MinIO em Produção: O Guia de Sobrevivência para Performance e Consistência

Descubra por que clusters MinIO falham em escala. Uma análise profunda sobre JBOD vs RAID, consistência estrita e como evitar gargalos em redes de 100GbE.
A transição do armazenamento em bloco (SAN) para o armazenamento de objetos (Object Storage) como camada primária de persistência não é mais uma tendência; é um fato arquitetural. No entanto, tratar o MinIO como apenas um "S3 on-premise" que você instala via Docker em cinco minutos é o caminho mais rápido para um desastre em produção.
Quando desenhamos sistemas distribuídos de alta performance, a simplicidade da interface S3 esconde uma complexidade brutal de engenharia de dados. A questão não é se o MinIO funciona — ele é uma peça de engenharia brilhante em Go —, mas se a sua infraestrutura subjacente consegue alimentar esse motor sem engasgar.
Resumo em 30 segundos
- RAID de Hardware é veneno: O uso de controladores RAID tradicionais compete com o Erasure Coding do MinIO, aumenta a latência de gravação e mascara a degradação silenciosa de dados (bit rot).
- A falácia da rede: Em links de 100GbE, o gargalo deixa de ser a largura de banda e passa a ser a latência de cauda e a interrupção de CPU; tuning de kernel é obrigatório.
- Consistência tem preço: O MinIO oferece consistência estrita (read-after-write), o que exige coordenação síncrona. Isso impacta o TCO de IOPS quando comparado a sistemas eventualmente consistentes.
O paradoxo do hardware: JBOD vs. RAID
Há uma inércia perigosa em departamentos de TI corporativos de aplicar as mesmas regras de 2010 para o armazenamento moderno. A mais nociva delas é a insistência em controladores RAID de hardware.
Em uma arquitetura MinIO, o Erasure Coding (EC) é o mecanismo soberano de proteção de dados. Diferente do RAID, que opera no nível do bloco do disco, o EC opera no nível do objeto. Quando você coloca um controlador RAID físico "abaixo" do MinIO, você está introduzindo uma camada intermediária opaca que:
Duplica o esforço de paridade: O controlador calcula paridade (RAID 6, por exemplo) e o MinIO calcula paridade novamente (EC). Isso é desperdício de ciclos de CPU e I/O.
Esconde a saúde do disco: O MinIO precisa de visibilidade direta do drive (SMART) para curar objetos corrompidos. O RAID mascara setores defeituosos, impedindo que o software tome decisões inteligentes de autocura.
 Figura: Legenda: A eliminação da camada de abstração do RAID permite que o MinIO gerencie a integridade dos dados diretamente no nível do objeto via Erasure Coding.
Figura: Legenda: A eliminação da camada de abstração do RAID permite que o MinIO gerencie a integridade dos dados diretamente no nível do objeto via Erasure Coding.
A recomendação arquitetural é invariável: JBOD (Just a Bunch of Disks). Utilize controladores HBA (Host Bus Adapter) em modo IT mode (Initiator Target) para passar o controle físico dos discos diretamente ao sistema operacional.
💡 Dica Pro: Se você é obrigado a usar servidores que já possuem controladores RAID caros, configure cada disco como um volume RAID 0 individual. É uma "gambiarra" técnica, mas permite que o MinIO veja cada drive isoladamente, simulando um JBOD.
Sistema de arquivos: XFS é o padrão, ZFS é o risco
A escolha do sistema de arquivos subjacente é onde muitos projetos de home lab que viram produção falham. A tentação de usar ZFS por baixo do MinIO é grande devido aos seus recursos de snapshot e compressão. Contudo, isso é redundante e performaticamente perigoso.
O MinIO já gerencia a integridade dos dados. Colocar ZFS (que é Copy-on-Write) sob uma aplicação que gerencia seus próprios padrões de escrita gera uma amplificação de gravação desnecessária e fragmentação severa ao longo do tempo.
A arquitetura de referência exige XFS. Por quê?
Maturidade na alocação de extents.
Suporte robusto a DirectIO (que o MinIO utiliza para ignorar o cache de página do kernel quando necessário).
Recuperação rápida de metadados.
A formatação dos discos deve ser simples, focada em paralelismo. Nada de LVM (Logical Volume Manager) complexos que adicionam latência. Um disco físico = Um ponto de montagem.
O paradoxo da latência em redes de 100GbE
Mover dados a 100 Gbps (ou 400 Gbps em clusters de ponta) expõe gargalos que eram invisíveis em redes de 10 GbE. O problema deixa de ser "o tubo é pequeno" e passa a ser "o processador não consegue encher o tubo rápido o suficiente".
Em cenários de alta densidade, observamos frequentemente o fenômeno de latência de cauda (tail latency). A média de resposta pode ser 5ms, mas o percentil 99 (p99) salta para 200ms. Isso ocorre frequentemente devido a:
Buffer Bloat: Buffers de switch ou de placa de rede mal dimensionados.
Interrupções de CPU: O tráfego de rede bombardeia o núcleo 0 da CPU, criando um gargalo de processamento de interrupções (IRQ).
Para mitigar isso, a arquitetura de rede deve ser Leaf-Spine (para garantir largura de banda bisseccional constante) e o sistema operacional deve ser tunado.
 Figura: Legenda: Topologias Leaf-Spine minimizam o número de saltos (hops) entre nós do cluster, crucial para a fase de sincronização do Erasure Coding.
Figura: Legenda: Topologias Leaf-Spine minimizam o número de saltos (hops) entre nós do cluster, crucial para a fase de sincronização do Erasure Coding.
⚠️ Perigo: Não confie nas configurações padrão do Linux para 100GbE. Você deve ajustar o
net.core.rmem_max,net.core.wmem_maxe, crucialmente, habilitar oirqbalanceou fazer o pinning manual de filas de rede para núcleos de CPU específicos.
Consistência estrita e o custo do bloqueio distribuído
Diferente do S3 da AWS (que historicamente foi eventualmente consistente e migrou para consistência forte), o MinIO foi desenhado desde o início para ser estritamente consistente.
Isso significa que, após receber um HTTP 200 OK em uma operação de PUT, qualquer GET subsequente retornará a nova versão do objeto. Imediatamente. Não há "janela de propagação".
Para alcançar isso sem um banco de dados centralizado (o que seria um ponto único de falha), o MinIO utiliza um mecanismo de bloqueio distribuído determinístico. Isso tem um custo. Em um cluster geograficamente disperso ou com alta latência entre nós, o tempo de round-trip para garantir o quórum de escrita (Write Quorum) dita a performance total.
O Trade-off: Se sua aplicação exige milhões de IOPS de pequenos arquivos (ex: 1KB), o overhead do protocolo S3 e da coordenação de consistência será notável. O MinIO brilha em throughput (GB/s), mas em IOPS puros para arquivos minúsculos, o custo do protocolo HTTP e do bloqueio distribuído é fisicamente inevitável.
Benchmarking determinístico com Warp
Um erro clássico de arquitetos é testar storage de objetos usando dd ou fio em um ponto de montagem local. Isso testa o disco, não o serviço de armazenamento.
Para validar uma arquitetura MinIO, a ferramenta padrão é o Warp (desenvolvido pela própria MinIO). O Warp simula clientes S3 reais, operando em paralelo, realizando operações de PUT/GET/DELETE.
O que buscar nos resultados do Warp:
Não olhe para a média: A média esconde os problemas.
Foque no p99: Se o seu p99 de latência de escrita está instável, você tem um problema de rede (retransmissões TCP) ou um disco lento ("slow drive") segurando todo o conjunto de Erasure Coding.
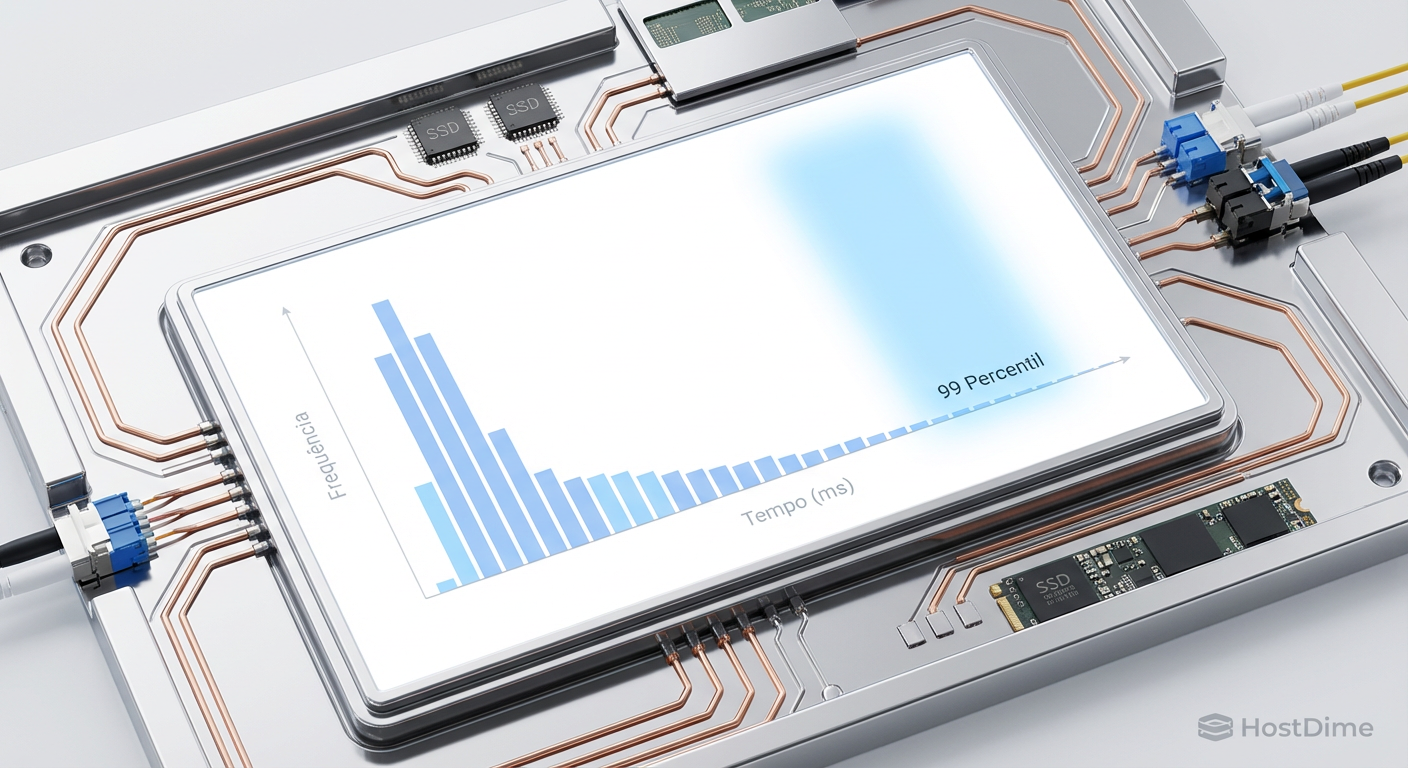 Figura: Legenda: A latência de cauda (p99) é o verdadeiro inimigo em sistemas distribuídos. Um único drive lento pode degradar a performance de todo o cluster devido à espera por quórum.
Figura: Legenda: A latência de cauda (p99) é o verdadeiro inimigo em sistemas distribuídos. Um único drive lento pode degradar a performance de todo o cluster devido à espera por quórum.
Arquitetura de Referência: O "Sweet Spot"
Baseado em implementações recentes (2024-2025), o ponto ideal de equilíbrio entre custo e performance para um cluster de produção Enterprise tende a convergir para:
Nós: Mínimo de 4 servidores (para tolerância a falhas robusta).
CPU: Frequência alta é preferível a contagem massiva de núcleos. O cálculo de Erasure Coding (SIMD AVX-512) beneficia-se de clock.
Memória: O MinIO usa agressivamente a RAM para cache de leitura. Quanto mais, melhor.
Rede: 25GbE é o mínimo aceitável. 100GbE é o recomendado para NVMe.
Discos: NVMe para camadas "Hot", HDD SAS para camadas "Warm/Cold". Nunca misture tipos de disco no mesmo pool (Server Pool).
Considerações Finais
Construir um cluster MinIO não é sobre instalar um binário; é sobre orquestrar hardware para eliminar gargalos. A ilusão de que "software-defined storage" resolve problemas de hardware ruim é a causa raiz da maioria das falhas em produção.
Se você tratar o MinIO como uma aplicação stateless qualquer, terá performance de laboratório. Se tratá-lo como um sistema de banco de dados distribuído que requer respeito à topologia de rede e à geometria do disco, você terá a infraestrutura mais resiliente e escalável que o dinheiro pode comprar hoje.
A escolha é entre conveniência na instalação ou sobrevivência na operação. Escolha a segunda.
Referências & Leitura Complementar
MinIO Erasure Coding Primer: Documentação técnica sobre a implementação de Reed-Solomon e distribuição de paridade.
RFC 2616 (HTTP/1.1): Compreensão fundamental sobre overhead de headers e conexões keep-alive em object storage.
Intel 64 and IA-32 Architectures Optimization Reference Manual: Seção sobre instruções SIMD (AVX-512) utilizadas para aceleração de hashing e criptografia.
JEDEC SSD Specifications: Para entendimento das diferenças reais de latência e endurance entre NVMe Consumer e Enterprise.

Otávio Henriques
Arquiteto de Soluções Enterprise
"Com duas décadas desenhando infraestruturas críticas, olho além do hype. Foco em TCO, resiliência e trade-offs, pois na arquitetura corporativa a resposta correta quase sempre é 'depende'."