Modernizando o catálogo de serviços: por que a latência substitui o 'Gold' no storage

Abandone os tiers genéricos de Gold, Silver e Bronze. Descubra como reestruturar seu catálogo de storage com foco em SLOs de latência, mitigando riscos contratuais e otimizando o TCO.
A era dos catálogos de serviços baseados em metais preciosos acabou. Definir um nível de serviço de armazenamento apenas como "Gold", "Silver" ou "Bronze" é uma prática obsoleta, juridicamente frágil e financeiramente ineficiente. No cenário atual de infraestrutura, onde arrays All-Flash e protocolos NVMe se tornam commodities, a distinção pelo tipo de mídia física (SSD vs. HDD) deixou de ser o único indicador de performance.
Para um Gerente de Nível de Serviço, a vaguidade é o inimigo. Um contrato que promete "Alta Performance" sem definir milissegundos é um convite aberto para disputas contratuais e penalidades. A modernização do catálogo exige uma transição da nomenclatura de marketing para a engenharia de métricas: a latência, especificamente a latência de cauda, é o novo padrão de verdade.
Resumo em 30 segundos
- Tiers nominais são riscos jurídicos: Classificações como "Gold" baseadas apenas em hardware não garantem performance sob carga e expõem o provedor a multas por descumprimento de expectativa.
- A média esconde o perigo: Métricas de latência média mascaram picos de lentidão (latência de cauda) que travam bancos de dados e aplicações críticas.
- Contratos baseados em SLO: A modernização exige substituir promessas vagas por Objetivos de Nível de Serviço (SLOs) numéricos, como "99,9% das operações abaixo de 2ms".
A ineficiência financeira dos modelos estáticos
Historicamente, o tier "Gold" significava discos SAS de 15k RPM ou, mais recentemente, SSDs Enterprise. O tier "Bronze" era relegado a discos SATA de alta capacidade (NL-SAS). O problema dessa abordagem estática é o desperdício de CAPEX e a ineficiência operacional.
Ao vender um tier "Gold" baseado puramente na alocação em um pool All-Flash, você entrega a capacidade máxima do hardware para uma aplicação que, muitas vezes, não necessita daquela performance 100% do tempo. Pior ainda: sem limites de QoS (Quality of Service) definidos no nível do hypervisor ou do storage array, uma única máquina virtual de desenvolvimento mal configurada pode sequestrar os IOPS de todo o pool "Gold", degradando a performance do ERP de produção que reside no mesmo tier.
💡 Dica Pro: A segregação lógica via software (Storage QoS) é superior à segregação física. É mais rentável vender um perfil de "2.000 IOPS garantidos" em um pool compartilhado do que dedicar discos físicos exclusivos para um cliente.
Financeiramente, isso é desastroso. Você é obrigado a superprovisionar hardware caro (NVMe/Flash) para garantir uma performance que não está sendo medida corretamente, apenas para manter a "sensação" de velocidade prometida pelo rótulo "Gold".
O risco jurídico da latência de cauda
Aqui reside o maior passivo oculto nos contratos de TI modernos. A maioria dos relatórios de SLA apresenta a latência média. Se o seu storage array reporta uma latência média de 1ms, o cliente parece satisfeito. No entanto, a média é uma métrica mentirosa para sistemas transacionais.
Se 99% das suas requisições levam 0,5ms, mas 1% das requisições levam 500ms (devido a garbage collection no SSD, lock de banco de dados ou saturação de link na SAN), a média continuará baixa. Porém, para a aplicação do cliente, aquele 1% representa timeouts, transações falhas e telas congeladas.
Isso se chama Latência de Cauda (Tail Latency) ou percentil 99 (p99).
Juridicamente, se o contrato estipula "Alta Disponibilidade e Performance" e o cliente prova que o sistema parou diversas vezes ao dia, a sua métrica de "média de 1ms" não servirá de defesa. O cliente argumentará, com razão, que o serviço foi interrompido. Definir SLAs baseados em p99 ou p99.9 (onde 99,9% das requisições devem ser atendidas abaixo de X milissegundos) é a única forma de blindar o contrato contra subjetividades.
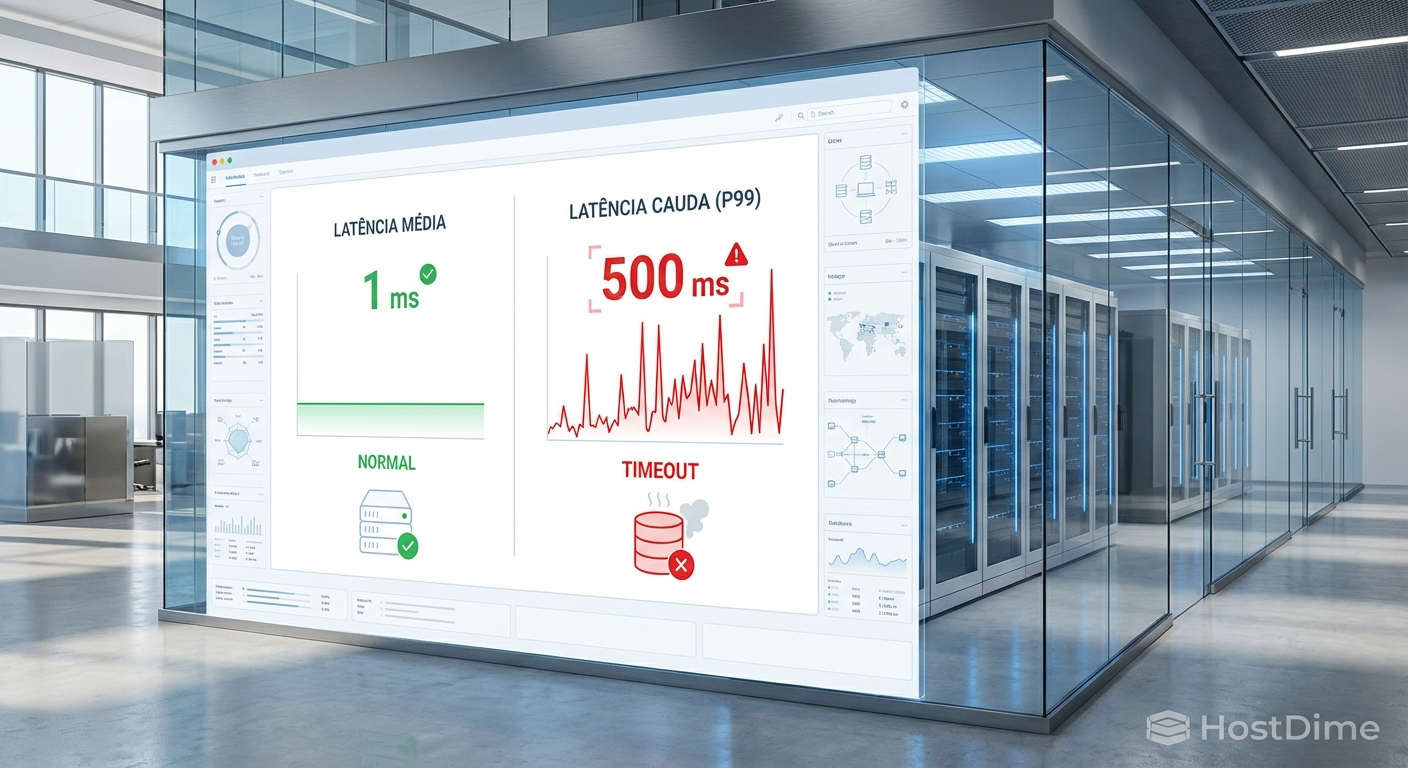 Figura: Visualização do risco: enquanto a média (esquerda) sugere normalidade, a latência de cauda (direita) revela os picos que causam a quebra do serviço.
Figura: Visualização do risco: enquanto a média (esquerda) sugere normalidade, a latência de cauda (direita) revela os picos que causam a quebra do serviço.
Transição de tiers nominais para objetivos mensuráveis
A migração de um catálogo baseado em "Metais" para um catálogo baseado em "Níveis de Serviço" exige rigor técnico. Não vendemos mais "Disco SSD". Vendemos "Comportamento de I/O".
Essa mudança permite que a equipe de infraestrutura utilize tecnologias como Tiering Automático ou Caching de forma transparente. Se o contrato especifica "Latência < 5ms", não importa se o dado está em um NVMe de última geração ou em um SSD SATA, desde que o objetivo seja cumprido. Isso devolve o controle do custo de infraestrutura para o provedor, mantendo a garantia contratual do cliente.
Abaixo, apresento uma estrutura comparativa para readequação de contratos de storage:
| Característica | Modelo Antigo (Risco Alto) | Modelo Moderno (SLO Focado) |
|---|---|---|
| Nomenclatura | Tier Gold / Silver / Bronze | Mission Critical / Business / Archive |
| Definição Técnica | Tipo de Disco (ex: SSD SAS) | Latência Máxima (p99) e IOPS/TB |
| Garantia | "Melhor Esforço" no hardware | Penalidade se p99 > X ms por Y minutos |
| Controle | Isolamento Físico (LUNs dedicadas) | QoS (Limites de IOPS e Banda via Software) |
| Métrica de Sucesso | Uptime do Storage | Tempo de Resposta da Aplicação |
A matemática do ROI e a aplicação de QoS
A implementação de QoS (Quality of Service) é o mecanismo técnico que viabiliza o modelo financeiro. Ao definir um teto (ceiling) e um piso (floor) de IOPS e banda para cada volume ou VM, transformamos o desempenho em um recurso finito e faturável.
Considere um ambiente de virtualização com VMware vSphere ou Hyper-V conectado a um storage SAN. Sem QoS, um processo de backup ou uma query SQL mal escrita pode saturar a controladora do storage, afetando todos os "vizinhos".
⚠️ Perigo: A falta de isolamento de I/O (Noisy Neighbor) é a principal causa de quebra de SLA em ambientes compartilhados. Multas contratuais decorrentes desses incidentes frequentemente superam a economia feita ao não segmentar os workloads.
Ao vender um perfil "Mission Critical" com garantia de 0,5ms de latência, você deve configurar o QoS para priorizar esses pacotes na fila de execução do storage e reservar a performance necessária. Inversamente, o perfil "Archive" deve ter um limite máximo de IOPS para impedir que operações de leitura em massa degradem o ambiente. O ROI (Retorno sobre Investimento) vem da capacidade de colocar mais clientes no mesmo hardware com segurança, pois os limites de software impedem a canibalização de recursos.
Auditoria contínua como mecanismo de defesa
Um contrato bem redigido é inútil sem evidências. A modernização do catálogo exige a implementação de ferramentas de monitoramento que guardem o histórico de latência granular (minuto a minuto, não médias horárias).
Em uma disputa sobre penalidades, o ônus da prova recai sobre o provedor de serviço. Se o cliente alegar lentidão na sexta-feira às 15:00, você deve ter o gráfico de dispersão de latência daquele volume específico. Se o gráfico mostrar que a latência do storage estava em 2ms, mas a latência da aplicação estava em 500ms, você provou que o problema é na camada de aplicação ou rede, isentando a infraestrutura de storage e evitando a multa.
A transparência radical, através de portais de autoatendimento onde o cliente pode ver seus próprios gráficos de consumo e performance em tempo real, reduz o atrito e aumenta a percepção de valor. O cliente deixa de comprar "espaço em disco" e passa a comprar "garantia de execução".
O imperativo da precisão contratual
A transição do modelo "Gold" para métricas de latência e IOPS não é apenas uma tendência técnica, é uma necessidade de sobrevivência comercial e jurídica. Ambientes de armazenamento modernos são complexos demais para serem descritos por adjetivos vagos. A falha em definir especificamente o que constitui uma "performance aceitável" resultará invariavelmente em clientes insatisfeitos e perdas financeiras através de compensações de crédito de serviço. Recomenda-se a revisão imediata de todos os contratos vigentes para a inclusão de cláusulas de latência de cauda e a exclusão de garantias baseadas puramente em hardware físico.
Qual a diferença entre SLA e SLO no contexto de storage?
O SLA (Service Level Agreement) é o instrumento contratual completo, que define as consequências jurídicas e financeiras (multas) do não cumprimento. O SLO (Service Level Objective) é a meta técnica específica dentro desse contrato. Por exemplo: o SLO é "manter a latência abaixo de 2ms em 99,9% do tempo". Se esse SLO for violado repetidamente, o SLA é quebrado e as penalidades são acionadas.Por que tiers baseados apenas em tipo de disco (SSD/HDD) são obsoletos?
Porque o meio físico não garante o resultado final. Um SSD Enterprise saturado por milhares de requisições simultâneas entregará uma performance pior do que um HDD mecânico ocioso. O que importa para a aplicação e para o negócio é o tempo de resposta (latência) e a consistência da entrega dos dados, independentemente se o dado está gravado em flash, disco rotacional ou memória de classe de armazenamento (SCM).Como medir a latência de cauda (tail latency) afeta o contrato?
A latência de cauda (p99 ou p99.9) expõe a realidade da experiência do usuário que a média esconde. Ignorá-la cria um cenário de "quebra de contrato silenciosa", onde a aplicação do cliente trava ou sofre timeouts, mas os relatórios mensais de média indicam que tudo está verde. Incluir a latência de cauda no contrato protege ambas as partes ao alinhar a métrica de infraestrutura com a realidade da aplicação.
Arthur Sales
Gerente de Nível de Serviço
"Vivo na linha tênue entre a conformidade e a violação contratual. Para mim, 99,9% não é disponibilidade; é prejuízo. Exijo garantias absolutas e aplicação rigorosa de penalidades."