KVM, NVMe e io_uring: Eliminando o gargalo de syscalls

Descubra como o io_uring revoluciona a performance de I/O em KVM, reduzindo a latência do NVMe e eliminando o overhead de syscalls que o linux-aio não resolve.
Você investiu pesado em arrays All-Flash NVMe. Configurou a rede a 100GbE. O hardware é de ponta. No entanto, ao rodar aquele banco de dados transacional crítico dentro da VM, os IOPS estagnam muito antes do limite teórico do disco, e a latência de cauda (tail latency) começa a subir de forma errática. O culpado raramente é o disco físico neste cenário moderno; o gargalo subiu para o software.
O protocolo NVMe (Non-Volatile Memory Express) é inerentemente paralelo e capaz de lidar com filas profundas, mas a stack de I/O tradicional do Linux (baseada em syscalls síncronas ou no antigo linux-aio) foi desenhada em uma era de discos rotacionais lentos, onde o tempo de busca da cabeça de leitura mascarava qualquer ineficiência da CPU. Hoje, com dispositivos capazes de milhões de IOPS, o custo de "pedir" ao kernel para ler um dado (a syscall) tornou-se mais caro do que a leitura em si.
É aqui que entra o io_uring. Não é apenas uma nova API; é uma mudança fundamental na arquitetura de como o userspace (neste caso, o QEMU/KVM) conversa com o subsistema de storage do kernel, eliminando o overhead que mata a performance de VMs de alta densidade.
Resumo em 30 segundos
- O Problema: Discos NVMe são tão rápidos que o processador gasta mais tempo trocando de contexto (syscalls) do que transferindo dados.
- A Solução: O
io_uringcria anéis de memória compartilhada entre o QEMU e o Kernel, permitindo submissão e completude de I/O sem chamadas de sistema constantes.- O Resultado: Redução drástica de system time na CPU do host, maior densidade de IOPS e latência determinística para cargas de trabalho críticas.
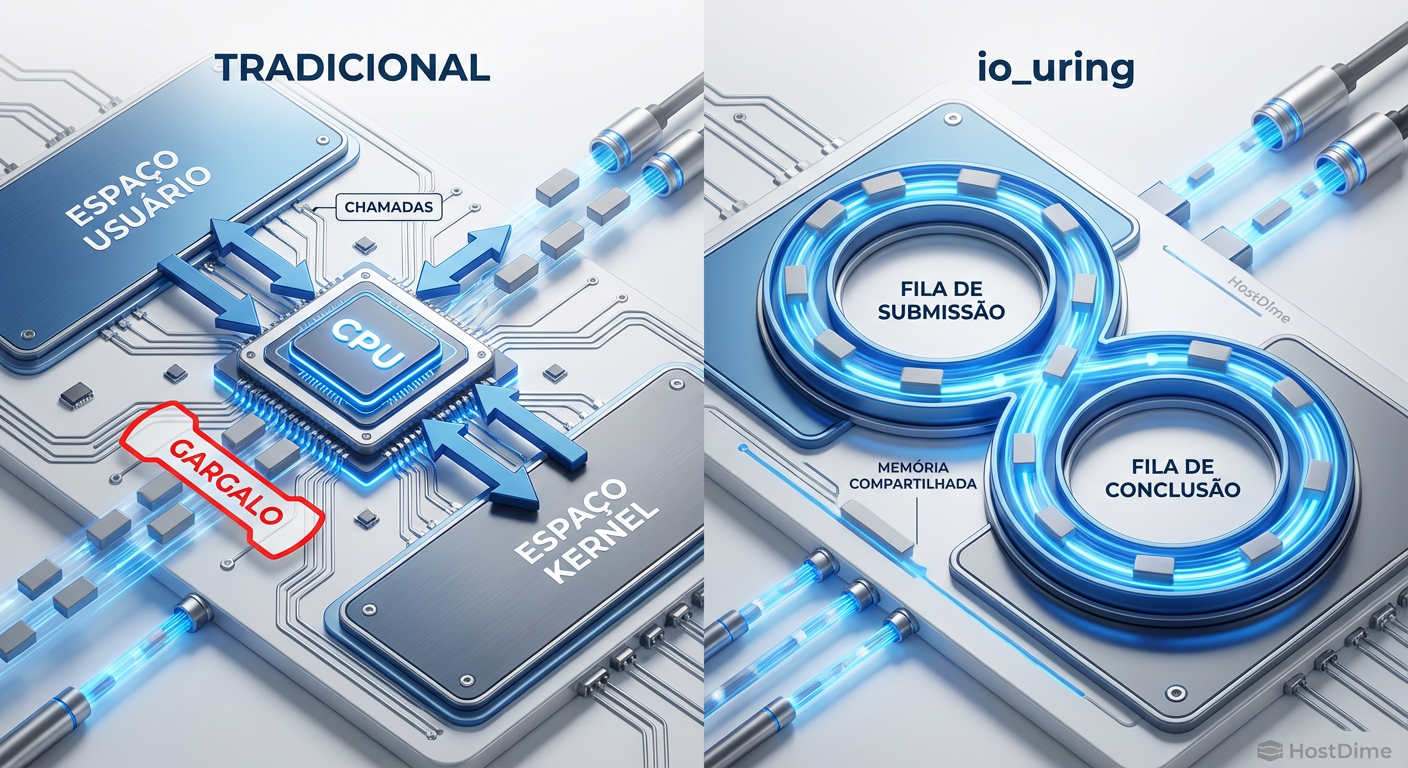 Figura: Comparação visual: O tráfego intenso de syscalls no modelo tradicional versus o fluxo contínuo dos anéis compartilhados no io_uring.
Figura: Comparação visual: O tráfego intenso de syscalls no modelo tradicional versus o fluxo contínuo dos anéis compartilhados no io_uring.
Quando o processador se torna o freio do NVMe
Para entender o ganho, precisamos dissecar a dor. No modelo tradicional, quando uma VM solicita uma escrita no disco, o processo QEMU no host precisa invocar uma system call (como pwritev ou io_submit do linux-aio).
Cada syscall exige uma troca de contexto: a CPU para o que está fazendo no espaço do usuário, salva os registradores, muda para o modo kernel, verifica permissões, executa a operação, e depois faz o caminho inverso. Com as mitigações de segurança para vulnerabilidades de execução especulativa (Spectre/Meltdown e suas variantes), o custo dessas transições aumentou significativamente.
Quando você tem um SSD SATA entregando 500 IOPS, esse overhead é irrelevante. Quando você tem um namespace NVMe entregando 800.000 IOPS, você está pedindo ao processador para realizar milhões de trocas de contexto por segundo. O resultado é visível no top ou htop do host: uma barra vermelha alta de %sys (system time). Sua CPU está "gastando" ciclos apenas para gerenciar o tráfego, não para processar dados.
A mecânica dos anéis: Submission e Completion
O io_uring (introduzido por Jens Axboe no kernel Linux 5.1) resolve isso adotando uma abordagem de memória compartilhada. Em vez de bater na porta do kernel a cada pacote, o QEMU e o Kernel concordam em usar duas filas circulares (Ring Buffers) que residem em uma área de memória acessível a ambos:
Submission Queue (SQ): O QEMU coloca as requisições de I/O aqui.
Completion Queue (CQ): O Kernel coloca os resultados aqui.
O funcionamento é elegante em sua simplicidade. O QEMU deposita uma requisição de leitura na SQ e atualiza um ponteiro "tail". O Kernel, que pode estar monitorando essa fila (polling), percebe a nova entrada, executa o I/O diretamente no hardware NVMe e coloca o resultado na CQ. O QEMU lê a CQ.
💡 Dica Pro: Em cenários de altíssima performance, o
io_uringsuporta um modo de Polling. O kernel mantém uma thread ativa verificando a SQ, eliminando completamente a necessidade de qualquer syscall para notificar a chegada de novos dados. Isso consome mais CPU (100% de um núcleo), mas reduz a latência ao mínimo físico possível.
Linux AIO vs. io_uring: O Salto Geracional
Muitos administradores ainda configuram suas VMs KVM com io='native', que invoca o linux-aio. Embora tenha servido bem por anos, o AIO tem falhas arquiteturais: ele pode bloquear inesperadamente (especialmente em metadados de sistemas de arquivos como ext4 ou XFS) e exige múltiplas cópias de memória.
Abaixo, comparamos as tecnologias no contexto de virtualização:
| Característica | Linux AIO (io='native') |
io_uring (io='uring') |
Impacto no Storage |
|---|---|---|---|
| Arquitetura | Syscalls assíncronas (mas nem sempre) | Anéis de memória compartilhada (Ring Buffers) | Menor latência por operação. |
| Comportamento | Pode bloquear em metadados de FS | Totalmente não-bloqueante (Non-blocking) | Consistência de performance (menos jitter). |
| Overhead de CPU | Alto em IOPS elevados (Context Switch) | Baixo (Zero-copy e Batching eficiente) | Mais ciclos de CPU livres para as vCPUs da VM. |
| Modo Polling | Não suportado nativamente na mesma escala | Suporte nativo a Polling de I/O | Latência ultra-baixa para DBs (Oracle, SAP HANA). |
| Complexidade | API complexa e antiga | API moderna e flexível | Melhor integração com kernels recentes. |
 Figura: Representação artística: A via congestionada do AIO com "pedágios" de syscalls versus o "hyperloop" de alta velocidade do io_uring conectando a CPU ao NVMe.
Figura: Representação artística: A via congestionada do AIO com "pedágios" de syscalls versus o "hyperloop" de alta velocidade do io_uring conectando a CPU ao NVMe.
Implementando a stack moderna no XML do Libvirt
Para ativar o io_uring, você precisa garantir que sua infraestrutura atenda aos pré-requisitos. Estamos falando de um Kernel Host 5.10 ou superior (para estabilidade e features completas) e QEMU 5.0+. A maioria das distribuições modernas (RHEL 9, Ubuntu 22.04+, Debian 11+) já suporta isso nativamente.
A configuração é feita no nível do disco virtual dentro do XML da VM (virsh edit nome-da-vm).
O bloco de configuração ideal
<disk type='file' device='disk'>
<driver name='qemu' type='raw' cache='none' io='uring' discard='unmap'/>
<source file='/var/lib/libvirt/images/vm-database-disk.img'/>
<target dev='vdb' bus='virtio'/>
<address type='pci' domain='0x0000' bus='0x04' slot='0x00' function='0x0'/>
</disk>
Pontos de Atenção Crítica:
io='uring': Esta é a flag que instrui o QEMU a usar a nova interface. Se o seu QEMU for antigo, a VM falhará ao iniciar.cache='none': Essencial. Isso ativa oO_DIRECT, garantindo que o I/O vá direto do userspace para o dispositivo, ignorando o Page Cache do host. Oio_uringbrilha no modo Direct I/O. Usar cache de host (writeback) pode mascarar os benefícios ou introduzir complexidade desnecessária na gestão dos buffers.type='raw': Embora o QCOW2 suporteio_uring, a camada de tradução de metadados do QCOW2 adiciona overhead. Para performance pura de NVMe, use volumes RAW ou passe o dispositivo físico via PCIe Passthrough (embora Passthrough elimine a necessidade deio_uringpois o host sai do caminho).
⚠️ Perigo: Não altere o modo de I/O de uma VM em produção sem janelas de manutenção. Embora seja uma mudança de configuração do QEMU, o comportamento do storage muda. Teste sempre a integridade dos dados em ambiente de staging, especialmente se estiver usando sistemas de arquivos complexos no host como ZFS ou Btrfs.
Por que adicionar vCPUs não resolve latência de I/O
Um erro comum de administradores VMware que migram para KVM é tentar resolver problemas de "I/O Wait" dentro da VM adicionando mais vCPUs. Isso é contraproducente.
Se o gargalo é a entrega do I/O pelo host (devido ao overhead de syscalls explicado anteriormente), adicionar vCPUs apenas aumenta a contenção no agendador (scheduler) do host. A VM fará mais requisições paralelas, saturando ainda mais a fila de syscalls do kernel do host.
Com io_uring, a eficiência do host aumenta. Isso significa que você pode frequentemente obter mais IOPS com menos vCPUs, pois cada ciclo de clock da vCPU é gasto processando a transação do banco de dados, e não esperando a interrupção de completude do disco.
Validando a redução de latência: Fio e Htop
A prova real está na telemetria. Para validar a implementação, recomendo um teste A/B simples usando a ferramenta fio.
Cenário de Teste: Execute um job de Random Read 4K (o pesadelo dos discos) com alta profundidade de fila (QD).
Comando Fio (dentro da VM):
fio --name=teste-uring --ioengine=libaio --rw=randread --bs=4k --direct=1 --numjobs=4 --iodepth=32 --runtime=60 --group_reporting --filename=/dev/vdb
Nota: Dentro da VM, o ioengine ainda será libaio ou similar, pois a VM vê um dispositivo VirtIO. A mágica do io_uring acontece no backend, no Host.
O que observar no Host:
Antes (
io='native'): Abra ohtopno host. Observe os núcleos atribuídos à VM. Você verá uma barra vermelha significativa (Kernel/System time).Depois (
io='uring'): Repita o teste. A barra vermelha deve diminuir drasticamente, sendo substituída por barra verde (User time) ou simplesmente ficando menor, indicando que o mesmo trabalho está sendo feito com menos esforço da CPU.
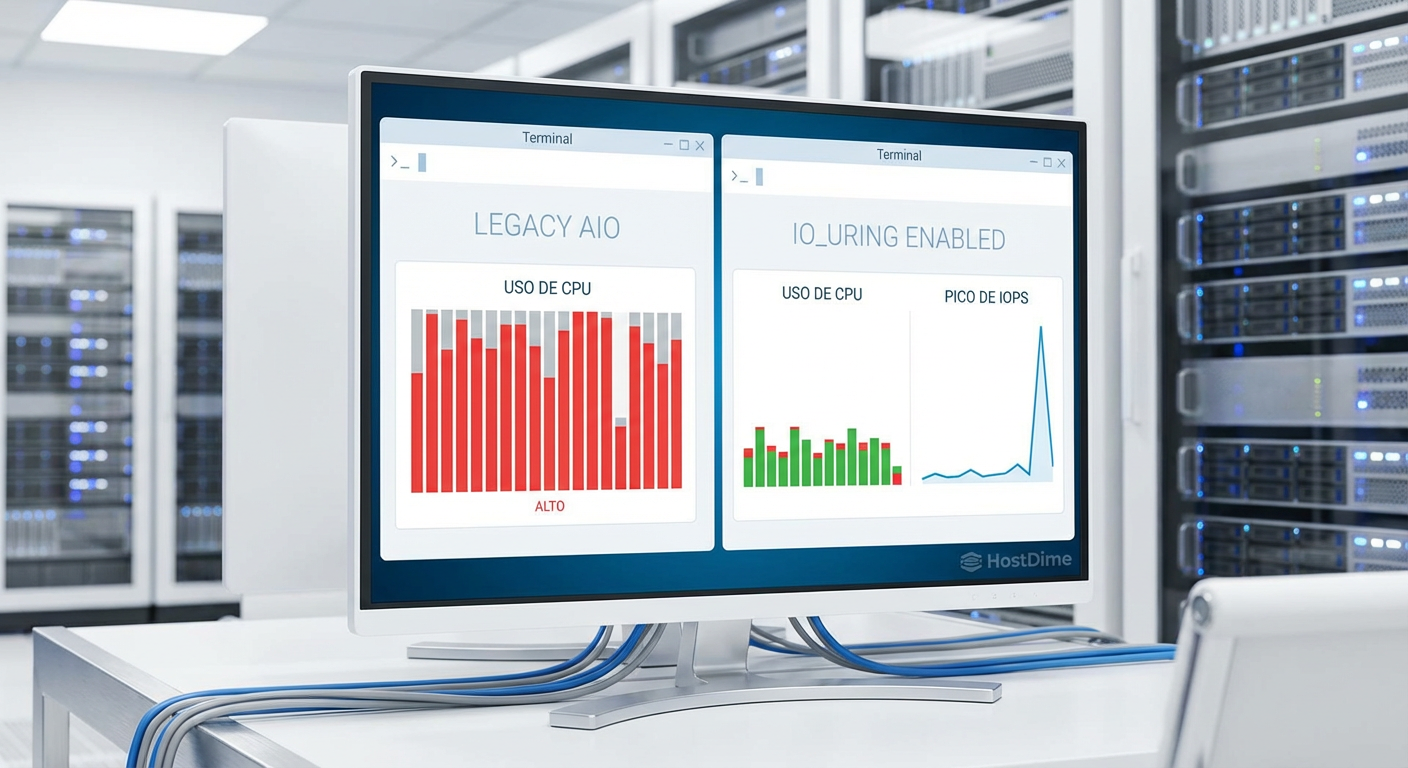 Figura: Painel de monitoramento: Comparativo lado a lado do htop mostrando a queda drástica do uso de CPU (System Time) ao migrar de AIO para io_uring.
Figura: Painel de monitoramento: Comparativo lado a lado do htop mostrando a queda drástica do uso de CPU (System Time) ao migrar de AIO para io_uring.
Otimização Avançada: IOThreads e Pinning
Para extrair a última gota de performance do seu array NVMe, apenas ativar o io_uring pode não ser suficiente. Você deve isolar o processamento de I/O do processamento da vCPU.
No Libvirt, configure IOThreads:
<domain>
...
<iothreads>1</iothreads>
<cputune>
<iothreadpin iothread='1' cpuset='2'/>
</cputune>
...
<disk>
...
<driver ... io='uring' iothread='1'/>
</disk>
</domain>
Ao dedicar uma thread de I/O e "pinar" (fixar) essa thread em um núcleo físico específico do host (que não compete com as vCPUs), você cria um pipeline de dados extremamente eficiente. O io_uring rodará dentro dessa thread dedicada, garantindo que as operações de storage nunca roubem tempo de CPU da aplicação principal.
O Futuro é Assíncrono
A transição para o io_uring no ecossistema KVM não é apenas uma "melhoria de performance"; é uma necessidade arquitetural para acompanhar a evolução do hardware de armazenamento. Com a chegada do PCIe 5.0 e SSDs capazes de 14 GB/s, as stacks de software antigas são âncoras inaceitáveis.
Se você gerencia clusters de virtualização com storage local NVMe ou NVMe-oF (over Fabrics), a migração para io_uring deve estar no seu roadmap de curto prazo. A redução na latência de cauda e a liberação de ciclos de CPU justificam o esforço de validação.
Referências & Leitura Complementar
Kernel.org: Ring Setup and Teardown (io_uring documentation) - O paper original de Jens Axboe.
QEMU Project: QEMU 5.0 ChangeLog - Introdução do suporte ao backend io_uring.
Libvirt: Domain XML Format - Disk Elements - Documentação oficial dos atributos de driver.
SNIA: Computational Storage Architecture - Contexto sobre a evolução do storage moderno.
Perguntas Frequentes (FAQ)
O que é io_uring e por que é melhor que linux-aio?
O io_uring é uma interface de I/O assíncrono do kernel Linux que usa anéis de buffer compartilhados (SQ e CQ) entre kernel e userspace. Essa arquitetura elimina a necessidade de syscalls repetitivas e cópias de memória excessivas para cada operação, gargalos comuns no antigo linux-aio, resultando em maior eficiência e menor latência.Quais os requisitos mínimos para usar io_uring no KVM?
Para habilitar essa funcionalidade, sua infraestrutura deve rodar um kernel Linux 5.1 ou superior (embora a versão 5.10+ seja fortemente recomendada para estabilidade e recursos completos), QEMU versão 5.0 ou superior e Libvirt 6.3+ para suporte nativo via configuração XML.O io_uring funciona com qualquer tipo de disco virtual?
Tecnicamente sim, mas o maior ganho de performance é obtido com discos configurados como 'Raw' e usando `cache='none'` (modo O_DIRECT). O uso com imagens QCOW2 é suportado, mas a camada de tradução e metadados desse formato pode mascarar parte dos ganhos de performance pura que o io_uring oferece.
Ricardo Garcia
Especialista em Virtualização (VMware/KVM)
"Vivo na camada entre o hypervisor e o disco. Ajudo administradores a entenderem como a performance do storage define a estabilidade de datastores, snapshots e migrações críticas."