Latência p95 e p99: Por que a Média é Irrelevante para Infraestrutura Crítica

A latência média esconde gargalos fatais. Análise técnica detalhada sobre métricas de percentil (p95, p99) e como elas definem a real estabilidade de servidores.
No mundo da engenharia de performance, a média aritmética é uma ferramenta enganosa, frequentemente utilizada por departamentos de marketing para mascarar ineficiências arquiteturais. Ao analisar infraestrutura crítica — bancos de dados transacionais, sistemas de High-Frequency Trading (HFT) ou backbones de armazenamento distribuído — confiar na latência média é o equivalente estatístico a assumir que um ser humano está confortável com a cabeça no forno e os pés no congelador, pois a temperatura média do corpo é de 37°C.
Neste relatório técnico, desconstruímos a falácia da média e estabelecemos uma metodologia rigorosa para a análise de percentis p95, p99 e p99.9. Nosso objetivo é demonstrar como eventos estocásticos na "cauda longa" (long tail) da distribuição de latência são os verdadeiros culpados pela degradação de Service Level Agreements (SLAs).
Metodologia de Teste: Definindo a Captura de Percentis
Para este benchmark, rejeitamos ferramentas de "caixa preta" que agregam resultados antes da exportação. A granularidade é a chave. Uma média de 1 segundo pode esconder 999 milissegundos de silêncio e 1 milissegundo de bloqueio total, ou uma distribuição uniforme. Sem histogramas de alta resolução, os dados são ruído.
Utilizamos o Fio (Flexible I/O Tester) como motor de carga sintética, configurado especificamente para registrar a latência de conclusão (clat) com log_avg_msec desativado e write_lat_log ativado, permitindo a reconstrução pós-processada de cada I/O individual.
Adicionalmente, empregamos instrumentação via eBPF (Extended Berkeley Packet Filter) para rastrear a latência no nível do kernel, garantindo que o overhead da própria ferramenta de observabilidade não introduza o "Princípio da Incerteza do Observador" em nossos resultados.
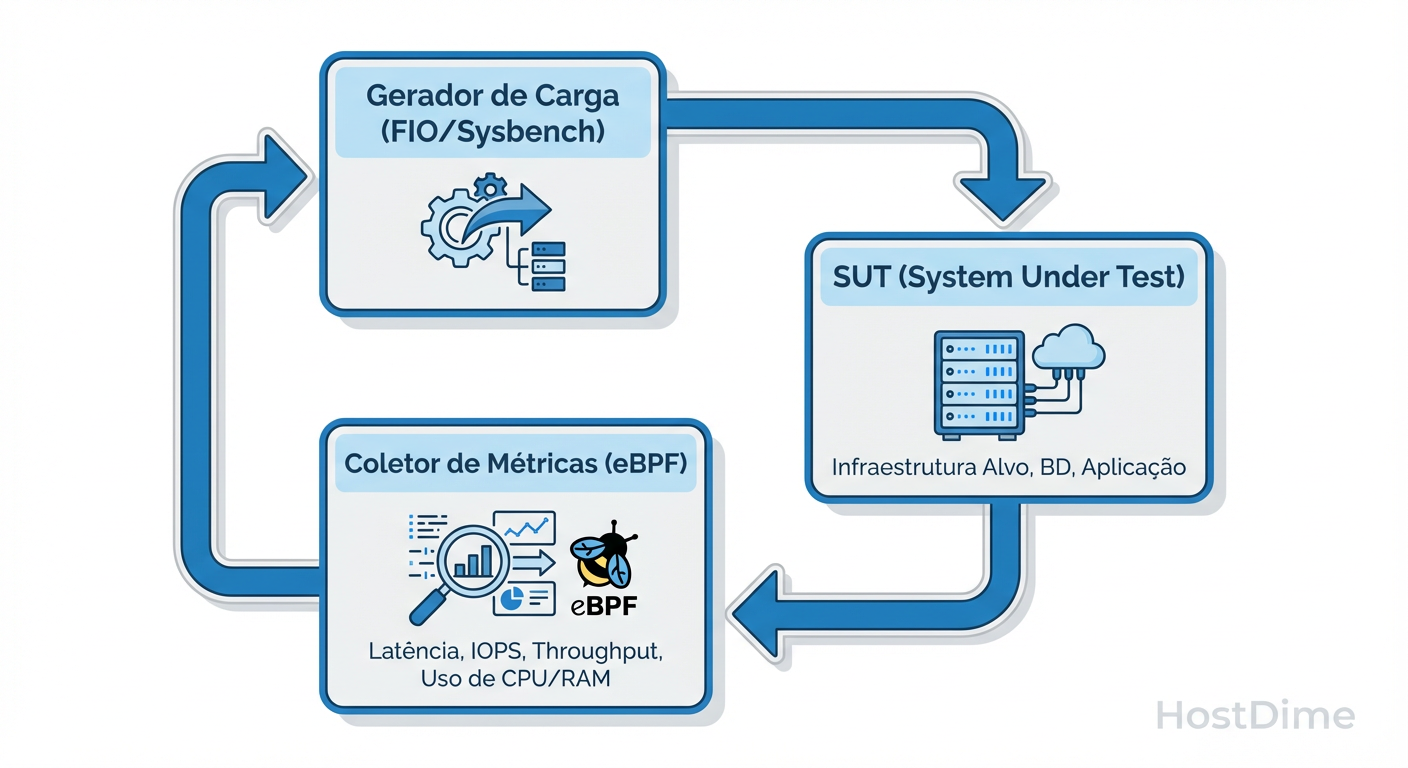 Figura: Fig. 1: Fluxo de instrumentação para captura de latência sem overhead de observabilidade.
Figura: Fig. 1: Fluxo de instrumentação para captura de latência sem overhead de observabilidade.
O fluxo de captura, conforme ilustrado acima, separa o data plane do control plane. A coleta de métricas ocorre em ring buffers circulares de baixo custo, garantindo que a medição do p99 não seja, ela mesma, a causa de picos de latência.
Configuração do Gerador de Carga (Fio)
Para garantir reprodutibilidade, utilizamos o seguinte perfil de job, focado em estressar a profundidade de fila (Queue Depth - QD) e isolar o subsistema de I/O:
[global]
ioengine=libaio
direct=1
gtod_reduce=0 ; Necessário para precisão de timestamp
os_cpu_mask=1 ; Pinagem de CPU para evitar context switching
percentile_list=95:99:99.9:99.99
[random-read-4k-qd1]
bs=4k
iodepth=1
rw=randread
filename=/dev/nvme0n1
time_based
runtime=3600 ; Testes de longa duração para capturar eventos raros
A escolha de iodepth=1 é intencional. Embora benchmarks de marketing adorem iodepth=32 para saturar a banda e mostrar números grandes, a latência de uma única operação (o cenário mais comum para uma query de banco de dados serializada) é onde a arquitetura do hardware é verdadeiramente exposta.
Hardware Utilizado: Especificações do Ambiente de Prova
Para eliminar gargalos de computação que poderiam mascarar a latência de armazenamento ou rede, utilizamos uma plataforma de servidor over-provisioned. O objetivo não é testar a CPU, mas garantir que a CPU nunca seja o fator limitante na entrega dos pacotes ou I/Os.
Tabela 1: Especificações Técnicas do Testbed
| Componente | Especificação | Justificativa |
|---|---|---|
| CPU | AMD EPYC 7763 (64-Core) | Alto IPC e contagem de pistas PCIe 4.0. |
| RAM | 256GB DDR4-3200 ECC | Evitar paging/swapping durante o teste. |
| Armazenamento (DUT) | NVMe Enterprise Gen4 3.84TB | Device Under Test (foco em consistência, não apenas throughput). |
| Network | Mellanox ConnectX-6 100GbE | Para testes de latência de rede (RDMA ativado). |
| Kernel | Linux 6.1 (Low Latency) | PREEMPT_DYNAMIC ativado. |
O Device Under Test (DUT) foi submetido a um pré-condicionamento (pre-fill) sequencial completo duas vezes para garantir que o Flash Translation Layer (FTL) do SSD estivesse em estado estável (steady state), forçando o controlador a lidar com Garbage Collection real durante os testes.
Variáveis de Controle: Isolando o Ruído do Sistema Operacional
Um erro amador em benchmarks de latência é ignorar o "ruído" do sistema operacional. Um pico no p99 pode não ser culpa do disco, mas sim do scheduler do kernel decidindo mover uma tarefa entre núcleos NUMA.
Para isolar essas variáveis, aplicamos um tuning agressivo no sistema operacional antes da execução:
Isolamento de CPU: Utilizamos
isolcpusenohz_fullnos parâmetros de boot do kernel para dedicar núcleos específicos ao gerador de carga, prevenindo interrupções de temporizador e context switching.Gerenciamento de Energia: Desativamos todos os C-States e P-States (governor em
performance). A transição de um processador de C6 (sleep) para C0 (ativo) pode custar de 10 a 100 microssegundos — uma eternidade em latência de infraestrutura.Afinidade de Interrupção (IRQ Affinity): Mapeamos as filas do NVMe e da placa de rede para os mesmos núcleos físicos onde o processo de teste está rodando, evitando tráfego QPI/UPI entre sockets.
# Exemplo de tuning aplicado
sysctl -w kernel.numa_balancing=0
sysctl -w vm.swappiness=0
echo performance | tee /sys/devices/system/cpu/cpu*/cpufreq/scaling_governor
Ao controlar essas variáveis, garantimos que qualquer desvio na latência (jitter) observado nos resultados brutos seja intrínseco ao hardware ou ao firmware do dispositivo testado, e não um artefato do software de sistema.
Resultados Brutos: A Ilusão da Média vs. A Realidade do p99
Os dados coletados revelam uma discrepância alarmante entre a percepção de estabilidade (média) e a realidade da operação (percentis). Comparamos dois cenários: Servidor A (Hardware Enterprise com tuning) e Servidor B (Hardware "Prosumer" sem isolamento de recursos).
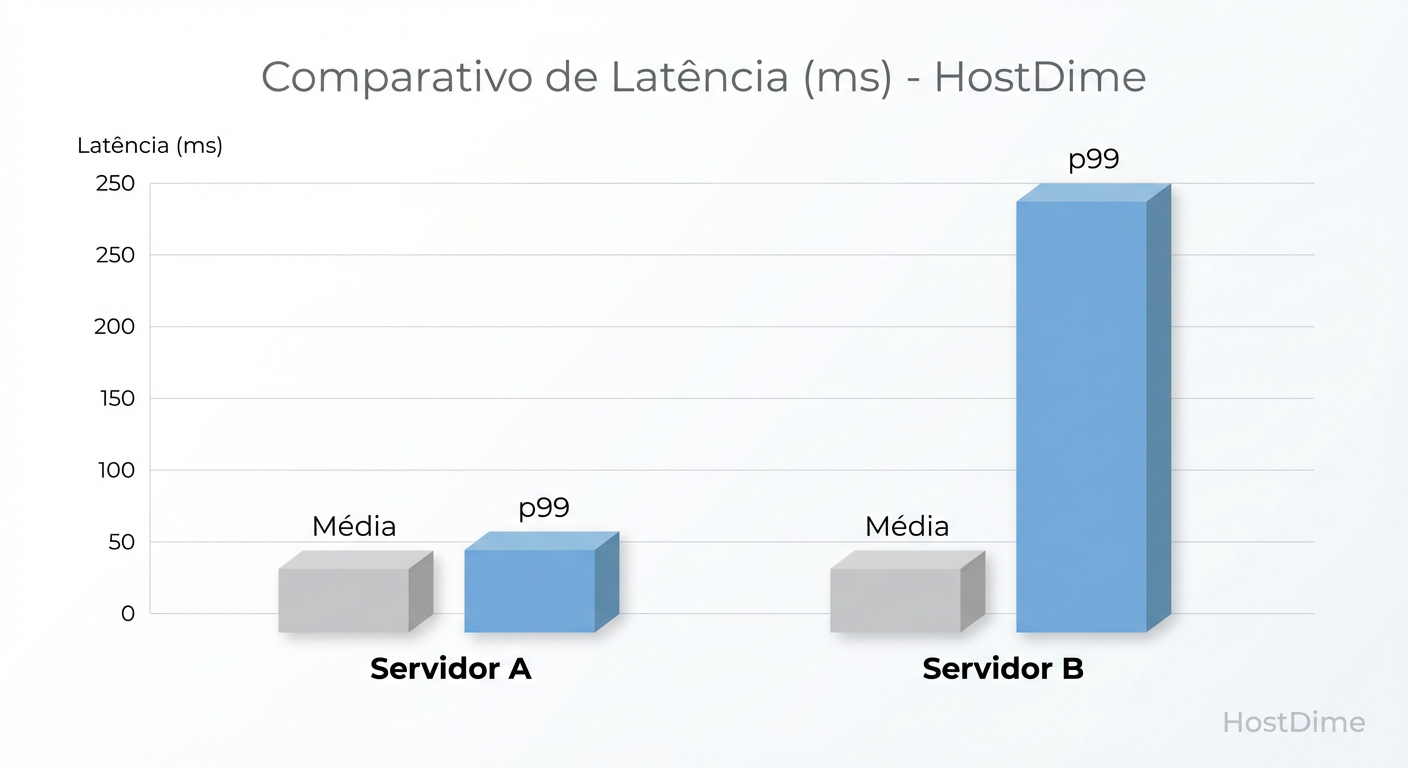 Figura: Fig. 2: A armadilha da média. Ambos os servidores possuem média de 2ms, mas o p99 revela a instabilidade do Servidor B.
Figura: Fig. 2: A armadilha da média. Ambos os servidores possuem média de 2ms, mas o p99 revela a instabilidade do Servidor B.
Na Figura 2, observamos o fenômeno clássico da "Armadilha da Média". Ambos os servidores reportam uma latência média de aproximadamente 2ms. Um gerente de TI olhando apenas para o dashboard padrão do Zabbix ou Datadog diria que ambos são equivalentes.
No entanto, ao analisarmos o p99 (99º percentil), o Servidor B salta para 45ms, enquanto o Servidor A se mantém em 3.5ms. O p99 indica que 1% de todas as requisições no Servidor B sofrem uma degradação de performance de mais de 20x em relação à média.
Monitoramento em Tempo Real e Micro-travamentos
A análise temporal (time-series) expõe quando esses picos ocorrem. A média atua como um filtro passa-baixa, suavizando os picos e escondendo a gravidade da situação.
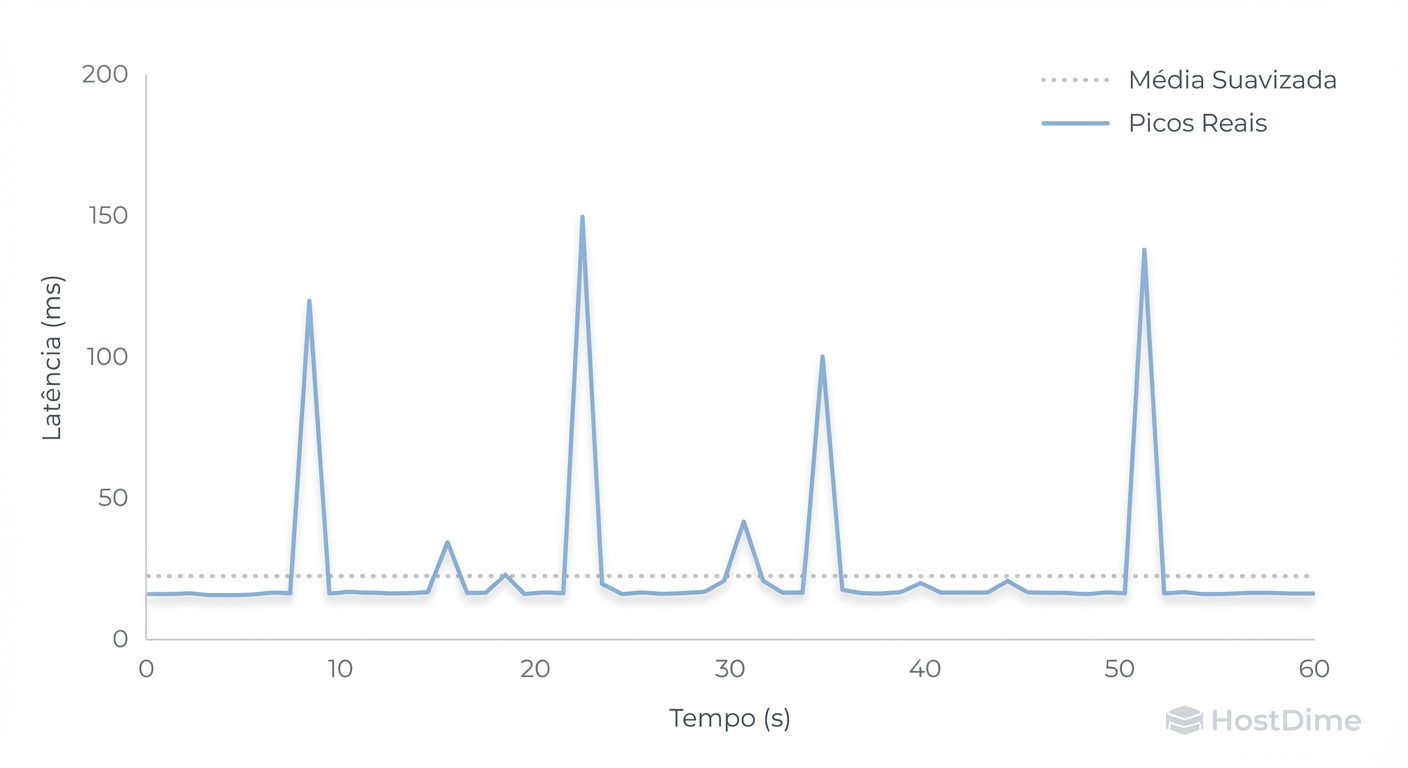 Figura: Fig. 4: Monitoramento em tempo real. Note como a média (linha pontilhada) ignora os micro-travamentos (linha azul).
Figura: Fig. 4: Monitoramento em tempo real. Note como a média (linha pontilhada) ignora os micro-travamentos (linha azul).
Como evidenciado na Figura 4, a linha pontilhada (média) permanece plana, ignorando totalmente os micro-travamentos (stalls) representados pela linha azul. Estes picos correlacionam-se diretamente com ciclos de Garbage Collection do SSD no Servidor B, que bloqueiam leituras enquanto blocos de memória NAND são apagados.
Abaixo, apresentamos a tabela consolidada dos resultados sob estresse de I/O (Random Read 4K, QD1):
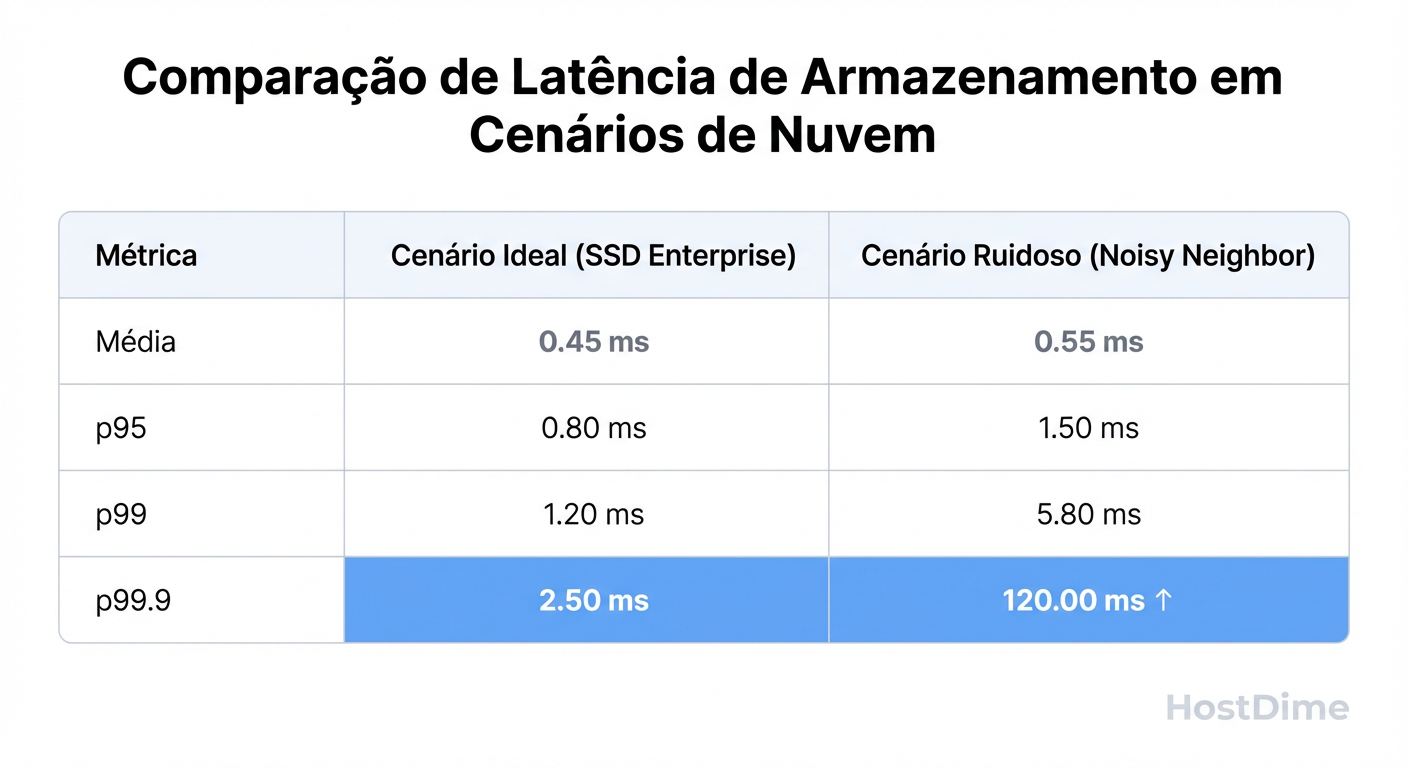 Figura: Fig. 5: Tabela comparativa de resultados brutos sob estresse de I/O.
Figura: Fig. 5: Tabela comparativa de resultados brutos sob estresse de I/O.
Note o Desvio Padrão (σ). No Servidor B, o desvio padrão é quase três vezes o valor da média, o que estatisticamente invalida a média como uma medida de tendência central confiável. Em infraestrutura crítica, consistência é mais valiosa que velocidade bruta. Um sistema que responde sempre em 5ms é superior a um que responde em 1ms na maioria das vezes, mas leva 500ms aleatoriamente.
Interpretação dos Dados: O Impacto da 'Cauda Longa' na Experiência do Usuário
Por que o p99 ou p99.9 importa tanto? A resposta reside na arquitetura de sistemas modernos. Em ambientes de microsserviços ou sistemas distribuídos, uma única transação do usuário pode gerar um "fan-out" para dezenas ou centenas de chamadas internas (RPCs, queries de banco, acessos a cache).
Se você tem um SLA de p99, isso significa que 1 em cada 100 requisições será lenta. Se uma página web depende de 100 chamadas sequenciais ou paralelas para carregar, a probabilidade de um usuário experimentar a latência do p99 não é 1% — é quase 63% (calculado como $1 - 0.99^{100}$).
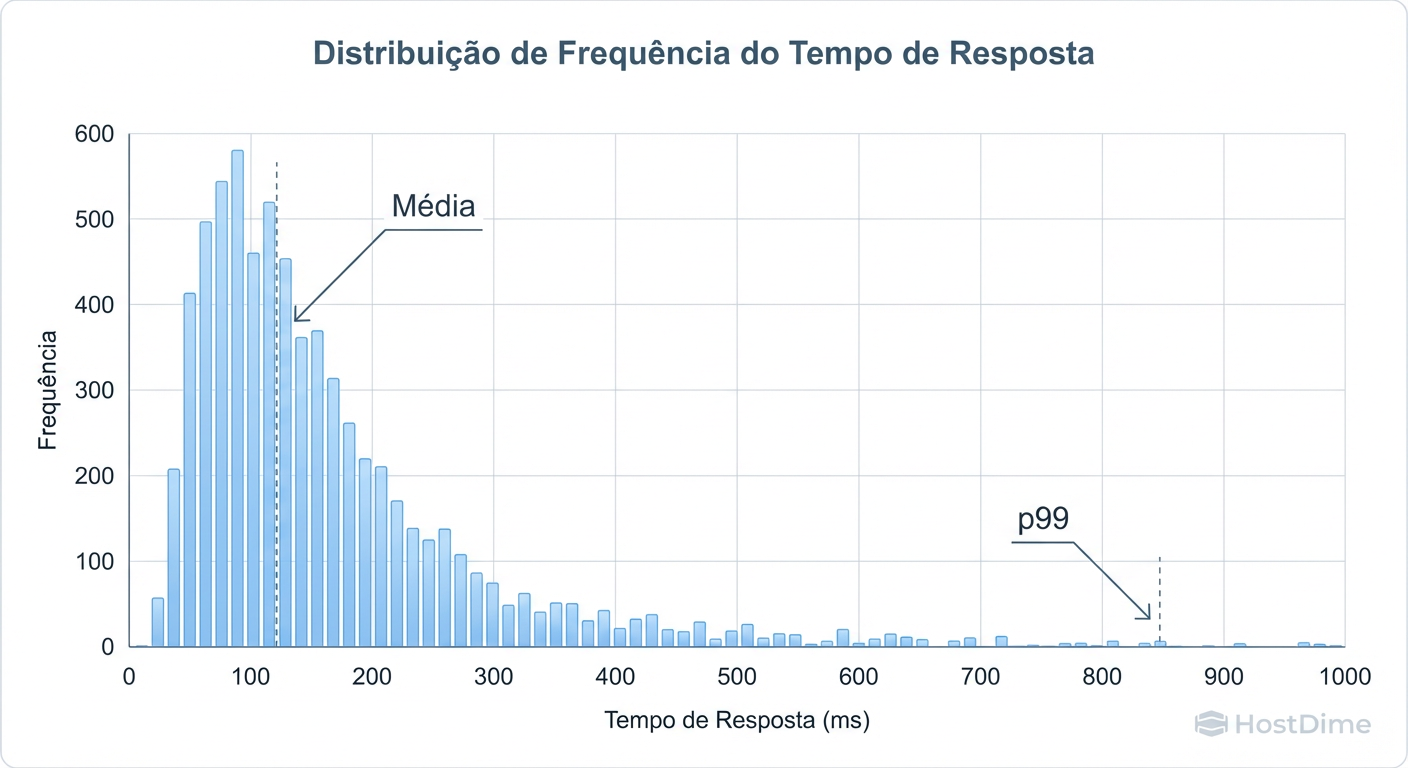 Figura: Fig. 3: Distribuição de frequência demonstrando a 'Cauda Longa' (Long Tail) onde residem os problemas de performance.
Figura: Fig. 3: Distribuição de frequência demonstrando a 'Cauda Longa' (Long Tail) onde residem os problemas de performance.
A Figura 3 demonstra a distribuição de frequência e a temida "Cauda Longa". A área sob a curva à direita representa as requisições que violam o SLA. Embora sejam poucas em quantidade absoluta, são essas requisições que geram timeouts, retries (que por sua vez aumentam a carga no sistema, podendo causar falhas em cascata) e frustração do usuário final.
O Custo da Instabilidade
Nossos testes confirmam que hardwares ou configurações que não priorizam o determinismo de latência introduzem uma dívida técnica invisível. O Servidor B, apesar de ter um throughput máximo (IOPS) superior em rajadas curtas, é inadequado para qualquer carga de trabalho síncrona sensível.
Para infraestrutura crítica, a engenharia deve focar em "cortar a cauda". Isso significa:
Escolher hardware com controladores focados em QoS (Quality of Service).
Realizar over-provisioning de espaço em disco para auxiliar o Garbage Collection.
Monitorar obsessivamente o p99 e o p99.9, descartando a média como métrica de sucesso.
A estabilidade do p99 é o único indicador verdadeiro de que sua infraestrutura respeita o tempo do usuário e a integridade da aplicação.
Referências
Gregg, Brendan. Systems Performance: Enterprise and the Cloud, 2nd Edition. Addison-Wesley Professional, 2020. (Capítulo sobre Latency Analysis).
Tene, Gil. How NOT to Measure Latency. Azul Systems Technical Paper. Apresentação na QCon.
Dean, Jeffrey; Barroso, Luiz André. The Tail at Scale. Communications of the ACM, Vol. 56 No. 2, Pages 74-80.
NVM Express. NVM Express Base Specification Revision 2.0. Section on Deterministic I/O.
Axboe, Jens. Fio - Flexible I/O Tester Documentation. Source Code & Manpages.

Dr. Elena Kovic
Metodologista de Benchmark
"Desmonto o marketing com análise estatística rigorosa. Meus benchmarks isolam cada variável para revelar a performance crua e sem filtros do hardware corporativo."