Mongobleed (CVE-2025-14847): Quando o vazamento de memória expõe o Storage

Análise forense da CVE-2025-14847 (Mongobleed). Entenda como a falha no zlib do MongoDB expõe configurações do WiredTiger e por que snapshots imutáveis são sua única defesa em 2026.
O incidente identificado como Mongobleed (registrado sob a CVE-2025-14847) representa uma mudança de paradigma na segurança de infraestrutura de dados. Diferente de ataques tradicionais de injeção ou força bruta, esta vulnerabilidade explora a camada física de gerenciamento de memória do storage engine para exfiltrar dados sensíveis diretamente da RAM, contornando a criptografia de disco (Encryption at Rest).
Para administradores de armazenamento e engenheiros de confiabilidade de site (SREs), o Mongobleed não é apenas um problema de banco de dados; é um alerta crítico sobre como a integridade dos dados persistidos em SSDs e arrays NVMe depende intrinsecamente da higiene da memória volátil. Quando a chave de criptografia mestra reside no heap e pode ser lida por um pacote malformado, seus discos criptografados tornam-se legíveis para o atacante.
Resumo em 30 segundos
- O Vetor: Uma falha na biblioteca de compressão zlib dentro do engine WiredTiger permite leitura de memória fora dos limites (buffer over-read).
- O Risco de Storage: Chaves de criptografia (DEK/KEK) presentes na RAM são expostas, tornando a criptografia de disco (SED/LUKS) ineficaz contra exfiltração.
- A Solução: Backups lógicos são insuficientes. A recuperação exige reversão para snapshots de bloco imutáveis (SAN/NAS) anteriores à injeção do payload.
A anatomia da vulnerabilidade no engine WiredTiger
O WiredTiger é o motor de armazenamento padrão do MongoDB, responsável por gerenciar como os dados são escritos nos blocos físicos do disco. Ele atua como o intermediário crítico entre as solicitações lógicas da aplicação e os IOPS (Input/Output Operations Per Second) que atingem seus drives NVMe ou SAS.
A vulnerabilidade CVE-2025-14847 reside no subsistema de compressão de blocos. Para otimizar o uso de espaço em disco e reduzir a latência de I/O, o WiredTiger comprime as páginas de dados antes de enviá-las para o armazenamento persistente. O incidente ocorre quando o engine tenta descomprimir um bloco de dados manipulado que declara falsamente seu tamanho ou formato.
Em um cenário operacional normal, o gerenciador de memória aloca um buffer na RAM para processar essa descompressão. No entanto, devido a uma falha na verificação de limites na implementação da biblioteca zlib integrada, o processo de leitura não para no final do buffer alocado. Ele continua lendo segmentos adjacentes da memória heap do servidor.
💡 Dica Pro: Em servidores de banco de dados de alta performance, o heap de memória é onde residem os dados "quentes" antes do flush para o disco, além de credenciais de sessão e, crucialmente, as chaves de descriptografia de volume montado.
O vetor de ataque via compressão zlib malformada
O ataque não exige credenciais administrativas iniciais em configurações vulneráveis. O vetor de entrada é o envio de um pacote de dados especialmente criado que o servidor aceita e tenta processar. Este pacote contém um payload zlib com cabeçalhos corrompidos que instruem o descompressor a ler mais bytes do que os contidos no pacote.
Quando o serviço tenta processar essa requisição, ele retorna ao atacante não apenas um erro, mas um despejo de memória (memory dump) contendo o conteúdo dos endereços de memória adjacentes ao buffer.
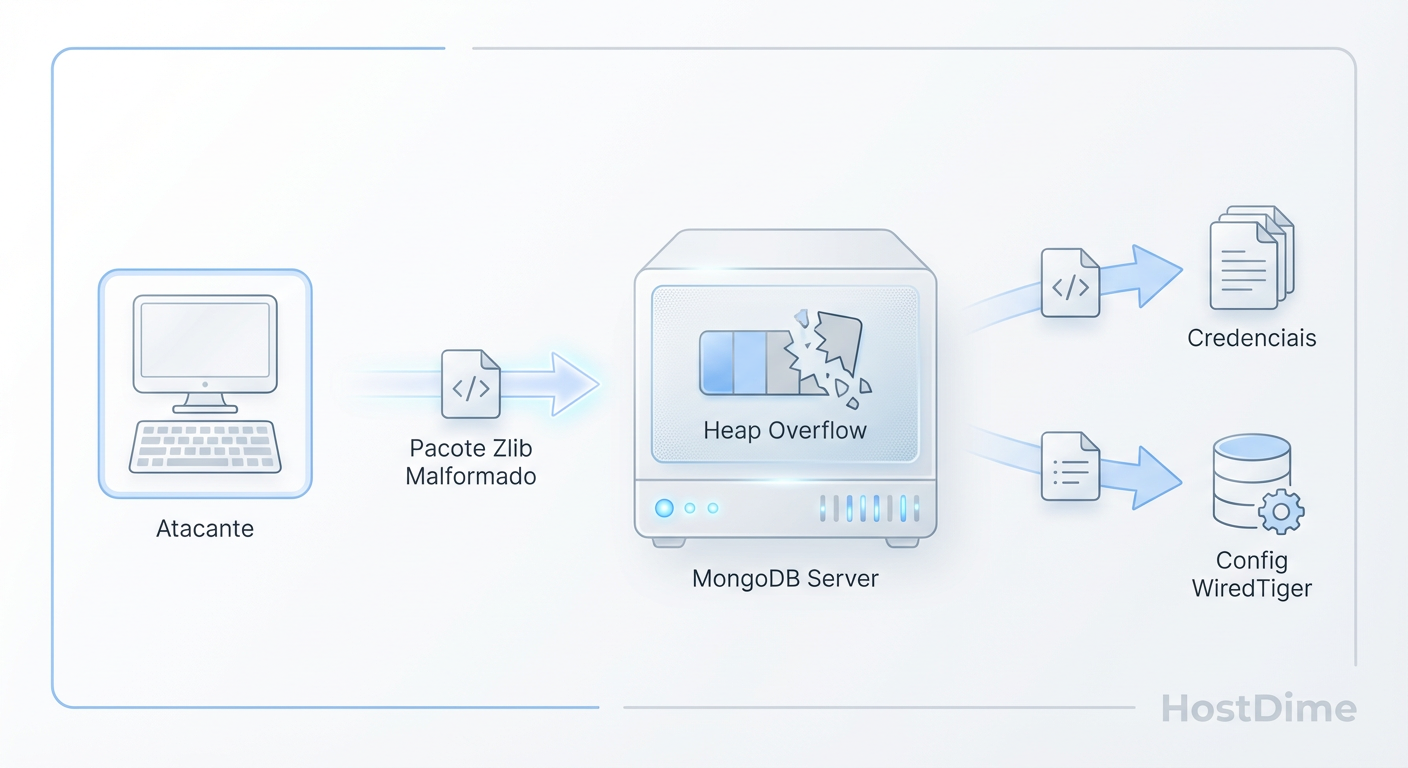 Fig. 1: O mecanismo de vazamento de memória heap via pacote zlib manipulado (CVE-2025-14847).
Fig. 1: O mecanismo de vazamento de memória heap via pacote zlib manipulado (CVE-2025-14847).
Este comportamento transforma o servidor de banco de dados em uma "bomba de vazamento". O atacante pode repetir a solicitação milhares de vezes por segundo, varrendo gigabytes de memória RAM. Para a infraestrutura de armazenamento, isso é invisível: não há aumento significativo de IOPS de escrita, nem corrupção de dados nos discos físicos inicialmente. O ataque é silencioso e reside inteiramente na camada de computação, mas visa comprometer a confidencialidade dos dados armazenados.
A falha dos backups lógicos em cenários de exfiltração de chaves
A gravidade do Mongobleed para arquitetos de storage reside na falsa sensação de segurança proporcionada pela criptografia de dados em repouso (Data at Rest Encryption).
Em arquiteturas corporativas modernas, utilizamos discos com auto-criptografia (SEDs) ou criptografia em nível de sistema de arquivos (como LUKS no Linux ou ZFS native encryption). Essas tecnologias protegem contra o roubo físico dos discos. Se alguém remover um drive NVMe do seu servidor no data center, os dados são ilegíveis sem a chave.
No entanto, para que o banco de dados funcione, essas chaves precisam estar presentes na memória RAM do servidor para descriptografar os dados lidos do disco e entregá-los à aplicação.
⚠️ Perigo: O Mongobleed permite que o atacante leia a memória onde essas chaves residem. Uma vez que o atacante possui a chave mestra extraída da RAM, ele pode descriptografar qualquer backup lógico (dump) que tenha exfiltrado anteriormente, ou até mesmo dados brutos se conseguir acesso posterior ao sistema de arquivos.
Neste cenário, o backup lógico (ex: mongodump) torna-se um vetor de risco. Se você restaurar um backup lógico em um ambiente onde as chaves já foram comprometidas, você não eliminou a persistência do atacante. Além disso, backups lógicos são lentos para restaurar (RTO alto) e exigem reidratação de dados, o que consome ciclos de CPU e I/O de disco massivos.
Imutabilidade de armazenamento como última linha de defesa
Diante de um comprometimento de memória que expõe chaves de criptografia, a única defesa confiável reside na camada de infraestrutura de armazenamento, especificamente através de Snapshots Imutáveis.
Diferente de backups lógicos, snapshots baseados em array (seja em um TrueNAS, NetApp, Pure Storage ou Dell PowerStore) operam no nível do bloco. Eles congelam o estado do sistema de arquivos em um ponto no tempo.
A imutabilidade (frequentemente referida como WORM - Write Once, Read Many) garante que, mesmo que o atacante tenha obtido privilégios de root no sistema operacional através da exploração inicial, ele não consiga deletar ou criptografar (ransomware) os snapshots armazenados no array de discos. O plano de controle do storage deve estar isolado do plano de controle do sistema operacional.
 Fig. 2: A diferença crítica de sobrevivência entre backups acessíveis pelo SO e snapshots isolados no nível do storage array.
Fig. 2: A diferença crítica de sobrevivência entre backups acessíveis pelo SO e snapshots isolados no nível do storage array.
A estratégia de recuperação para o CVE-2025-14847 exige que o administrador de storage ignore a integridade dos dados atuais (que devem ser considerados contaminados) e reverta os LUNs ou volumes para um snapshot criado antes do primeiro indicador de compromisso (IoC).
Protocolo de contenção e restauração via snapshots de SAN
Como Comandante de Incidentes, a prioridade é estancar o vazamento e restaurar a confiança nos dados. O procedimento abaixo assume um ambiente com armazenamento centralizado (SAN/NAS) ou armazenamento local com suporte a snapshots (ZFS/LVM/Btrfs).
1. Isolamento da Camada de Computação
Corte imediatamente o tráfego de entrada na porta do banco de dados (padrão 27017). Não desligue o servidor abruptamente se precisar de análise forense de memória, mas desconecte-o da rede pública.
- Ação de Storage: Se estiver usando iSCSI ou Fibre Channel, considere colocar os LUNs em modo Read-Only no nível do array para preservar o estado forense dos discos para análise posterior.
2. Identificação do Ponto de Recuperação (RPO)
Analise os logs de acesso para identificar o início das requisições anômalas (padrões de erro de descompressão zlib). O seu objetivo é encontrar o último snapshot "limpo".
- Métrica: Verifique a telemetria de latência de disco. Ataques de vazamento de memória raramente causam picos de latência de disco, então não use IOPS como indicador principal. Use logs de aplicação.
3. Execução do Revert (Rollback)
Não tente "limpar" o banco de dados. O estado da memória e as chaves foram comprometidos.
- Procedimento:
- Desmonte os volumes no sistema operacional.
- No console do Storage Array, execute o comando de Revert ou Clone do snapshot identificado.
- Apresente este novo volume ao host (ou a um novo host limpo).
- Tempo estimado: Em arrays modernos baseados em ponteiros (pointer-based snapshots), isso leva segundos, independentemente do tamanho do dataset (TB ou PB).
4. Rotação de Chaves (Key Rotation)
Este é o passo mais crítico pós-restauração. Como as chaves antigas foram expostas na RAM:
Gere novas chaves de criptografia (KEK/DEK).
Inicie um processo de re-criptografia dos dados. Isso gerará uma carga massiva de I/O nos discos, pois todos os dados precisarão ser lidos, descriptografados com a chave antiga e criptografados com a nova.
Impacto no Storage: Monitore a temperatura dos SSDs e a saturação da controladora. Este processo é intensivo.
Perguntas Frequentes
P: O uso de discos NVMe SED (Self-Encrypting Drives) previne o Mongobleed? R: Não. Os discos SED protegem os dados quando o sistema está desligado. Quando o sistema está ligado e o banco de dados está montado, o disco está "destravado" e a chave de sessão está na memória RAM, que é exatamente o alvo deste ataque.
P: A vulnerabilidade afeta sistemas de arquivos como ZFS ou EXT4 diretamente? R: Não diretamente. A falha está no código do WiredTiger (espaço do usuário). No entanto, se você usa compressão transparente no ZFS (lz4/zstd), isso é gerenciado pelo kernel e não é afetado por esta CVE específica. O risco é a exposição dos dados que a aplicação já leu do disco.
P: Posso mitigar isso desativando a compressão no banco de dados? R: Sim, desativar a compressão (snappy/zlib) no WiredTiger mitiga o vetor de ataque, mas aumentará drasticamente o consumo de espaço em disco e a utilização de I/O. Certifique-se de que seu array de storage tem capacidade (headroom) para absorver o aumento de volume de dados não comprimidos.
Previsão Operacional
O incidente Mongobleed de 2025 reforça uma tendência que observaremos com mais frequência: a migração da responsabilidade de segurança do perímetro de rede para a integridade do hardware e do firmware.
Prevemos que, nos próximos trimestres, os fabricantes de storage (Enterprise e Consumer) começarão a implementar recursos de "Enclaves Seguros" diretamente nos controladores de SSD e arrays, permitindo que operações criptográficas ocorram fora da memória principal do sistema operacional host. Até lá, a política de snapshots imutáveis e frequentes (a cada 15 ou 30 minutos) permanece a única garantia contra exfiltração de memória que compromete a camada de persistência.
A confiança cega no software de banco de dados acabou. A infraestrutura de armazenamento deve assumir a postura de "última fronteira" de defesa.
Referências & Leitura Complementar
CVE-2025-14847 Detail: National Vulnerability Database (NVD), publicado em Fev 2025.
SNIA Emerald™ Program: Especificações sobre eficiência e segurança energética em armazenamento de dados.
WiredTiger Architecture Guide: Documentação técnica sobre o gerenciamento de btree e compressão de blocos.
NIST SP 800-209: Security Guidelines for Storage Infrastructure (Revisão focada em Ransomware e Exfiltração).

Roberto Xavier
Comandante de Incidentes
"Lidero equipes em momentos críticos de infraestrutura. Priorizo a restauração rápida de serviços e promovo uma cultura de post-mortem sem culpa para construir sistemas mais resilientes."