IA e o TCO de Armazenamento: Onde o Orçamento Sangra Silenciosamente

Descubra os custos ocultos da infraestrutura de storage para IA. Análise de TCO, armadilhas de egress fees, desgaste de SSDs (DWPD) e estratégias de tiering para gestores de TI.
Todo mundo está olhando para as GPUs. Enquanto seus CIOs e arquitetos brigam por alocações de H100 ou B200, o verdadeiro assassino do orçamento está escondido no fundo do rack, piscando luzes verdes que custam muito mais do que parecem. Estou falando do armazenamento.
A Inteligência Artificial não é apenas um problema de computação; é um problema brutal de I/O (Entrada/Saída). Se você tratar o armazenamento para IA como tratava seu servidor de arquivos ou banco de dados legado, prepare-se para uma conversa desagradável com o financeiro em seis meses. O TCO (Custo Total de Propriedade) aqui não é linear. Ele é exponencial e cheio de armadilhas contratuais desenhadas para prender seus dados e drenar seu OPEX.
Resumo em 30 segundos
- O custo invisível das APIs: Provedores de nuvem cobram por requisição. Datasets de IA com bilhões de arquivos pequenos geram faturas astronômicas apenas em taxas de leitura/escrita (PUT/GET), ignorando o volume em GB.
- Desgaste acelerado de hardware: O treinamento de modelos exige checkpoints constantes. Isso tritura o ciclo de vida (DWPD) de SSDs comuns, exigindo substituições frequentes que o CAPEX inicial não previu.
- A armadilha do Egress: Armazenar é barato; recuperar é caro. A gravidade dos dados em nuvem cria um lock-in técnico e financeiro que impede a repatriação de cargas de trabalho.
A inflação do hardware e o paradoxo dos orçamentos
Existe um erro crônico nos projetos de IA atuais: subestimar a taxa de transferência necessária para manter as GPUs alimentadas. Uma GPU ociosa esperando dados do disco é o recurso mais caro da sua empresa sendo desperdiçado. Para evitar isso, as equipes de TI superdimensionam a performance com arrays All-Flash NVMe de última geração.
O problema é o preço por terabyte utilizável. Em 2024 e 2025, vimos uma flutuação agressiva no mercado de NAND Flash. Fabricantes ajustaram a produção para manter preços elevados. Quando você negocia um storage para IA, o vendedor vai focar na capacidade bruta. Ignore isso. Foque na capacidade efetiva após a redução de dados (deduplicação e compressão).
Porém, aqui está o alerta: dados de IA (imagens, vídeos, áudio, vetores) já são altamente comprimidos ou entrópicos. A deduplicação em datasets de treinamento é pífia. Se o vendedor prometer uma taxa de redução de 5:1 para vender menos hardware físico, ele está mentindo ou é incompetente. Calcule seu TCO baseando-se em uma redução de 1.5:1 ou, para ser seguro, 1:1. Se não fizer isso, você terá que comprar o dobro de gavetas de disco no meio do ano fiscal.
A taxa dos arquivos pequenos e o custo das chamadas de API
Este é o ponto onde a nuvem pública destrói orçamentos mal planejados. O armazenamento de objetos (S3 e compatíveis) é o padrão para Data Lakes de IA. O custo por GB parece irrisório, centavos de dólar. É aqui que você assina o contrato e cai na armadilha.
O treinamento de modelos, especialmente em Visão Computacional ou LLMs (Large Language Models), envolve bilhões de pequenos arquivos ou tokens. Cada vez que seu pipeline de treinamento acessa um desses arquivos, conta como uma requisição GET. Cada vez que ele salva um resultado intermediário, é um PUT.
Muitos provedores cobram por milhar ou milhão de requisições. Quando seu dataset tem 500 milhões de arquivos e você precisa iterar sobre eles (épocas) dezenas de vezes, a fatura de "transações" pode superar o custo do armazenamento em si. Além disso, existe o problema do "tamanho mínimo de objeto". Alguns sistemas de arquivos distribuídos ou serviços de nuvem alocam um bloco mínimo (ex: 128KB) para qualquer arquivo. Se você armazena milhões de arquivos de texto de 4KB, você está pagando por 124KB de ar em cada um deles. Isso é "inflação de armazenamento" pura.
⚠️ Perigo: Audite a estrutura de cobrança de API do seu provedor de nuvem ou contrato de storage as a service. Exija simulações baseadas em IOPS e throughput de arquivos pequenos, não apenas em streaming sequencial de grandes blocos.
A matemática cruel do desgaste de SSDs
No mundo do armazenamento corporativo, temos uma métrica chamada DWPD (Drive Writes Per Day - Escritas na Unidade Por Dia). É a medida de resistência do SSD.
Em cargas de trabalho tradicionais (banco de dados, virtualização), a leitura costuma ser maior que a escrita (proporção 70/30 ou 80/20). Na IA, especificamente durante o treinamento e fine-tuning, o cenário muda drasticamente devido ao mecanismo de Checkpointing.
Para evitar perder dias de processamento se uma GPU falhar, o modelo salva seu estado completo no disco frequentemente (a cada 10 minutos ou a cada hora). Esses checkpoints são massivos. Estamos falando de terabytes sendo escritos sequencialmente repetidas vezes. Isso "lixa" as células de memória NAND do SSD.
Se você economizou comprando SSDs "Read Intensive" (focados em leitura, geralmente 1 DWPD ou menos) para seu cluster de treinamento, prepare-se para falhas em massa em 12 a 18 meses. O TCO explode porque você precisa substituir o hardware físico e lidar com o downtime da reconstrução do RAID.
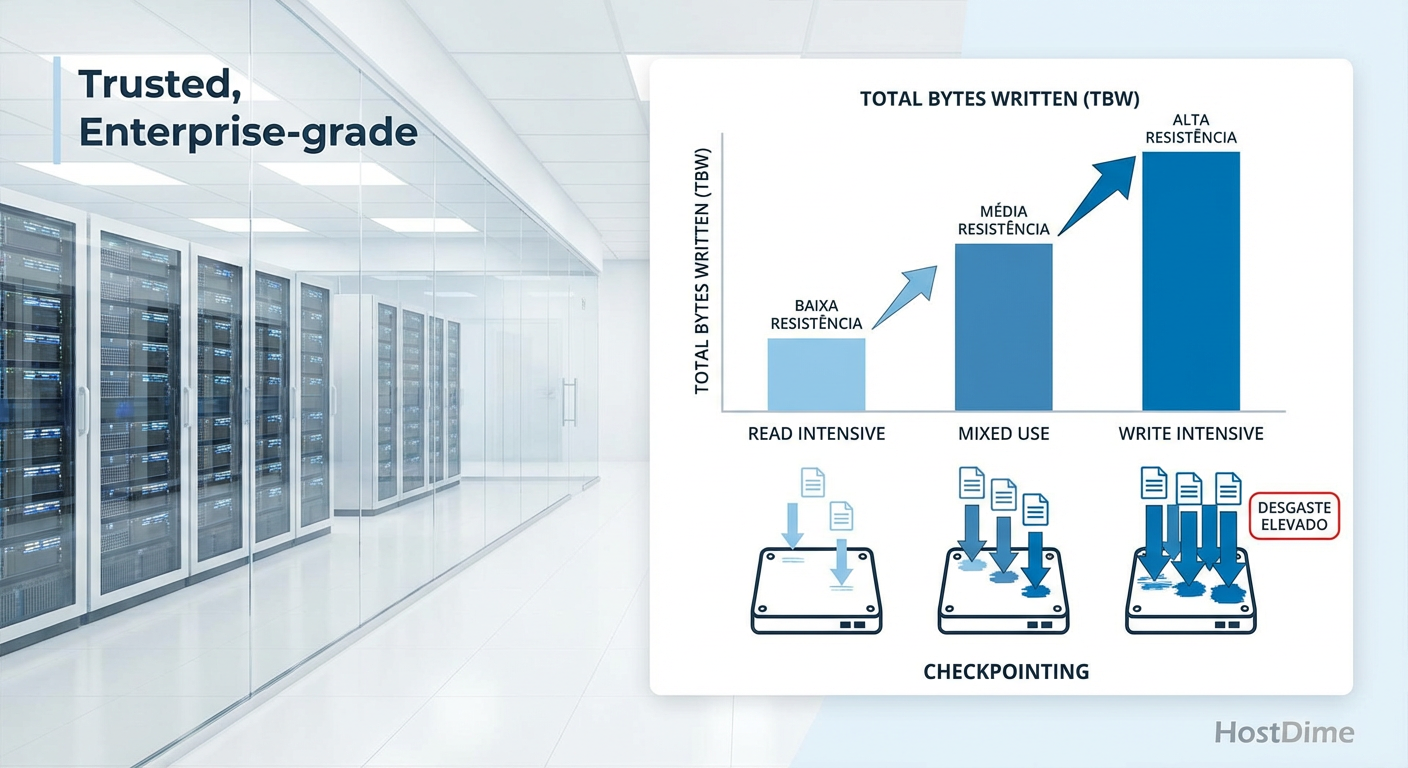 Figura: Comparativo técnico de resistência de SSDs: O impacto oculto dos Checkpoints de IA na vida útil do hardware.
Figura: Comparativo técnico de resistência de SSDs: O impacto oculto dos Checkpoints de IA na vida útil do hardware.
Tabela Comparativa: O Custo do Erro na Escolha do Disco
Abaixo, uma análise direta do impacto financeiro e operacional ao escolher o disco errado para cargas de escrita intensiva (Checkpoints de IA).
| Característica | SSD "Read Intensive" (QLC/TLC Baixo Custo) | SSD "Mixed Use/Write Intensive" (Enterprise NVMe) | Impacto no TCO de IA |
|---|---|---|---|
| DWPD (Escritas/Dia) | 0.3 a 1.0 | 3.0 a 10.0+ | Discos de baixo DWPD morrem prematuramente em clusters de treino. |
| Custo Inicial (CAPEX) | Baixo ($) | Alto ($$$) | A economia inicial é ilusória frente à reposição antecipada. |
| Performance de Escrita | Cai drasticamente quando o cache enche | Sustentada e consistente | Quedas de performance deixam GPUs de $30k ociosas. |
| Risco de Falha | Alto em cargas de Checkpointing | Baixo/Controlado | Falha de disco durante treino pode corromper dias de trabalho. |
| Cenário Ideal | Data Lakes de Leitura (Inference) | Scratch Space / Checkpoints (Training) | Usar o disco certo para a fase certa do pipeline é vital. |
Estratégias de tiering inteligente
A única forma de não falir é parar de tratar todo dado como VIP. Nem tudo precisa estar em NVMe Gen5. O segredo da negociação e da arquitetura é o Tiering (camadas) impiedoso.
Hot Tier (NVMe/Flash de Alta Performance): Apenas para o dataset que está sendo treinado agora e para a pasta de checkpoints recentes.
Warm Tier (SSD SATA/SAS ou QLC): Para datasets que serão usados na próxima semana ou modelos validados que servem inferência frequente.
Cold Tier (HDD/Object Storage Barato/Fita): Onde vive o Data Lake bruto.
O desafio é a movimentação. Softwares de orquestração de dados que movem arquivos automaticamente entre essas camadas são essenciais. Porém, cuidado com o licenciamento desses softwares. Alguns cobram por capacidade total gerenciada. Se você tem 5PB de dados frios e o software cobra licença sobre tudo, o custo do software vai superar o do hardware. Negocie licenças baseadas apenas na capacidade do Hot Tier ou um valor fixo por nó.
💡 Dica Pro: Ao negociar arrays de armazenamento, exija que a funcionalidade de Auto-Tiering esteja inclusa no preço base, sem taxas recorrentes de licenciamento por capacidade futura.
A soberania dos dados como alavanca
Por fim, o Lock-in. A nuvem é maravilhosa até você tentar sair dela. As taxas de Egress (saída de dados) são o pedágio que os provedores cobram para devolver seus próprios dados. Em projetos de IA com petabytes de informação, o custo de baixar esses dados para treinar on-premise ou mover para outro provedor pode inviabilizar a migração.
Isso é uma questão contratual, não técnica. Ao fechar contratos de armazenamento em nuvem para IA, a cláusula de Egress deve ser seu principal campo de batalha. Negocie isenção total até um certo volume (ex: 15% do armazenamento total por mês) ou use conexões diretas (como Direct Connect ou ExpressRoute) com taxas fixas negociadas.
Se o vendedor se recusar a flexibilizar o Egress, considere isso um sinal vermelho. Eles estão apostando que seus dados ficarão pesados demais para serem movidos, tornando você um refém de aumentos de preço futuros.
O precipício do armazenamento
Não espere que os custos de armazenamento caiam "naturalmente" conforme a tecnologia avança. A demanda por IA está mantendo os preços de NAND e HDD artificialmente altos e os contratos de nuvem cada vez mais complexos.
Minha previsão é que, nos próximos dois anos, veremos empresas "repatriando" dados de treinamento para infraestruturas próprias ou colocation não por segurança, mas por pura incapacidade de pagar as taxas de API e saída da nuvem pública. O gestor que não auditar o IOPS e o ciclo de vida dos seus SSDs hoje será o mesmo que terá que explicar por que o orçamento de TI acabou em setembro.
Proteja seu contrato. Defina SLAs de performance, não apenas de disponibilidade. E nunca, jamais, confie na taxa de deduplicação da brochura de marketing.
Perguntas Frequentes (FAQ)
Qual a diferença real de TCO entre SSDs de consumo e Enterprise para IA?
A diferença reside fundamentalmente no DWPD (Drive Writes Per Day). Cargas de trabalho de IA, especialmente o treinamento, "queimam" SSDs de consumo em questão de meses devido à escrita intensiva e contínua de checkpoints. O custo operacional de substituição, somado ao downtime e risco de perda de dados, supera drasticamente qualquer economia inicial de CAPEX feita na compra do hardware mais barato.A nuvem ainda vale a pena para armazenamento de grandes datasets de treinamento?
A resposta depende da "temperatura" e gravidade dos dados. Para datasets estáticos acessados raramente (Cold Storage), a nuvem ainda é viável. No entanto, para treinamento ativo, as taxas de egress (saída) e as cobranças por chamadas de API (PUT/GET) podem tornar o OPEX insustentável quando comparado a um storage on-premise cujo custo já foi amortizado.O que é o 'imposto de arquivos pequenos' no armazenamento de IA?
Refere-se à ineficiência de custo ao armazenar bilhões de arquivos minúsculos. Muitos provedores de nuvem e sistemas de arquivos arredondam o tamanho do arquivo para cima (ex: cobram 128KB por um arquivo de 4KB) ou cobram taxas por milhar de requisições. Em datasets de IA compostos por tokens ou imagens pequenas, isso inflaciona a fatura de forma desproporcional ao volume real de dados armazenados.
Ricardo Vilela
Especialista em Compras/Procurement
"Especialista em dissecar contratos e destruir argumentos de vendas. Meu foco é TCO, SLAs blindados e evitar armadilhas de lock-in. Se não está no papel, não existe."