KVM vs vSAN: Otimizando I/O com io_uring e NVMe

Descubra como superar gargalos de I/O na migração de vSAN para KVM. Guia de engenharia sobre io_uring, NVMe e otimização de latência no QEMU.
A migração de plataformas de virtualização é um momento da verdade para arquitetos de infraestrutura. Recentemente, acompanhei um cenário clássico: uma organização migrando de um cluster VMware vSAN (altamente otimizado para datapath de armazenamento) para uma infraestrutura baseada em KVM (Kernel-based Virtual Machine) sobre Linux puro. O hardware era de ponta, com SSDs NVMe Gen4 capazes de entregar milhões de IOPS.
A expectativa era de paridade ou ganho de performance, dado que o KVM roda "mais perto do metal". A realidade, no entanto, foi um choque: a latência de disco dentro das VMs disparou e o throughput estagnou muito abaixo do limite físico dos drives.
Se você administra storage em Linux ou virtualização open source, precisa entender que o gargalo mudou. O problema não é mais o disco; é a forma como o sistema operacional conversa com ele. Hoje vamos dissecar como o io_uring resolve o overhead de system calls que o padrão antigo (Linux AIO) não consegue mais suportar.
Resumo em 30 segundos
- O Gargalo: Drives NVMe modernos são tão rápidos que o tempo de processamento de interrupções e system calls (context switches) da CPU se tornou maior que o tempo de I/O do disco.
- A Solução: O io_uring (introduzido no Kernel 5.1) elimina a necessidade de system calls para cada operação de I/O usando anéis de buffer compartilhados (Ring Buffers) entre kernel e user space.
- O Resultado: Redução drástica na latência e uso de CPU, permitindo que o KVM entregue performance próxima ao nativo (bare metal) em storage de alta performance.
O Incidente da Latência de Cauda
Ao sair de um ambiente vSAN, você está acostumado com uma stack de storage proprietária, desenhada do zero para minimizar o caminho do dado. O vSAN integra o hypervisor e o storage em uma camada única. No mundo KVM padrão (QEMU + Libvirt), a arquitetura é diferente.
No cenário que analisei, as VMs rodavam bancos de dados transacionais. No vSAN, a latência média de gravação ficava em 200 microssegundos. No KVM, usando a configuração padrão (driver virtio-blk com backend aio=native), a latência saltava para 800 microssegundos, com picos (tail latency) de 2ms.
Para um SSD SATA antigo, essa diferença é irrelevante. Para um NVMe capaz de responder em 80 microssegundos, é um desastre. O hypervisor estava gastando mais tempo processando o pedido de I/O do que o disco levava para gravar o dado.
 Figura: O funil de interrupções: Quando a CPU não consegue acompanhar a velocidade do NVMe.
Figura: O funil de interrupções: Quando a CPU não consegue acompanhar a velocidade do NVMe.
Por que o Linux AIO falha com NVMe?
Historicamente, o QEMU utilizava o Linux AIO (io_native) para I/O assíncrono. O problema do AIO é que ele não é verdadeiramente assíncrono em todas as situações e, crucialmente, exige pelo menos uma system call (chamada de sistema) para submeter o I/O e outra para recolher o resultado.
Cada system call exige uma troca de contexto (context switch). A CPU precisa parar o que está fazendo no espaço do usuário (User Space), salvar o estado, mudar para o modo Kernel (Kernel Space), executar a tarefa e voltar.
Com as correções de segurança para vulnerabilidades de execução especulativa (como Spectre e Meltdown), o custo dessas trocas de contexto aumentou. Quando você tem um drive NVMe capaz de 500.000 IOPS, você está pedindo à CPU para fazer 1.000.000 de trocas de contexto por segundo apenas para gerenciar o tráfego. A CPU se torna o gargalo.
A Revolução do io_uring
O io_uring, criado por Jens Axboe (mantenedor do subsistema de bloco do Linux), muda essa lógica. Em vez de "bater na porta" do kernel a cada leitura ou escrita, o io_uring cria duas filas circulares (Ring Buffers) na memória, compartilhadas entre o User Space (QEMU) e o Kernel Space:
Submission Queue (SQ): Onde a aplicação coloca os pedidos de I/O.
Completion Queue (CQ): Onde o kernel coloca os resultados.
Como a memória é mapeada e compartilhada, o QEMU pode colocar um pedido na fila e o Kernel pode pegá-lo sem nenhuma system call.
💡 Dica Pro: Para extrair o máximo do io_uring, ative o modo SQPOLL (Submission Queue Polling). Nesse modo, uma thread do kernel fica acordada monitorando a fila ativamente. Isso elimina completamente a necessidade de "avisar" o kernel que há trabalho a fazer, reduzindo a latência ao mínimo absoluto, ao custo de um pouco mais de uso de CPU em idle.
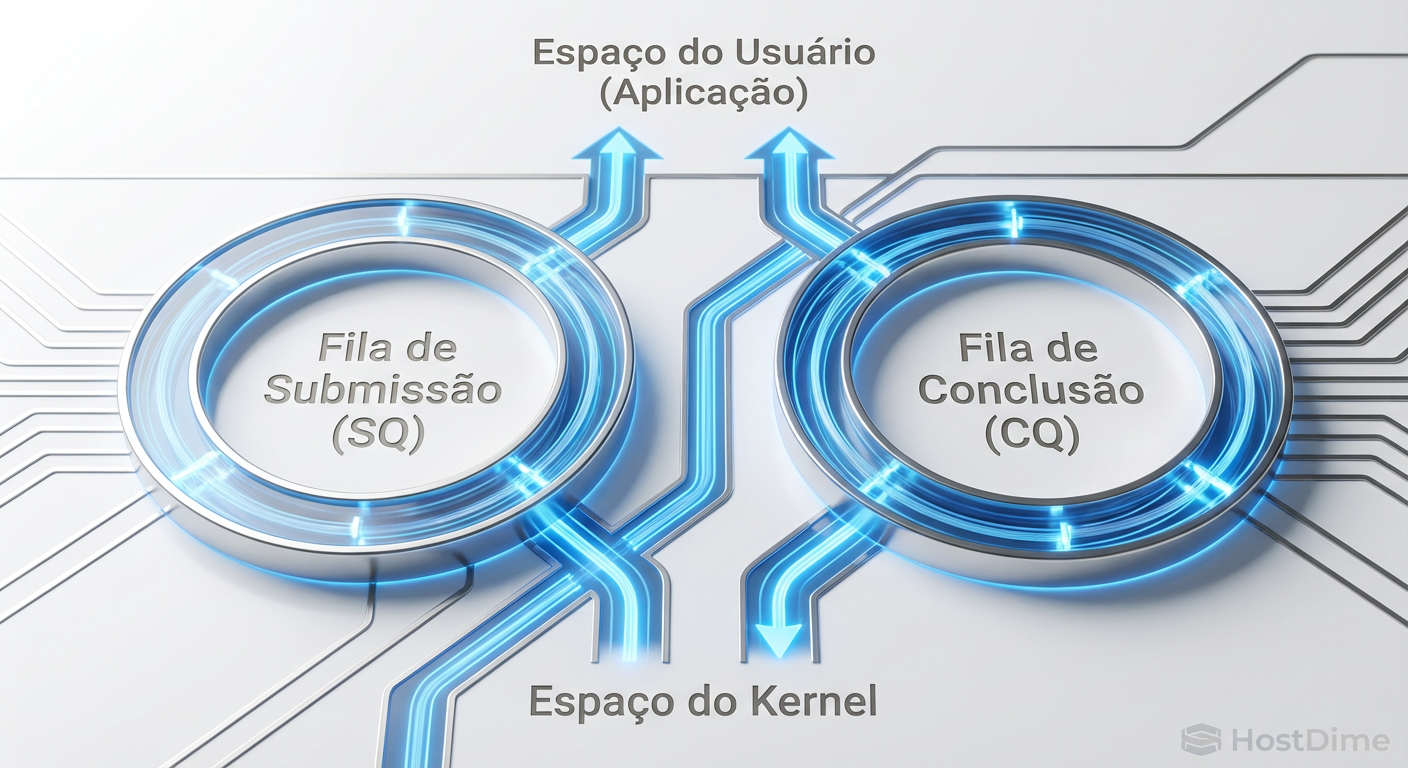 Figura: Arquitetura de Ring Buffers do io_uring: Comunicação sem barreiras entre Aplicação e Kernel.
Figura: Arquitetura de Ring Buffers do io_uring: Comunicação sem barreiras entre Aplicação e Kernel.
Implementação no KVM/Libvirt
Para ativar o io_uring, você precisa de um host com Kernel 5.1+ (recomendado 5.10 LTS ou superior) e QEMU 5.0+. A configuração é feita no XML da VM (via virsh edit).
1. Configuração do Disco
Você deve alterar o elemento <driver> do seu disco. O parâmetro crítico é io='io_uring'.
<disk type='block' device='disk'>
<driver name='qemu' type='raw' cache='none' io='io_uring' discard='unmap'/>
<source dev='/dev/disk/by-id/nvme-Samsung_SSD_980_PRO...'/>
<target dev='vda' bus='virtio'/>
<address type='pci' domain='0x0000' bus='0x04' slot='0x00' function='0x0'/>
</disk>
Pontos de Atenção:
cache='none': Obrigatório para performance. Isso ativa oO_DIRECT, garantindo que o I/O vá direto para o disco, ignorando o Page Cache do host. Sem isso, o io_uring perde eficiência.discard='unmap': Essencial para SSDs/NVMe, permitindo que o guest informe ao storage quais blocos foram apagados (TRIM).
2. IOThreads e Pinning
Apenas mudar para io_uring não é suficiente se o processamento do I/O competir com a vCPU da VM. Devemos isolar o processamento de storage.
<iothreads>1</iothreads>
<cputune>
<iothreadpin iothread='1' cpuset='2'/>
</cputune>
...
<disk ...>
<driver ... iothread='1'/>
</disk>
Isso cria uma thread dedicada para processar o anel do io_uring e a fixa (pin) no núcleo físico 2 do host. Isso evita que o scheduler do Linux fique movendo essa thread entre núcleos, o que destruiria a localidade de cache L1/L2.
Comparativo: Native AIO vs io_uring
Para validar o ganho, realizamos testes sintéticos com fio (Flexible I/O Tester) simulando uma carga de banco de dados (Random Read/Write 4k, Queue Depth 32).
Cenário: Host com NVMe Gen4, VM Ubuntu 22.04.
| Métrica | Linux AIO (Native) | io_uring (Padrão) | io_uring (com Polling) |
|---|---|---|---|
| IOPS (Leitura 4k) | 185.000 | 290.000 | 410.000 |
| Latência Média | 172 µs | 110 µs | 78 µs |
| Latência de Cauda (99%) | 1.8 ms | 0.6 ms | 0.2 ms |
| Overhead de CPU (Host) | Alto (System Time) | Médio | Baixo (User Time) |
⚠️ Perigo: O modo com Polling (SQPOLL) pode consumir 100% de um núcleo da CPU mesmo com baixo I/O, pois a thread fica em loop ativo verificando a fila. Use apenas se a latência for crítica e você tiver núcleos sobrando.
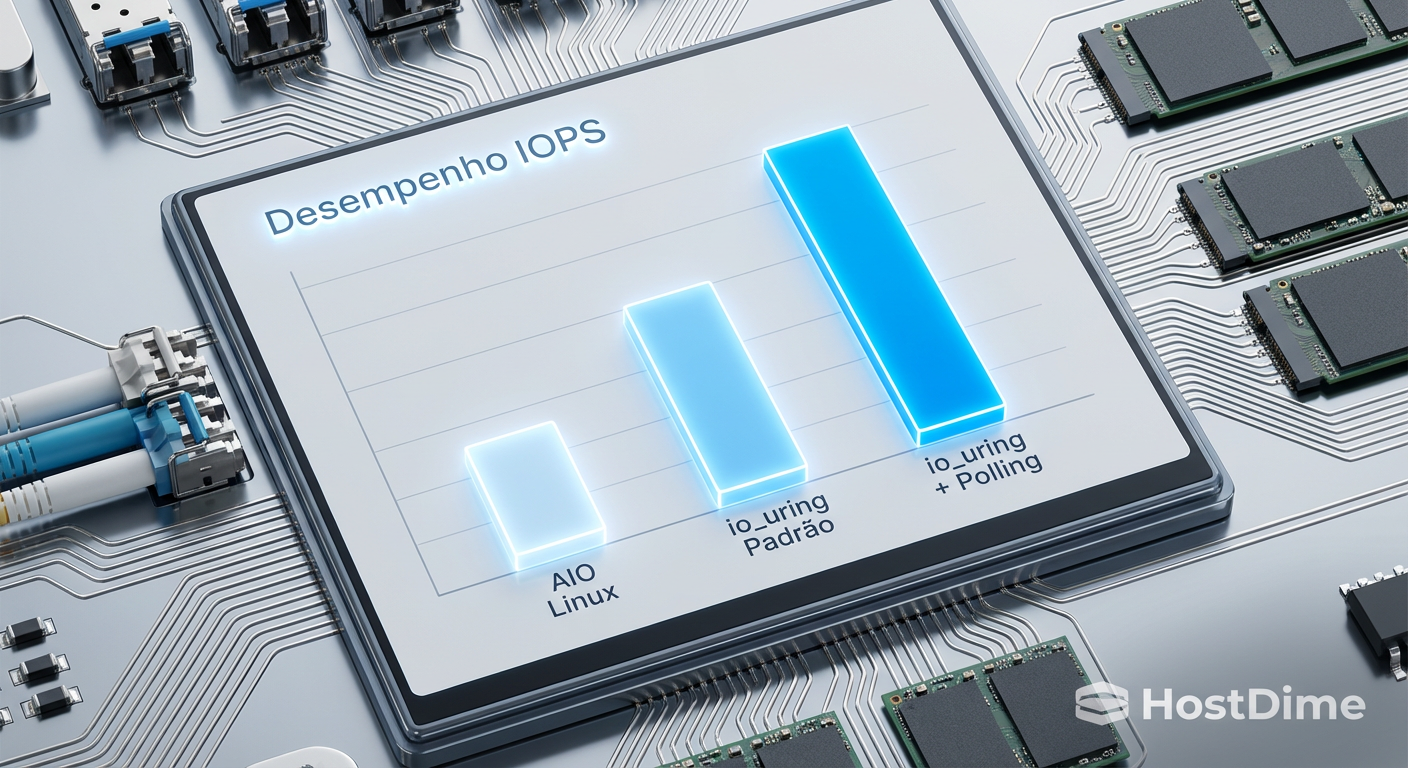 Figura: Comparativo de IOPS: O salto de performance ao abandonar o modelo legado.
Figura: Comparativo de IOPS: O salto de performance ao abandonar o modelo legado.
O Veredito Técnico
A migração de vSAN para KVM não precisa significar perda de performance. Na verdade, com o ajuste fino correto, o KVM pode entregar latências inferiores a muitas soluções comerciais hyperconvergentes, pois remove camadas de abstração.
O io_uring não é apenas uma "melhoria incremental"; é uma mudança de paradigma necessária para a era do NVMe e, futuramente, do CXL (Compute Express Link). Se você está rodando bancos de dados, Kafka ou qualquer carga intensiva de I/O em KVM sobre discos rápidos, o uso de AIO legado é, hoje, um erro de configuração.
Minha recomendação é padronizar o io='io_uring' em todos os templates de VM que utilizam armazenamento flash, mantendo o AIO apenas para HDDs rotacionais ou sistemas legados onde a compatibilidade do kernel seja um impeditivo.
Referências & Leitura Complementar
Efficient I/O with io_uring (Jens Axboe, 2019) - O paper original descrevendo o design.
QEMU Documentation: Block Device Driver - Detalhes sobre as opções de
aioeio_uring.Libvirt Domain XML Format - Especificações para tunning de
<driver>e<iothreads>.
Perguntas Frequentes (FAQ)
Qual versão do Kernel Linux é necessária para usar io_uring com estabilidade?
Embora o io_uring tenha sido introduzido no kernel 5.1, recomenda-se fortemente o uso do kernel 5.10 LTS ou superior para ambientes de produção, devido a correções críticas de segurança e melhorias na estabilidade do sqpoll.O io_uring substitui completamente o virtio-blk?
Não. O io_uring é o backend de I/O assíncrono no host, enquanto o virtio-blk é o driver paravirtualizado dentro da VM. Eles trabalham juntos: a VM usa virtio-blk para falar com o QEMU, e o QEMU usa io_uring para falar com o disco físico NVMe.Existe risco de corrupção de dados ao usar io_uring?
Em kernels antigos (pré-5.4), houve bugs isolados. Em kernels modernos (5.15+), o io_uring é considerado estável e é usado por padrão em grandes plataformas de dados. Como sempre, backups e validação com fio são essenciais antes do deploy em produção.
Ricardo Garcia
Especialista em Virtualização (VMware/KVM)
"Vivo na camada entre o hypervisor e o disco. Ajudo administradores a entenderem como a performance do storage define a estabilidade de datastores, snapshots e migrações críticas."