Metodologia SNIA PTS: como o precondicionamento revela a latência real de SSDs NVMe

Descubra por que benchmarks rápidos mentem. Entenda a especificação SNIA PTS, o processo de precondicionamento e como medir a latência de cauda real em SSDs NVMe corporativos.
A ficha técnica de um SSD NVMe moderno é, na melhor das hipóteses, um documento otimista. Fabricantes adoram estampar números colossais de IOPS e larguras de banda que desafiam os limites do barramento PCIe. No entanto, para engenheiros de infraestrutura e arquitetos de data centers, esses números de marketing representam um cenário irreal. Eles medem o drive em seu estado mais puro e intocado, uma condição que dura apenas alguns minutos em um ambiente de produção real.
Para descobrir a verdadeira capacidade de um dispositivo de armazenamento sob estresse contínuo, a indústria adota metodologias científicas rigorosas. O padrão ouro para essa avaliação é a especificação PTS (Performance Test Specification) da SNIA (Storage Networking Industry Association). O segredo dessa metodologia não está apenas em como os dados são lidos, mas no processo exaustivo de precondicionamento que força o hardware a revelar suas fraquezas arquitetônicas.
Resumo em 30 segundos
- Drives novos operam no estado FOB (Fresh Out of Box), entregando um desempenho artificialmente alto devido aos caches vazios.
- O precondicionamento satura o SSD, forçando o controlador a lidar com a coleta de lixo (Garbage Collection) e revelando a latência real.
- A metodologia SNIA PTS exige a comprovação matemática do estado estacionário (Steady State) antes que qualquer medição de benchmark seja considerada válida.
A ilusão do desempenho inicial em testes sintéticos
Quando você tira um SSD NVMe da caixa, ele se encontra no estado FOB (Fresh Out of Box). Todas as suas células NAND estão vazias e prontas para receber carga elétrica. Neste momento, qualquer gravação ocorre na velocidade máxima permitida pela interface e pelo controlador. Ferramentas de benchmark voltadas para o consumidor, como o CrystalDiskMark, exploram exatamente essa janela de oportunidade.
Esses testes sintéticos de curta duração gravam arquivos pequenos em rajadas rápidas. Eles se aproveitam do cache SLC (Single-Level Cell) dinâmico, uma porção da memória configurada para operar de forma mais rápida, mas com capacidade limitada. Enquanto o cache SLC não for totalmente preenchido, o drive parecerá um milagre da engenharia moderna.
O problema surge quando aplicamos essa lógica a um banco de dados transacional ou a um cluster de virtualização. Nesses cenários, o fluxo de dados é implacável. O cache SLC se esgota em questão de segundos ou minutos. A partir desse ponto, o controlador do SSD é forçado a gravar diretamente nas células TLC (Triple-Level Cell) ou QLC (Quad-Level Cell), que são inerentemente mais lentas. A ilusão do desempenho inicial desmorona, e a latência dispara.
O esgotamento do cache e a amplificação de escrita
A arquitetura da memória flash NAND possui uma peculiaridade física fundamental. Você pode ler e gravar dados em páginas (geralmente de 4KB a 16KB), mas só pode apagar dados em blocos inteiros (que contêm centenas de páginas). Quando um SSD está cheio e precisa gravar novos dados, ele não pode simplesmente sobrescrever as células antigas como faria um disco rígido magnético (HDD).
O controlador precisa ler o bloco inteiro para a memória, modificar as páginas necessárias, apagar o bloco físico na NAND e, finalmente, regravar o bloco inteiro. Esse processo é conhecido como Garbage Collection (Coleta de Lixo). A consequência direta dessa operação é a amplificação de escrita (Write Amplification Factor, ou WAF).
⚠️ Perigo: Ignorar a amplificação de escrita em dimensionamentos de storage corporativo resulta em falhas prematuras de hardware e quedas catastróficas de IOPS durante horários de pico.
Se o sistema operacional envia 4KB de dados, mas o SSD precisa mover e regravar 4MB internamente para acomodar essa mudança, o WAF é altíssimo. Durante esse processo, o controlador fica saturado gerenciando a movimentação interna de dados. As requisições de leitura e escrita do host (o servidor) são colocadas em fila, resultando em picos massivos de latência. O precondicionamento serve exatamente para forçar o drive a entrar nesse ciclo de Garbage Collection contínuo.
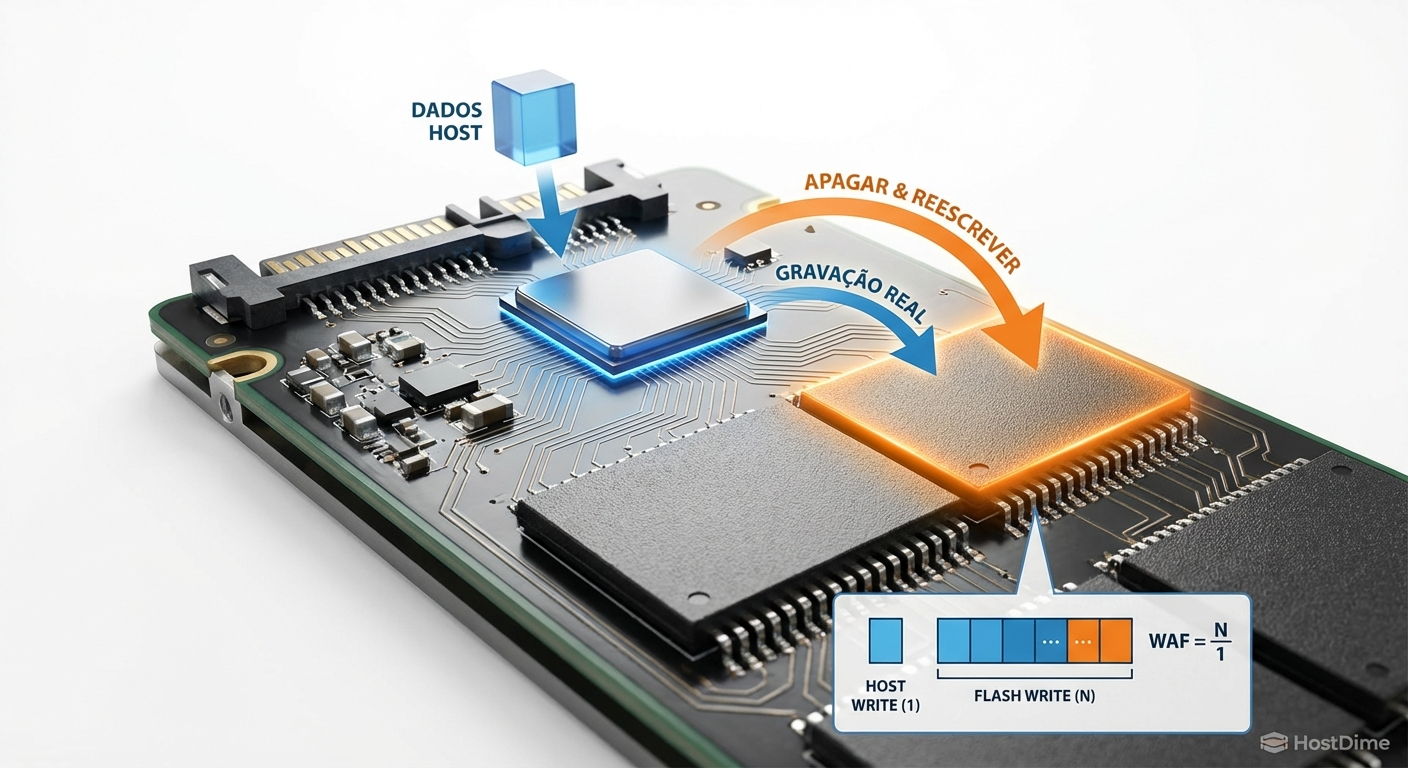 Figura: Diagrama ilustrando o processo de amplificação de escrita (WAF) no nível da célula NAND.
Figura: Diagrama ilustrando o processo de amplificação de escrita (WAF) no nível da célula NAND.
Por que rodar scripts básicos de FIO gera dados inúteis
O FIO (Flexible I/O Tester) é a ferramenta padrão da indústria para testes de armazenamento no Linux. No entanto, rodar um script de FIO por 60 segundos com uma carga de trabalho aleatória não fornece nenhum dado estatisticamente válido para ambientes corporativos. Você estará apenas medindo a velocidade do cache do controlador ou a performance residual do estado FOB.
Para obter dados reais, o drive precisa atingir o estado estacionário (Steady State). O estado estacionário é alcançado quando o desempenho do SSD para de cair e se estabiliza em um platô consistente, onde a taxa de gravação do host se iguala à capacidade do controlador de realizar o Garbage Collection em segundo plano.
💡 Dica Pro: Se o seu teste de FIO dura menos de duas horas em um SSD NVMe corporativo de alta capacidade, você não está medindo o estado estacionário. Você está medindo o tamanho do buffer interno.
Atingir esse platô exige tempo e uma quantidade massiva de gravações. Dependendo da capacidade do drive e do over-provisioning (espaço extra reservado no nível do firmware), pode ser necessário gravar o equivalente a duas ou três vezes a capacidade total do disco (Drive Writes Per Day, ou DWPD) de forma contínua antes que a estabilização ocorra.
A especificação SNIA PTS e a matemática do estado estacionário
A SNIA desenvolveu a especificação PTS para acabar com a anarquia dos benchmarks de armazenamento. A metodologia não confia no "olhômetro" para definir quando um drive atingiu o estado estacionário. Ela exige uma verificação matemática rigorosa baseada em janelas de medição.
O processo da SNIA PTS é dividido em fases estritas. Primeiro ocorre o Purge, onde o drive é formatado de forma segura (Secure Erase) para garantir um ponto de partida limpo. Em seguida, inicia-se o Workload Independent Preconditioning (WIP), que consiste em gravar sequencialmente em toda a capacidade do drive para preencher todas as células lógicas.
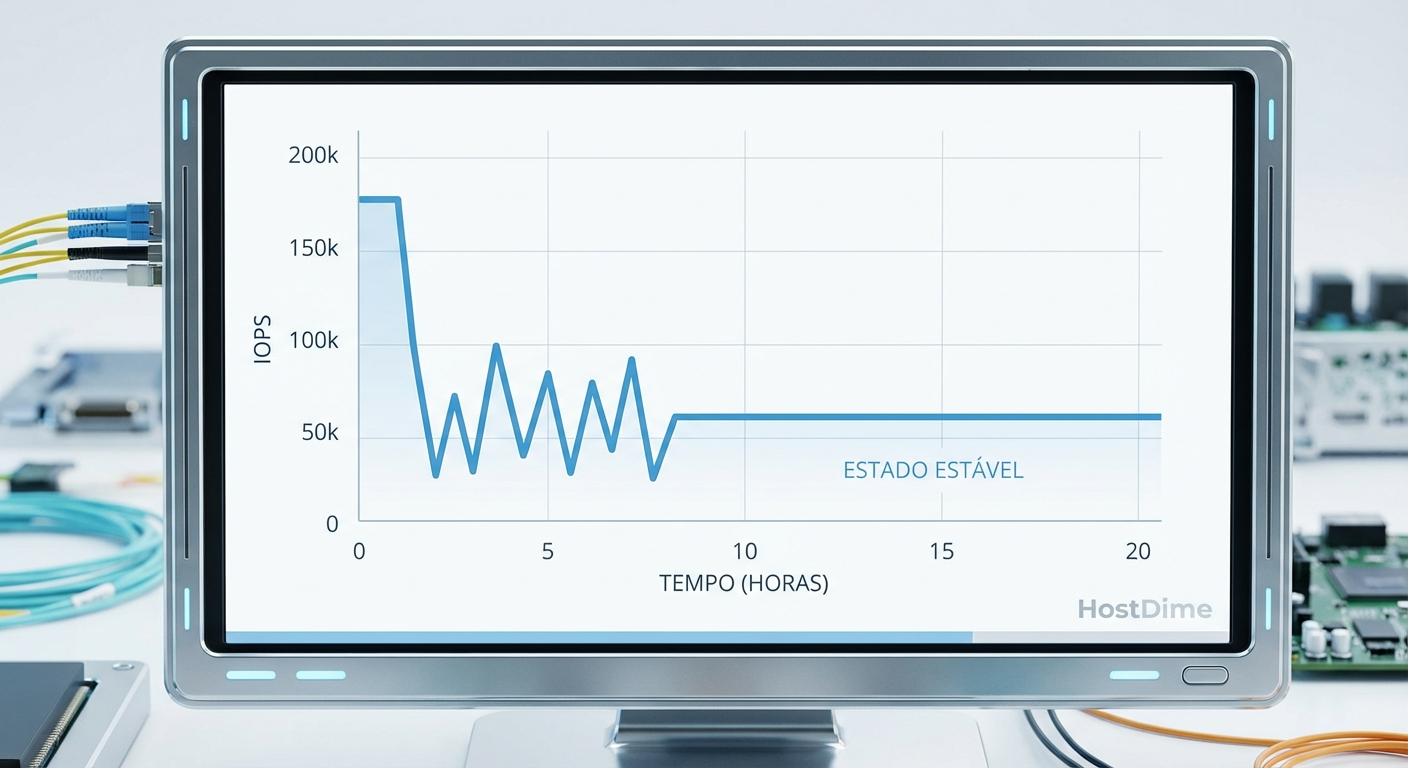 Figura: Gráfico de desempenho ao longo do tempo mostrando a transição do estado FOB para o estado estacionário.
Figura: Gráfico de desempenho ao longo do tempo mostrando a transição do estado FOB para o estado estacionário.
A fase mais crítica é o Workload Based Preconditioning (WBP). Aqui, a carga de trabalho exata que será testada (por exemplo, 4KB Random Write) é aplicada continuamente. O sistema monitora o desempenho em janelas de tempo específicas. O estado estacionário só é matematicamente confirmado quando a variação de IOPS entre as janelas de medição for inferior a 20%, e a inclinação da curva de desempenho (slope) for inferior a 10%.
Para ilustrar a diferença de rigor, observe a comparação abaixo:
| Característica | Benchmark de Marketing (ex: ATTO, Crystal) | Metodologia SNIA PTS Enterprise |
|---|---|---|
| Duração do Teste | Segundos a poucos minutos | Horas a dias (até atingir estabilidade) |
| Estado do Drive | FOB (Vazio, caches otimizados) | Precondicionado (Caches esgotados) |
| Foco da Métrica | Picos máximos de IOPS e Banda | Consistência, QoS e Latência sob estresse |
| Validação | Nenhuma (aceita o maior número) | Matemática (Variação < 20% em janelas de teste) |
| Uso Ideal | Edição de vídeo local, Gaming | Bancos de dados, SAN, Hypervisors (VMware, KVM) |
Medindo a latência de cauda com percentis de 99,99%
Quando o estado estacionário é finalmente validado, a verdadeira análise começa. Em infraestruturas de missão crítica, a latência média é uma métrica perigosa e enganosa. Se 99 operações levam 1 milissegundo, mas uma operação leva 100 milissegundos devido a um bloqueio no Garbage Collection, a média ainda parecerá excelente (cerca de 2 milissegundos). No entanto, para a aplicação que dependia daquela operação lenta, o sistema travou.
É por isso que a metodologia rigorosa foca na latência de cauda (Tail Latency), medida através de percentis. O percentil 99 (p99) indica a latência máxima experimentada por 99% das requisições. O percentil 99,99 (p99.99) vai além, isolando os piores cenários absolutos (os outliers).
 Figura: Histograma de distribuição de latência destacando o perigo da latência de cauda (p99.99).
Figura: Histograma de distribuição de latência destacando o perigo da latência de cauda (p99.99).
SSDs NVMe de classe corporativa diferem dos modelos de consumo não apenas pela durabilidade da NAND, mas pela previsibilidade de sua latência de cauda. Controladores corporativos possuem firmware otimizado para garantir Qualidade de Serviço (QoS). Eles limitam os picos de velocidade máxima para garantir que os processos de manutenção em segundo plano tenham recursos suficientes, evitando que o p99.99 ultrapasse limites aceitáveis (geralmente abaixo de 2 a 5 milissegundos, mesmo sob carga máxima).
O veredito para arquitetos de infraestrutura
Projetar arrays de armazenamento All-Flash ou clusters de hiperconvergência baseando-se em especificações de datasheet é um erro primário que custa caro em produção. A física da memória NAND é implacável. Sem o controle de variáveis adequado, qualquer teste de storage é apenas ficção científica.
 Figura: Engenheiro de infraestrutura analisando logs de verificação de estado estacionário e mapas de calor de latência.
Figura: Engenheiro de infraestrutura analisando logs de verificação de estado estacionário e mapas de calor de latência.
A recomendação técnica é clara. Ao avaliar novos fornecedores de SSDs NVMe ou ao homologar novos servidores, exija relatórios de desempenho baseados na especificação SNIA PTS. Se você mesmo for conduzir os testes usando FIO ou vdbench, implemente scripts de precondicionamento que saturem o disco por horas antes de registrar a primeira métrica. Conhecer o comportamento do seu storage no estado estacionário é a única forma de garantir que sua infraestrutura sobreviverá ao caos do mundo real.
Referências e leitura complementar
SNIA Solid State Storage Performance Test Specification (PTS) Enterprise v2.0.2: Documentação oficial detalhando as fórmulas matemáticas para verificação de estado estacionário.
JEDEC JESD218: Padrão de requisitos e métodos de teste para resistência (Endurance) de unidades de estado sólido.
RFC 7637 (NVMe over Fabrics): Para entender como a latência de cauda se propaga quando o armazenamento NVMe é distribuído através de redes RDMA ou TCP.
O que é o estado estacionário (steady state) em um SSD NVMe?
É a condição operacional onde o drive atinge um nível de desempenho consistente e previsível. Isso ocorre após o esgotamento de todos os caches dinâmicos e a estabilização dos algoritmos internos de garbage collection, refletindo o comportamento real do hardware em ambientes de produção contínua.Por que o precondicionamento é obrigatório para avaliar storage corporativo?
Drives novos, no estado FOB (Fresh Out of Box), apresentam velocidades de gravação artificialmente altas porque suas células NAND estão vazias. O precondicionamento força o SSD a realizar ciclos reais de leitura, escrita e apagamento simultâneos, revelando sua verdadeira latência e IOPS sob estresse contínuo.Qual a diferença entre a metodologia SNIA PTS e benchmarks comuns de desktop?
Benchmarks de desktop (como CrystalDiskMark) testam picos de velocidade em rajadas curtas, ideais para uso doméstico. A especificação SNIA PTS exige horas de gravação contínua com cargas de trabalho específicas para saturar o drive, garantindo que as medições sejam estatisticamente válidas para dimensionamento de data centers.
Dr. Elena Kovic
Metodologista de Benchmark
"Desmonto o marketing com análise estatística rigorosa. Meus benchmarks isolam cada variável para revelar a performance crua e sem filtros do hardware corporativo."