IA Agêntica: O Fim do Armazenamento Frio e a Era da Memória Universal

Descubra como a IA Agêntica está quebrando a barreira entre RAM e SSD. Uma análise futurista sobre CXL 3.1, bancos vetoriais e o novo tier de memória 'G3.5' para infraestrutura de dados.
Estamos testemunhando uma inversão de polaridade na infraestrutura de computação. Até ontem, o foco obsessivo estava no treinamento de modelos massivos (LLMs), onde a taxa de transferência sequencial (throughput) era rainha e o armazenamento servia apenas como um vasto repositório estático. Esse paradigma acabou. A ascensão da IA Agêntica — sistemas autônomos que não apenas "falam", mas executam tarefas complexas por dias ou semanas — está reescrevendo as leis da física do data center.
Neste novo cenário, o armazenamento frio está obsoleto. Se um dado não pode ser acessado em microssegundos para fornecer contexto a um agente, ele é inútil. Estamos caminhando para uma arquitetura onde a distinção entre RAM e SSD se dissolve, criando um tecido contínuo de "Memória Universal".
Resumo em 30 segundos
- Mudança de Paradigma: A IA Agêntica exige persistência de estado e memória de longo prazo, transformando o armazenamento de um "arquivo morto" em uma extensão ativa da RAM.
- O Fator CXL: O protocolo CXL (Compute Express Link) é a peça chave que permite desacoplar a memória da CPU, criando pools de memória tierizada que preenchem o abismo entre a DRAM e o SSD.
- Morte da Latência: Bancos de dados vetoriais exigem milhões de IOPS aleatórios; discos rígidos (HDDs) e até SSDs SATA não têm lugar nessa nova hierarquia de "Hot Tier" expandido.
A anatomia do agente e o colapso da memória local
Para entender o impacto no hardware, precisamos dissecar o software. Um chatbot tradicional é "stateless" (sem estado); você faz uma pergunta, ele responde e esquece. Um Agente de IA é "stateful" (com estado). Ele precisa lembrar de planos, ferramentas, resultados intermediários e erros passados.
Imagine um agente de codificação encarregado de refatorar um sistema legado de 1 milhão de linhas. Ele não pode carregar tudo na memória HBM (High Bandwidth Memory) da GPU, que custa uma fortuna e é escassa. A HBM, como a HBM3e, é rápida, mas limitada em capacidade (geralmente 80GB a 144GB por acelerador).
O agente precisa de um "cérebro estendido". Ele precisa despejar memória de curto prazo para um armazenamento persistente e recuperá-la instantaneamente. Aqui surge o problema: a latência. Se o agente tiver que esperar 10 milissegundos para buscar um contexto no disco, o processo de raciocínio "engasga". Multiplique isso por milhares de passos de raciocínio e o sistema se torna inviável.
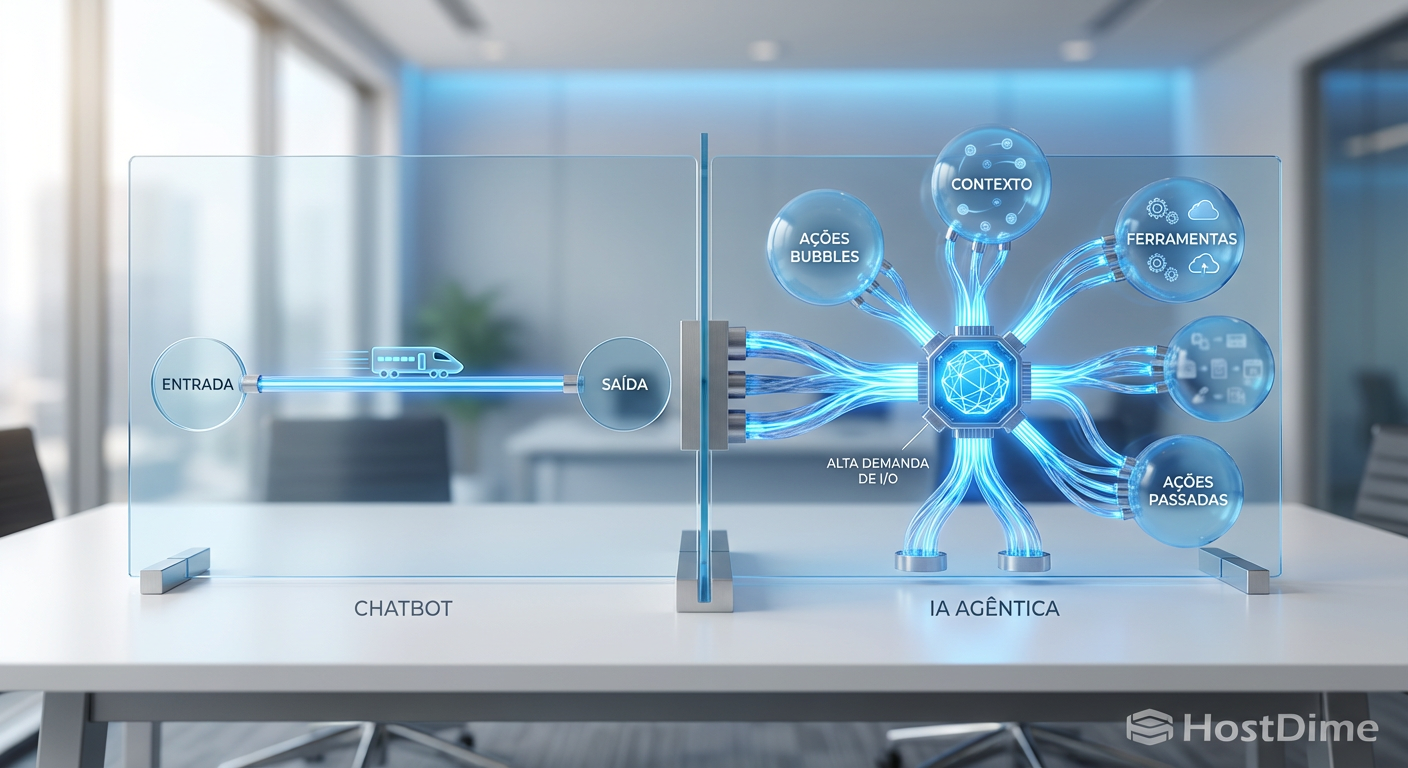 Figura: Comparativo visual entre o fluxo linear de um Chatbot e a complexidade de acesso à memória de uma IA Agêntica.
Figura: Comparativo visual entre o fluxo linear de um Chatbot e a complexidade de acesso à memória de uma IA Agêntica.
💡 Dica Pro: Em ambientes de IA Agêntica, monitore a "Latência de Cauda" (Tail Latency), especificamente o percentil 99 (p99). Um SSD que é rápido na média, mas lento em 1% das requisições, destruirá a performance do agente.
CXL 3.1: A ponte para a memória infinita
A indústria de hardware respondeu a esse gargalo com o CXL (Compute Express Link). Se você trabalha com infraestrutura e ainda não está planejando para CXL, você está planejando para o passado.
O CXL utiliza a interface física do PCIe (geralmente 5.0 ou 6.0) para permitir que a CPU acesse memória conectada via slot de expansão com coerência de cache. Isso significa que podemos ter módulos de memória (DRAM ou SCM) conectados onde antes colocávamos apenas placas de rede ou SSDs.
Com a chegada das especificações CXL 3.0 e 3.1, entramos na era do Memory Pooling. Um rack de servidores não precisa mais ter memória presa a cada placa-mãe. Podemos ter um chassi dedicado apenas à memória, compartilhado dinamicamente entre vários servidores via um switch CXL.
O novo tier de armazenamento: G3.5
Isso cria uma nova camada na hierarquia de armazenamento, que gosto de chamar de "G3.5" (entre a Geração 3 e 4 de persistência). Não é tão rápido quanto a DDR5 soldada ao lado da CPU, mas é ordens de magnitude mais rápido que o NVMe mais veloz.
Para a IA Agêntica, isso é oxigênio. O "estado" do agente pode viver nesse pool de memória CXL. Se o agente precisar "dormir" e acordar em outro servidor, sua memória já está lá, acessível via barramento, sem necessidade de cópia de dados via rede Ethernet/InfiniBand.
Tabela Comparativa: A Nova Hierarquia de Dados
| Tecnologia | Função na IA Agêntica | Latência Típica | Capacidade Típica (por unidade) | Custo Relativo |
|---|---|---|---|---|
| HBM3e | Raciocínio Imediato (GPU) | < 10 ns | 80GB - 144GB | Extremo |
| DDR5 DRAM | Contexto Ativo (CPU) | ~100 ns | 64GB - 512GB | Alto |
| CXL Memory | Memória Expandida/Pool | ~200-300 ns | 512GB - 4TB+ | Médio-Alto |
| NVMe (Gen5) | Memória Vetorial (RAG) | ~10-20 µs | 3.8TB - 30TB | Médio |
| HDD | Arquivo Morto (Backup) | ~5-10 ms | 20TB+ | Baixo |
Observe o salto de latência entre CXL e NVMe. É aqui que a batalha da próxima década será travada.
Bancos de dados vetoriais e a exigência de IOPS
A memória de longo prazo de um agente reside em Vector Databases (como Milvus, Weaviate, Pinecone). Diferente de bancos de dados relacionais (SQL) que buscam linhas exatas, bancos vetoriais buscam "similaridade" matemática em um espaço multidimensional.
Para o hardware de armazenamento, isso é um pesadelo de I/O. Uma busca vetorial não lê um arquivo grande sequencialmente. Ela "salta" pelo disco buscando vizinhos próximos em clusters de dados díspares. Isso gera um padrão de leitura altamente aleatório (Random Read 4K).
Discos rígidos mecânicos (HDDs) são fisicamente incapazes de lidar com isso. A agulha não consegue se mover rápido o suficiente. Mas mesmo SSDs corporativos padrão sofrem.
A ascensão do ZNS e Key-Value SSDs
Para mitigar isso, estamos vendo a adoção de ZNS (Zoned Namespaces). O ZNS permite que o software (o banco de dados vetorial) "converse" diretamente com o controlador do SSD, ditando onde os dados são gravados fisicamente. Isso elimina a camada de tradução (FTL) tradicional do SSD, reduzindo a latência e a amplificação de escrita.
Algoritmos como o DiskANN da Microsoft foram desenhados especificamente para manter o índice vetorial no SSD (NVMe), mas com performance próxima à da RAM, usando pré-carregamento inteligente e gerenciamento de I/O agressivo.
⚠️ Perigo: Utilizar SSDs de consumo (mesmo Gen5) para cargas de trabalho de Vector Search intensivas resultará em desgaste prematuro (baixo TBW) e degradação de performance térmica. O controlador precisa ser Enterprise-grade para sustentar milhões de IOPS constantes.
 Figura: Visualização futurista de um rack de servidores onde cabos ópticos unem módulos de memória e bancos de SSD em um único bloco unificado de dados, representando a Memória Universal.
Figura: Visualização futurista de um rack de servidores onde cabos ópticos unem módulos de memória e bancos de SSD em um único bloco unificado de dados, representando a Memória Universal.
O desafio do Checkpointing: Quando o Agente não pode falhar
Imagine um agente financeiro autônomo executando uma estratégia de trading complexa. Se o servidor falhar, o agente não pode reiniciar do zero. Ele precisa de persistência.
O processo de salvar o estado atual é chamado de Checkpointing. Em modelos gigantes, um checkpoint pode ter terabytes. Gravar isso no disco tradicional é lento e paralisa o processamento (o temido "I/O Wait").
A solução reside na convergência de tecnologias. O uso de Storage Class Memory (SCM) ou tecnologias emergentes como MRAM (Magnetoresistive RAM) em interfaces CXL permite checkpoints quase instantâneos. O dado é persistente (não apaga se a luz acabar), mas tem velocidade de barramento de memória.
Isso elimina a necessidade de sistemas de arquivos complexos para a camada de "scratchpad" (rascunho) da IA. O armazenamento deixa de ser um "lugar onde guardamos arquivos" e passa a ser "um lugar onde a memória vive para sempre".
O futuro próximo: A morte do arquivo
Extrapolando para os próximos 5 a 8 anos, a própria noção de "sistema de arquivos" (pastas, arquivos, hierarquias) se tornará um artefato legado para a IA. Agentes não abrem arquivos; eles acessam tokens e vetores.
Veremos o surgimento de Appliances de Memória Universal, caixas pretas no rack que contêm petabytes de flash NAND de alta densidade (QLC ou PLC), gerenciadas por controladores com IA embutida, apresentando-se ao sistema operacional não como um disco /dev/nvme0n1, mas como um espaço de endereçamento de memória plano e infinito.
O armazenamento frio não desaparecerá totalmente (sempre precisaremos de backups de desastre em fita ou HDD), mas ele será empurrado para tão longe da borda de computação que se tornará invisível para as aplicações diárias. Para a IA Agêntica, se não é instantâneo, não existe.
Preparem suas infraestruturas. A métrica de sucesso não é mais "quantos Terabytes você tem", mas "quão rápido seu agente consegue lembrar". A latência é o novo downtime.
FAQ: Perguntas Frequentes sobre Storage para IA
O que diferencia o armazenamento para IA Generativa da IA Agêntica?
Enquanto a IA Generativa (fase de treinamento) foca em leitura sequencial massiva de datasets, a IA Agêntica (fase de inferência e ação) exige baixíssima latência em leituras aleatórias para acessar memória de longo prazo (RAG) e escritas frequentes de estado (checkpointing) para manter a persistência da tarefa ao longo do tempo.Por que o SSD NVMe comum não é suficiente para Vector Databases?
Bancos vetoriais realizam buscas de similaridade que exigem milhões de IOPS aleatórios e simultâneos. SSDs comuns, especialmente os sem DRAM-cache ou com controladores simples, sofrem com "latência de cauda" (picos de demora), fazendo o agente "engasgar" durante o raciocínio. Tecnologias como ZNS (Zoned Namespaces) e algoritmos como DiskANN são necessários para manter a performance próxima à da RAM.O CXL vai substituir a memória RAM tradicional?
Não substituir, mas expandir drasticamente. O CXL (Compute Express Link) permite criar "pools" de memória compartilhada fora da placa-mãe, oferecendo capacidades de Terabytes a uma latência ligeiramente maior que a DRAM local (DDR5), mas ordens de magnitude menor que o SSD mais rápido, preenchendo o gap crítico de memória para grandes modelos.
Julian Vance
Futurista de Tecnologia
"Exploro as fronteiras da infraestrutura, do armazenamento em DNA à computação quântica. Ajudo líderes a decodificar o horizonte tecnológico e construir o datacenter de 2035 hoje."