa predominante na última década sugeriu que a arquitetura de três camadas — servidores, rede de armazenamento e arrays dedicados (SAN) — era um artefato jurássico, destinado à extinção pela meteórica ascensão da Infraestrutura Hiperconvergente (HCI). A promessa era sedutora: a simplicidade operacional de um "Google in a box", onde o armazenamento é apenas mais uma aplicação rodando no hypervisor.
No entanto, arquitetura de software e hardware é, fundamentalmente, a arte de gerenciar trade-offs. Não existe solução mágica, apenas escolhas que redistribuem a complexidade e o custo para diferentes camadas da pilha. Ao consolidarmos compute e storage no mesmo chassi, resolvemos problemas de latência de rede legada, mas introduzimos novas variáveis de contenda de recursos e rigidez de escala que, em 2025, estão forçando muitos CIOs e arquitetos a reabrirem suas planilhas de TCO (Custo Total de Propriedade).
Resumo em 30 segundos
- A Taxa Oculta de CPU: A replicação síncrona e os serviços de dados (deduplicação/compressão) em HCI consomem ciclos de CPU que seriam das aplicações, criando uma "latência de cauda" imprevisível.
- O Dilema da Escala: HCI exige a compra de "blocos" contendo CPU e RAM mesmo quando você só precisa de armazenamento, gerando recursos órfãos e custos de licenciamento desnecessários.
- O Retorno do Desacoplamento: Tecnologias como NVMe-oF (NVMe over Fabrics) permitem latências locais em arquiteturas desagregadas, anulando a principal vantagem técnica da hiperconvergência.
A falácia da simplicidade operacional no "Day 2"
A venda da hiperconvergência geralmente ocorre na demonstração do "Day 0" e "Day 1": o deploy rápido. É inegável que tirar quatro nós da caixa e ter um cluster funcional em 45 minutos é impressionante. Contudo, a realidade operacional de uma empresa vive no "Day 2" — a manutenção contínua, patches, upgrades e troubleshooting.
Em um ambiente HCI, o plano de controle de armazenamento e o hypervisor estão intrinsecamente acoplados. Uma atualização crítica de firmware nos discos ou na controladora HBA (Host Bus Adapter) exige uma validação cruzada rigorosa com a versão do Software-Defined Storage (SDS) e a versão do hypervisor.
⚠️ Perigo: A matriz de compatibilidade em ambientes HCI é exponencialmente mais frágil que em SANs tradicionais. Atualizar o hypervisor para corrigir uma CVE de segurança pode, inadvertidamente, quebrar a compatibilidade com a versão atual do seu software de armazenamento, deixando o cluster em um estado não suportado ou instável.
Diferente de um array de armazenamento dedicado, que pode ser atualizado de forma independente e transparente para os hosts (via multipathing), a manutenção em um nó HCI frequentemente exige a evacuação de dados ou a ressincronização massiva após o reboot, colocando pressão intensa sobre a rede de backend e elevando o risco operacional durante janelas de manutenção.
Anatomia do I/O Path: O impacto da replicação síncrona
Para entender o verdadeiro custo da hiperconvergência, precisamos descer ao nível do silício. Em uma SAN moderna, o processamento de I/O — cálculos de paridade RAID, deduplicação, compressão e encriptação — é descarregado para controladores dedicados (ASICs ou FPGAs) dentro do storage array.
Na HCI, não existe mágica: esse trabalho deve ser feito por alguém. Esse "alguém" é a CPU do seu servidor, a mesma que deveria estar processando transações do banco de dados ou servindo requisições web. Chamamos isso de "imposto de virtualização de armazenamento".
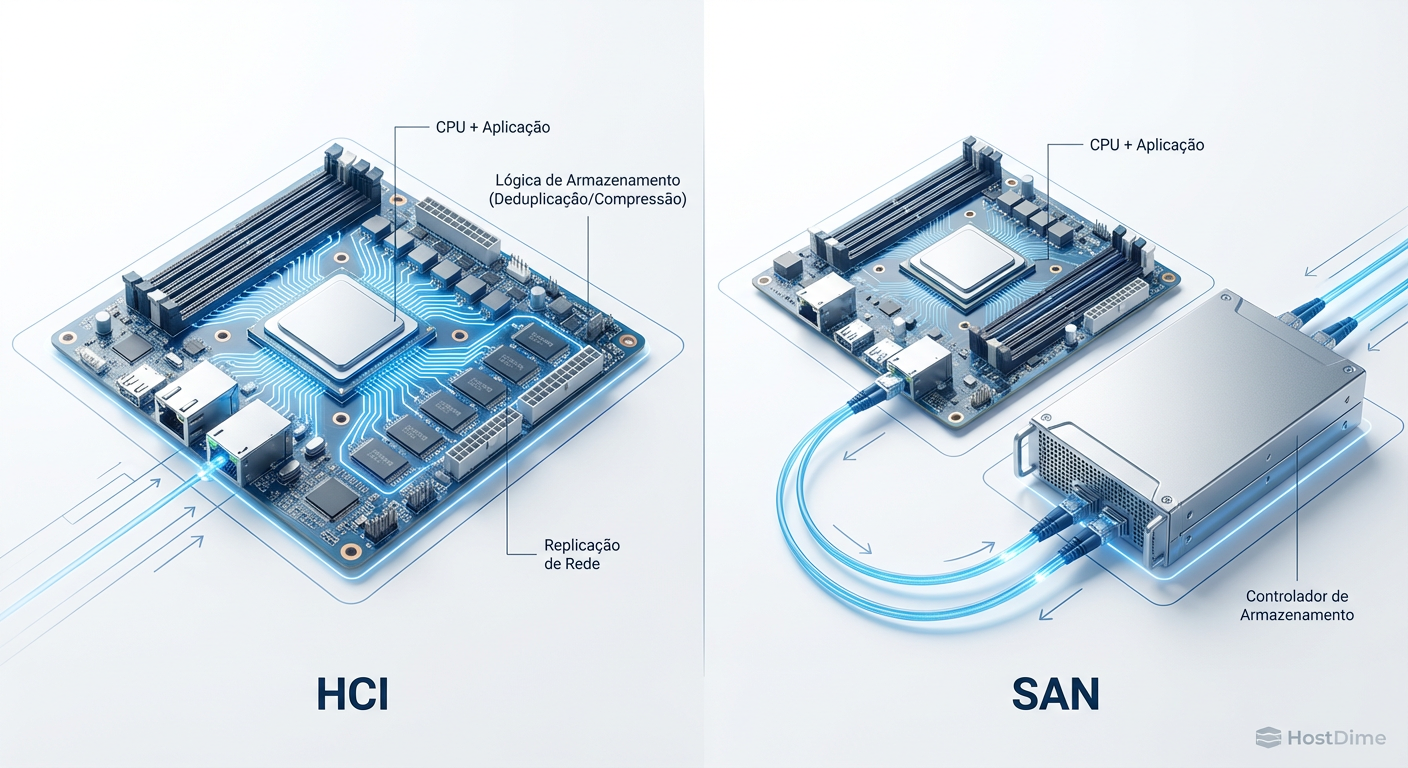 Figura: Comparativo de Caminho de I/O: Note como a HCI (esquerda) compete por ciclos de CPU do host, enquanto a SAN (direita) isola a carga de trabalho de armazenamento.
Figura: Comparativo de Caminho de I/O: Note como a HCI (esquerda) compete por ciclos de CPU do host, enquanto a SAN (direita) isola a carga de trabalho de armazenamento.
Como ilustrado acima, o problema se agrava com a replicação síncrona. Para garantir alta disponibilidade, cada write (escrita) deve ser confirmado em pelo menos dois nós distintos antes de ser considerado concluído. Isso gera um tráfego "Leste-Oeste" massivo na rede. Se seus links de 25GbE ou 100GbE estiverem saturados, ou se a CPU do nó vizinho estiver ocupada, a latência de escrita da sua aplicação dispara.
Isso cria o fenômeno da "Latência de Cauda" (Tail Latency). A média de latência pode parecer boa, mas os picos (o percentil 99) tornam-se erráticos devido à contenda por recursos compartilhados. Para cargas de trabalho de missão crítica sensíveis à latência, essa imprevisibilidade é inaceitável.
A armadilha dos recursos órfãos e o problema da escala linear
A premissa da HCI é a escalabilidade linear baseada em blocos (nodes). Se você precisa de mais recursos, adiciona mais um nó. O problema é que as cargas de trabalho reais raramente crescem de forma linear e simétrica.
Imagine um cenário comum: sua empresa precisa arquivar 500 TB de logs de conformidade ou imagens médicas. A demanda é puramente por capacidade de armazenamento (Storage), com pouca necessidade de processamento (Compute). Em uma arquitetura HCI rígida, para adicionar esses 500 TB, você é forçado a comprar nós que vêm equipados com CPUs de última geração e terabytes de RAM que ficarão ociosos.
💡 Dica Pro: Analise a métrica de "Densidade de Armazenamento por Core". Se sua necessidade de armazenamento cresce 20% ao ano, mas sua necessidade de computação cresce apenas 5%, a HCI forçará você a desperdiçar orçamento em processadores que nunca serão utilizados plenamente.
Esses são os "recursos órfãos". Você pagou por eles (CapEx), você paga energia para alimentá-los (OpEx), mas eles não geram valor. Em contraste, uma arquitetura desagregada permite adicionar uma gaveta de discos (JBOD/JBOF) ao seu array existente por uma fração do custo de novos nós de servidor.
O renascimento da arquitetura de três camadas via NVMe-oF
Por anos, o argumento contra a SAN era a latência introduzida pela rede e pelo protocolo SCSI. Entretanto, a evolução dos protocolos de transporte mudou radicalmente esse cenário. O advento do NVMe over Fabrics (NVMe-oF) eliminou as ineficiências da pilha SCSI legada.
Com NVMe-oF (seja via Fibre Channel, RoCE v2 ou TCP), conseguimos acessar o armazenamento remoto com latências quase idênticas às de um SSD conectado localmente via PCIe.
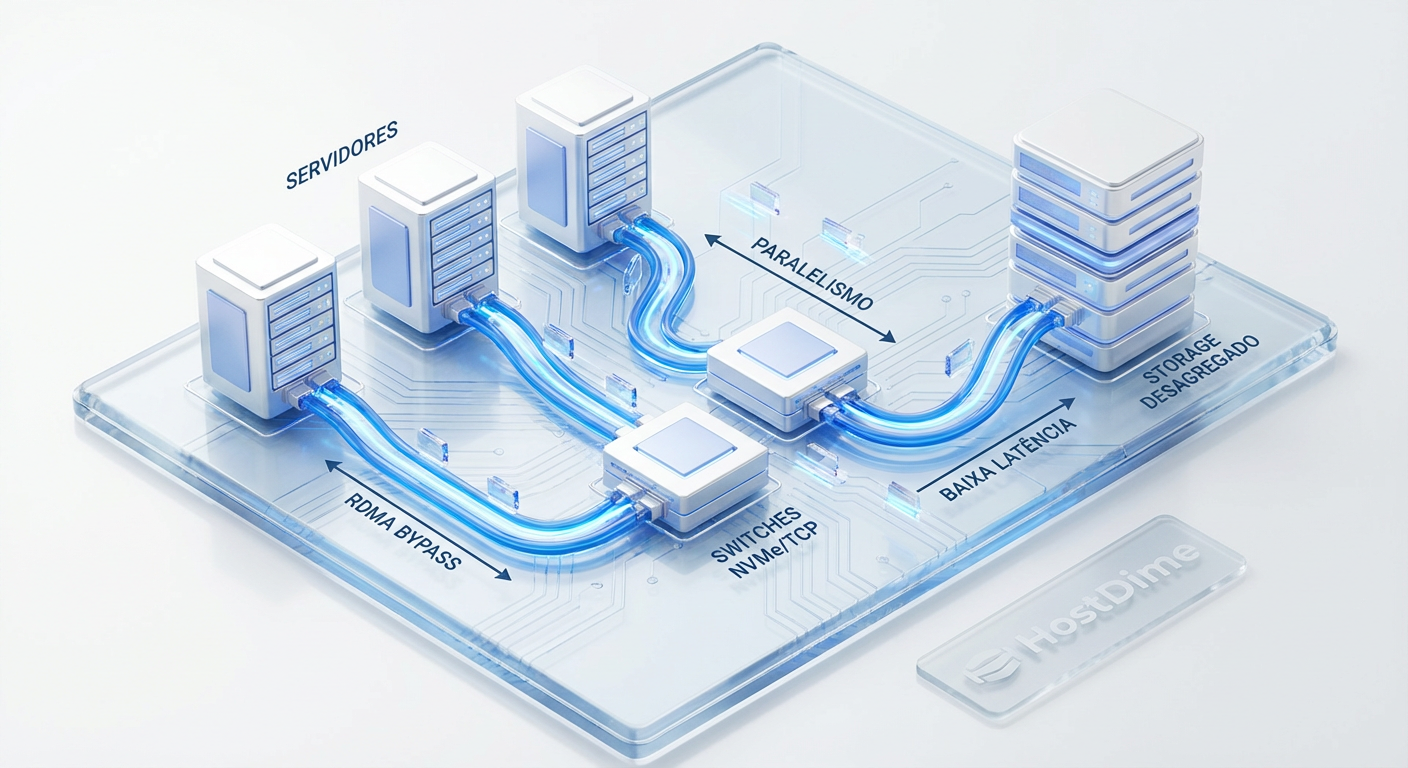 Figura: Topologia NVMe-oF: O uso de RDMA e paralelismo massivo permite que o armazenamento externo tenha performance de armazenamento local.
Figura: Topologia NVMe-oF: O uso de RDMA e paralelismo massivo permite que o armazenamento externo tenha performance de armazenamento local.
Essa tecnologia permite o que chamamos de dHCI (Disaggregated Hyper-Converged Infrastructure) ou simplesmente o retorno da arquitetura de três camadas modernizada. Você mantém a gestão centralizada (o benefício de software da HCI), mas recupera a flexibilidade de hardware de escalar computação e armazenamento de forma independente.
O protocolo NVMe foi desenhado para o paralelismo dos SSDs modernos, suportando 64 mil filas de comando, contra a fila única do AHCI/SCSI. Ao desacoplar o armazenamento sem penalidade de performance, removemos o "ruído" do armazenamento da CPU do host, devolvendo ciclos preciosos para as aplicações.
O novo cálculo de TCO na era do licenciamento por núcleo
Talvez o fator mais crítico em 2025/2026 não seja técnico, mas financeiro. As mudanças agressivas nos modelos de licenciamento de hypervisors (notadamente após a aquisição da VMware pela Broadcom) alteraram a matemática do TCO.
A maioria dos softwares de infraestrutura moderna (Hypervisors, Bancos de Dados como SQL Server e Oracle) é licenciada por núcleo de CPU (per-core).
Em um ambiente HCI, para expandir o armazenamento, você adiciona nós com mais CPUs. Imediatamente, você aumenta sua conta de licenciamento de software, mesmo que aquelas CPUs estejam ali apenas para gerenciar discos.
 Figura: Análise de TCO em 5 anos: O custo de licenciamento por núcleo (parte escura das barras) torna a escala da HCI financeiramente inviável para grandes volumes de dados.
Figura: Análise de TCO em 5 anos: O custo de licenciamento por núcleo (parte escura das barras) torna a escala da HCI financeiramente inviável para grandes volumes de dados.
Ao separar o armazenamento em um array dedicado (que roda seu próprio sistema operacional, muitas vezes com licenciamento incluído no hardware ou baseado em capacidade bruta), você pode manter seus hosts de computação "magros", com alta densidade de VMs e o número exato de núcleos necessários para a carga de trabalho. Isso resulta em uma economia direta e massiva nas renovações de contrato de software Enterprise.
Considerações Finais
A hiperconvergência tem seu lugar. Para filiais (ROBO), VDI (Virtual Desktop Infrastructure) ou ambientes de médio porte onde a simplicidade de gestão supera a eficiência de custo, ela continua sendo uma solução robusta.
No entanto, tratar HCI como o padrão de facto para qualquer carga de trabalho Enterprise é um erro arquitetural caro. Quando escalamos para petabytes ou quando a performance determinística é inegociável, a física e a economia favorecem a desagregação.
Minha recomendação é pragmática: pare de desenhar sua infraestrutura baseada em tendências de marketing de 2015. Avalie o custo do licenciamento por núcleo, calcule a sobrecarga de CPU da replicação síncrona e considere se a flexibilidade do NVMe-oF não oferece o melhor dos dois mundos. A complexidade que você elimina no rack com HCI muitas vezes retorna como complexidade na renovação do contrato de software.
Referências & Leitura Complementar
NVM Express Base Specification 2.0: Detalhes técnicos sobre a arquitetura NVMe e transportes de fabric. Disponível em nvmexpress.org.
SNIA (Storage Networking Industry Association): "Performance Implications of Storage Class Memory and NVMe-oF". Whitepaper técnico.
VMware Performance Engineering: "vSAN Performance Best Practices" (Documento técnico detalhando o overhead de CPU e recomendações de hardware).
JEDEC SSD Specifications: Padrões para form factors e interfaces de SSDs Enterprise (U.2, E1.S).

Otávio Henriques
Arquiteto de Soluções Enterprise
"Com duas décadas desenhando infraestruturas críticas, olho além do hype. Foco em TCO, resiliência e trade-offs, pois na arquitetura corporativa a resposta correta quase sempre é 'depende'."