Investigação forense em SSDs: Extraindo a verdade via telemetria NVMe

Descubra como ir além do SMART. Guia técnico sobre extração e análise de logs de telemetria NVMe (LID 0x07/0x08) para identificar falhas silenciosas e latência em servidores.
O servidor de banco de dados travou por 45 segundos. O load average disparou, as conexões da aplicação empilharam e o telefone do on-call tocou às 3 da manhã. Ao reiniciar, tudo parece normal. O smartctl -a retorna "PASSED". O syslog não mostra erros de I/O, apenas timeouts da aplicação.
Para o administrador comum, isso é um mistério ou um "glitch". Para um investigador forense de sistemas, é uma cena de crime. O disco mentiu para você. Ou, mais precisamente, ele omitiu a verdade.
Atributos SMART são relatórios de conformidade, não ferramentas de diagnóstico profundo. Quando lidamos com latência de cauda (tail latency), falhas de firmware ou degradação silenciosa da NAND, precisamos abrir a caixa-preta do dispositivo. Precisamos da Telemetria NVMe.
Resumo em 30 segundos
- SMART é insuficiente: Ele mostra apenas se o disco está "vivo", mas falha em explicar quedas de performance ou travamentos momentâneos.
- A Caixa-Preta: A especificação NVMe 1.3+ introduziu logs de telemetria que permitem extrair o estado da memória do controlador e buffers internos no momento de uma falha.
- Correlação é chave: A análise forense real acontece cruzando os timestamps da telemetria do firmware com os eventos de latência do kernel (via eBPF/logs).
O comportamento errático de I/O e os timeouts inexplicáveis
A maioria das falhas modernas de armazenamento não é binária (funciona/não funciona). Elas são espectrais. Um SSD NVMe pode entregar 500k IOPS consistentemente e, subitamente, pausar todo o processamento por 200ms para realizar uma rotina de Garbage Collection agressiva ou tratar um bloco defeituoso via Read Retry.
Para o Kernel Linux, isso parece um dispositivo que parou de responder. Se o tempo exceder o nvme_core.io_timeout (geralmente 30s ou 60s), o driver reseta o controlador. Mas se a pausa for de 5 segundos? O sistema engasga, a aplicação falha, mas nenhum erro crítico é registrado.
 Figura: O ciclo de vida de um I/O bloqueado: Enquanto a aplicação espera, o controlador do SSD está ocupado com tarefas de manutenção interna invisíveis ao sistema operacional.
Figura: O ciclo de vida de um I/O bloqueado: Enquanto a aplicação espera, o controlador do SSD está ocupado com tarefas de manutenção interna invisíveis ao sistema operacional.
Investigar isso olhando apenas para métricas de sistema operacional (iostat, sar) é inútil. O SO vê o sintoma (latência alta), não a causa. A causa reside dentro do microcontrolador do SSD.
A arquitetura interna: Logs e o buffer de memória
Um SSD Enterprise moderno não é apenas um meio de armazenamento; é um computador embarcado complexo. Ele possui:
Processador Multi-core: Geralmente ARM ou RISC-V.
DRAM Cache: Para tabelas de mapeamento (L2P).
SRAM Buffer: Para dados em trânsito imediato.
Firmware (OS): Um sistema operacional de tempo real (RTOS) complexo.
Quando você solicita a telemetria, você não está lendo a NAND onde seus arquivos estão. Você está pedindo um core dump desse minicomputador.
A especificação NVMe define dois tipos de telemetria:
Host-Initiated (Log 0x07): O administrador solicita o dump (ex: após notar lentidão).
Controller-Initiated (Log 0x08): O próprio disco decide gravar o log porque detectou uma falha interna crítica (panic, assert failure).
💡 Dica Pro: O tamanho desse log varia. Em drives Datacenter (como Intel/Solidigm D7 ou Samsung PM series), o payload pode chegar a vários megabytes, contendo o estado das filas de submissão, contadores de erro de bit (BER) por die de flash e temperatura histórica detalhada.
A limitação dos atributos SMART tradicionais
Confiar no SMART para diagnóstico de performance é como tentar consertar um motor de Fórmula 1 olhando apenas para a luz de "Verificar Motor" no painel.
O SMART foi desenhado na era dos HDDs para prever falhas mecânicas catastróficas. Em SSDs, ele evoluiu pouco. Ele nos dá contadores acumulativos (Media_Wearout_Indicator, Critical_Warning), mas perde o contexto temporal. Saber que houve "50 erros de CRC" na vida do disco não me diz se eles aconteceram há dois anos ou durante o incidente de ontem à noite.
Tabela Comparativa: SMART vs. Telemetria NVMe
| Característica | SMART / Log de Saúde | Telemetria NVMe (Log 0x07/0x08) |
|---|---|---|
| Granularidade | Resumo acumulativo (vida útil) | Snapshot do estado exato no tempo |
| Conteúdo | Contadores simples (ex: TBW, Power On Hours) | Dump de memória, registros de CPU, filas de comandos |
| Objetivo | Previsão de fim de vida útil | Depuração de falhas e análise de causa raiz |
| Legibilidade | Padronizado e fácil leitura | Binário complexo (frequentemente requer ferramentas do vendor) |
| Impacto | Zero impacto na performance | Pode pausar I/O brevemente para gerar o dump |
Decodificando o log de telemetria com nvme-cli
Para extrair a verdade, usamos o canivete suíço do armazenamento: nvme-cli. A maioria das distribuições Linux já o possui nos repositórios.
O comando para extrair a telemetria iniciada pelo host (Host-Initiated) é:
# Solicita a geração e extração do log de telemetria
# --host-generate: Diz ao firmware para criar um snapshot AGORA
# --output-file: Salva o binário para análise
sudo nvme telemetry-log /dev/nvme0n1 --host-generate --output-file=caso_incidente_001.bin
⚠️ Perigo: O uso da flag
--host-generateforça o controlador a parar o que está fazendo para reunir dados de depuração e preencher o buffer. Em drives de consumo ou firmwares mal otimizados, isso pode causar uma latência de I/O perceptível (stall) durante a execução. Execute com cautela em produção sob carga pesada.
O que fazer com o arquivo binário?
Aqui reside o desafio. A especificação NVMe padroniza o cabeçalho da telemetria, mas a área de dados (payload) é específica do fabricante (Vendor Specific).
No entanto, drives que seguem a especificação OCP (Open Compute Project) Datacenter NVMe possuem estruturas mais legíveis. Para drives genéricos, você tem duas opções:
Enviar ao Fabricante: Se você tem contrato de suporte Enterprise, esse arquivo é o que a engenharia deles pedirá.
Ferramentas de Vendor: Fabricantes como Intel (Solidigm), Samsung e Micron fornecem CLIs proprietários (ex:
sstda Solidigm oumagicianvia DC toolkit) que conseguem parsear esses binários em texto legível.
 Figura: Decodificação forense: Transformando o blob binário da telemetria em eventos legíveis que explicam o comportamento interno do firmware.
Figura: Decodificação forense: Transformando o blob binário da telemetria em eventos legíveis que explicam o comportamento interno do firmware.
Cruzamento de eventos: Firmware vs. Kernel
A "arma do crime" é encontrada quando cruzamos os dados. Uma investigação forense completa exige alinhar o relógio do sistema operacional com o relógio interno do SSD.
O cenário da investigação
No Kernel (Linux): Usamos eBPF (ferramentas como
biolatencyoubiosnoopdo pacote bcc-tools) para identificar que às 14:05:23.500, uma escrita no/dev/nvme0n1levou 350ms para completar.Na Telemetria (SSD): Ao analisar o log extraído logo após o evento, buscamos registros de timestamp internos.
Se encontrarmos na telemetria um evento de "Superblock Erase Start" ou "DRAM Bus Error correction" exatamente no timestamp correspondente (ajustando o uptime do drive), temos a causa raiz. Não foi a rede, não foi a aplicação, não foi o driver. Foi o firmware do disco realizando uma operação de manutenção bloqueante ou recuperando-se de um erro de bit silencioso.
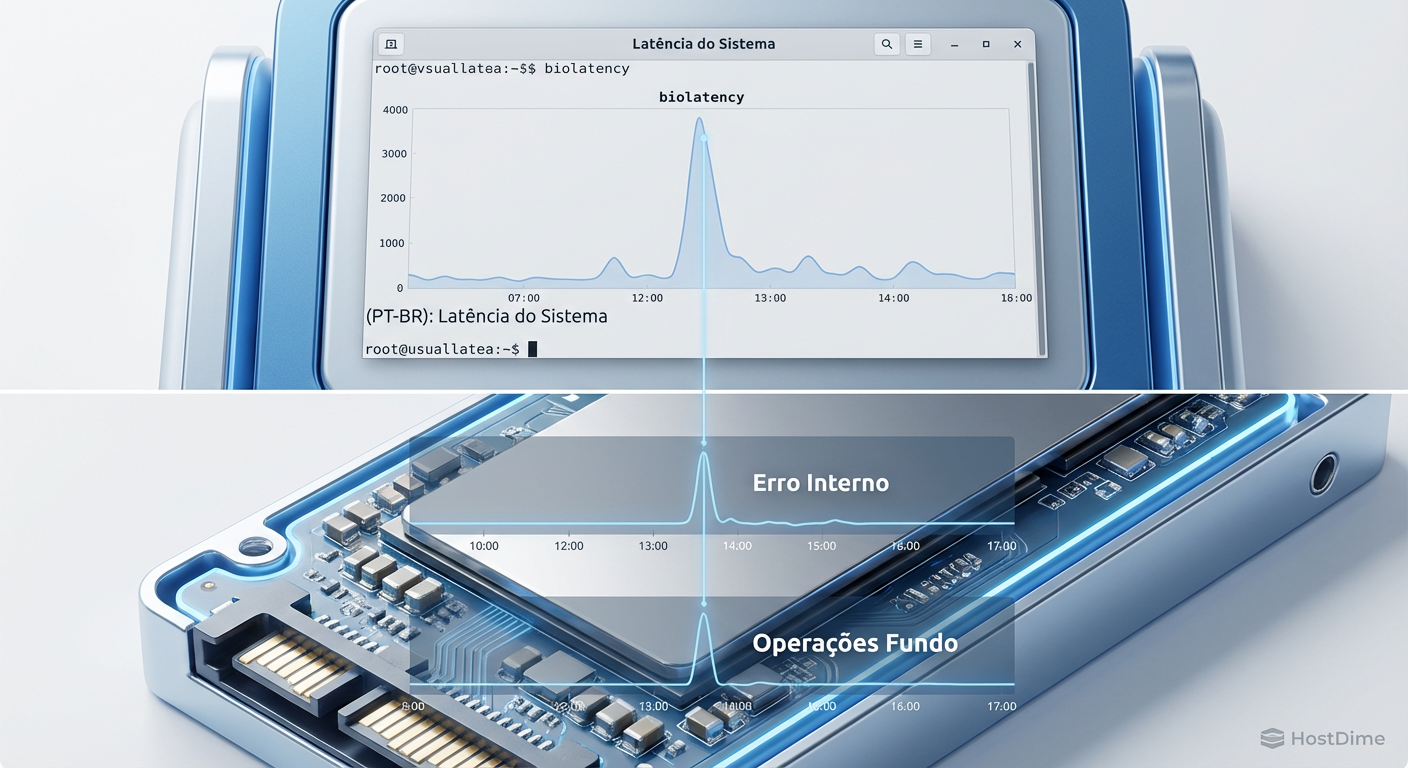 Figura: A prova final: O alinhamento perfeito entre o pico de latência visto pelo Kernel e a atividade de manutenção interna registrada pelo firmware do SSD.
Figura: A prova final: O alinhamento perfeito entre o pico de latência visto pelo Kernel e a atividade de manutenção interna registrada pelo firmware do SSD.
Veredito Técnico
A era de tratar SSDs como caixas pretas imutáveis acabou. Em ambientes de alta performance e infraestruturas críticas, a análise baseada apenas em "Pass/Fail" do SMART é negligência técnica.
Para o investigador de sistemas, a telemetria NVMe é a ferramenta definitiva para diferenciar um problema de software de uma falha de hardware incipiente. Seus discos estão falando o tempo todo sobre superaquecimento localizado, falhas de ECC e contenção de recursos internos. A questão é se você está ouvindo.
Minha recomendação: incorpore a coleta de telemetria (nvme telemetry-log) em seus scripts de resposta a incidentes. Capture os dados antes de reiniciar o servidor. O log volátil de um controlador reiniciado é uma evidência perdida para sempre.
FAQ: Perguntas Frequentes
Qual a diferença entre SMART e Telemetria NVMe?
O SMART oferece um resumo de saúde (aprovado/reprovado) e contadores básicos acumulativos. A Telemetria NVMe é como uma caixa-preta de avião, capturando o estado interno da memória do controlador, filas de comando, registros de erro e contexto de execução no momento exato da falha ou sob demanda.Todos os SSDs suportam telemetria via nvme-cli?
A funcionalidade foi padronizada no NVMe 1.3, mas a implementação varia drasticamente. SSDs Enterprise (Datacenter) que seguem a especificação OCP (Open Compute Project) oferecem os dados mais detalhados e estruturados. SSDs de consumo (client) podem suportar o comando, mas frequentemente retornam dados criptografados ou pouco úteis sem ferramentas do fabricante.O comando de telemetria afeta a performance do disco?
Sim. A extração do Log 0x07 (Host-Initiated) pode pausar brevemente o processamento de I/O dependendo da implementação do firmware, pois o controlador precisa despejar buffers internos e snapshots de memória para a área de log. Deve ser usado com cautela em sistemas de produção sob carga máxima.Referências & Leitura Complementar
NVM Express Base Specification 2.0: Seção sobre Telemetry Log Pages e Get Log Page command.
OCP Datacenter NVMe SSD Specification (v2.0): Detalhes sobre requisitos de log de telemetria padronizados para datacenters.
Manpage nvme-telemetry-log: Documentação oficial do pacote
nvme-clipara Linux.JEDEC JESD218: Padrões de requisitos de endurance e retenção de dados para SSDs (contexto sobre desgaste de NAND).

Bruno Albuquerque
Investigador Forense de Sistemas
"Não aceito 'falha aleatória'. Com precisão cirúrgica, mergulho em logs e timestamps para expor a causa raiz de qualquer incidente. Se deixou rastro digital, eu encontro."