Namespaces NVMe: isolamento real de I/O via hardware sem virtualização

Aprenda a usar Namespaces NVMe para dividir seu SSD fisicamente no controlador. Elimine o overhead de arquivos de disco virtual e garanta QoS no seu homelab.
Você montou aquele servidor dos sonhos para o seu homelab. Comprou um SSD NVMe Enterprise de 4TB, instalou o Proxmox ou o TrueNAS Scale e começou a subir contêineres. Tudo parece rápido, até que o Plex decide fazer a varredura da biblioteca ao mesmo tempo que seu banco de dados PostgreSQL está rodando uma query pesada. De repente, o iowait dispara e a latência da sua VM crítica vai para o espaço.
A culpa não é necessariamente da velocidade do disco, mas de como o controlador gerencia a fila de pedidos. A maioria de nós resolve isso particionando o disco (/dev/nvme0n1p1, p2, etc.), mas isso é uma ilusão de software. O controlador do SSD vê tudo como uma grande piscina de blocos.
É aqui que entram os Namespaces NVMe. É hora de parar de tratar seu armazenamento flash como se fosse um HD giratório glorificado e começar a usar os recursos que a especificação NVMe oferece nativamente.
Resumo em 30 segundos
- Particionamento é Software: Dividir um disco com
fdiskou LVM organiza os dados para o sistema operacional, mas o controlador do SSD ainda mistura todo o I/O em uma fila compartilhada.- Namespaces são Hardware: Criar namespaces divide o SSD logicamente no nível do firmware. O sistema operacional enxerga múltiplos dispositivos físicos (
/dev/nvme0n1,/dev/nvme0n2), permitindo filas de submissão e interrupções dedicadas.- Benefício Real: Redução drástica na "latência de cauda" (picos de lentidão) em cargas de trabalho mistas, isolando o I/O de bancos de dados do I/O de logs ou cache.
O problema do vizinho barulhento no silício
Quando você usa particionamento tradicional (MBR/GPT), o sistema operacional faz um ótimo trabalho em dizer "não grave os dados da partição A na partição B". Porém, assim que o comando de escrita sai do kernel e desce pelo barramento PCIe, essa distinção desaparece.
Para o controlador do SSD (o cérebro do disco), todos os pedidos de leitura e escrita entram em um funil gigantesco. Se uma partição de logs de sistema começa a bombardear o disco com pequenas escritas aleatórias (4K random write), o controlador precisa gerenciar a Garbage Collection e o Wear Leveling globalmente. Isso pode bloquear ou atrasar pedidos de leitura críticos de outra partição que deveria ter prioridade.
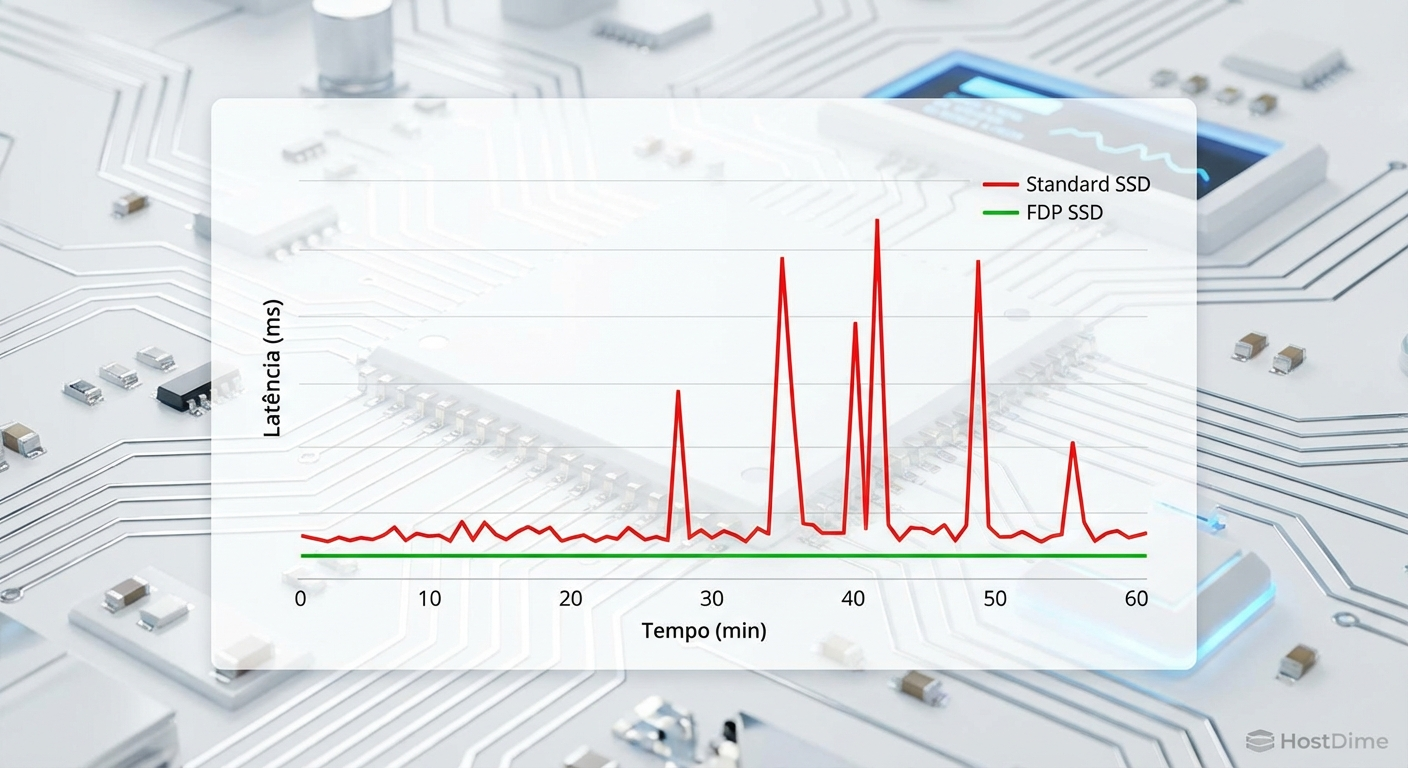 Figura: O gargalo do controlador: particionamento de software mistura fluxos de I/O antes de chegarem ao silício.
Figura: O gargalo do controlador: particionamento de software mistura fluxos de I/O antes de chegarem ao silício.
Isso é o clássico problema do "Noisy Neighbor" (Vizinho Barulhento), mas acontecendo dentro do firmware do seu drive. Em ambientes virtualizados, isso é mortal. Você acha que isolou a VM, mas o armazenamento subjacente está em guerra civil por recursos.
O que é um Namespace NVMe?
Na especificação NVMe (NVM Express), o armazenamento não é apenas um bloco monolítico. O padrão permite que a capacidade total da memória Flash seja fatiada em Namespaces.
Um Namespace é uma quantidade de memória não volátil (NVM) que pode ser formatada em blocos lógicos. Quando você cria múltiplos namespaces:
Visibilidade: O host (seu servidor) enxerga cada namespace como um dispositivo de bloco totalmente separado (
/dev/nvme0n1,/dev/nvme0n2). Não são partições; para o Linux, são discos diferentes.Filas de I/O: Cada namespace pode ter suas próprias filas de submissão e conclusão mapeadas para núcleos de CPU específicos.
QoS (Qualidade de Serviço): Controladores enterprise modernos conseguem aplicar políticas de arbitragem diferentes para namespaces diferentes.
💡 Dica Pro: Pense no particionamento como dividir um armazém com fita adesiva no chão. Pense nos Namespaces como construir paredes de concreto e portas de carga separadas para cada seção do armazém.
Tabela Comparativa: Partição vs. Namespace
| Característica | Particionamento (LVM/GPT) | Namespace NVMe |
|---|---|---|
| Gerenciamento | Sistema Operacional (Software) | Controlador SSD (Firmware) |
| Visão do Host | 1 Dispositivo (nvme0n1) com divisões |
Múltiplos Dispositivos (nvme0n1, nvme0n2) |
| Isolamento de I/O | Baixo (Filas compartilhadas) | Médio/Alto (Filas dedicadas possíveis) |
| Overhead de CPU | Processamento de FS/LVM | Quase Zero (Nativo do HW) |
| Uso Ideal | Organização de arquivos, Boot | Bancos de dados, VMs, ZFS SLOG |
Mão na massa: Gerenciando Namespaces no Linux
Vamos sair da teoria. Como você faz isso no seu servidor? Você vai precisar do pacote nvme-cli, que é a ferramenta padrão para conversar diretamente com o controlador.
⚠️ Perigo: Os comandos abaixo DESTRÓEM DADOS. Criar ou deletar namespaces apaga o mapeamento dos blocos. Faça backup de tudo antes de brincar com isso. Não faça isso no seu drive de boot enquanto o sistema roda nele.
1. Verificando o suporte
Nem todo SSD suporta isso. Drives consumer (como a maioria dos WD Blue ou Kingston NV2) geralmente suportam apenas 1 namespace. Drives "Prosumer" ou Enterprise (Samsung PM9A3, Micron 7450, Intel D7) suportam dezenas ou centenas.
Rode o comando para identificar o controlador:
nvme id-ctrl /dev/nvme0 | grep -E "nn|oacs"
nn(Number of Namespaces): Indica quantos namespaces o controlador suporta. Se for 1, fim de jogo.oacs: Indica capacidades opcionais. Procure por suporte a gerenciamento de namespace.
 Figura: Verificando a capacidade do controlador: drives Enterprise geralmente suportam até 128 namespaces.
Figura: Verificando a capacidade do controlador: drives Enterprise geralmente suportam até 128 namespaces.
2. O ciclo de vida: Detach, Delete, Create, Attach
O processo segue uma lógica estrita da especificação NVMe. Suponha que temos um SSD de 3.84TB e queremos dividi-lo.
Passo A: Desanexar e Deletar o existente Primeiro, precisamos remover o namespace padrão (geralmente ID 1) que ocupa todo o disco.
# Desanexa o namespace 1 do controlador 0
nvme detach-ns /dev/nvme0 -n 1 -c 0
# Deleta o namespace 1
nvme delete-ns /dev/nvme0 -n 1
Passo B: Criar novos Namespaces Aqui precisamos calcular o tamanho em blocos de 512 bytes ou 4096 bytes (LBA format). Vamos supor blocos de 4K. Para criar um namespace de 100GB: $100 \times 1024^3 / 4096 = 26214400$ blocos.
# Cria um namespace de 100GB (nsze = tamanho, ncap = capacidade)
nvme create-ns /dev/nvme0 -s 26214400 -c 26214400 -f 0 -d 0 -m 0
O comando retornará o ID do novo namespace (ex: 1). Repita para o segundo namespace (ex: ID 2).
Passo C: Anexar ao Controlador Criar não basta, você precisa "plugar" o namespace no controlador para o OS ver.
nvme attach-ns /dev/nvme0 -n 1 -c 0
nvme attach-ns /dev/nvme0 -n 2 -c 0
nvme reset /dev/nvme0
Agora, ao rodar lsblk, você verá /dev/nvme0n1 e /dev/nvme0n2 como se fossem dois SSDs físicos distintos instalados na máquina.
Por que isso importa para Performance?
A mágica acontece nas filas. O protocolo NVMe foi desenhado para paralelismo massivo (até 64K filas).
Quando você usa namespaces distintos, o driver NVMe do Linux pode alocar vetores de interrupção (MSI-X) e pares de filas (Submission/Completion Queues) de forma mais eficiente. Se você passar o /dev/nvme0n1 diretamente para uma VM (Passthrough de bloco) e o /dev/nvme0n2 para outra, você reduz drasticamente a contenção de lock no kernel do host.
O impacto na Latência de Cauda (Tail Latency)
Em testes de laboratório com cargas mistas (banco de dados transacional + backup sequencial), a diferença não aparece tanto no throughput máximo (MB/s), mas na latência p99 (o 1% das operações mais lentas).
Com particionamento lógico, quando o backup inicia, a latência do banco de dados pode saltar de 0.1ms para 15ms. Com namespaces, o controlador consegue intercalar os comandos de forma mais justa, mantendo a latência do banco de dados estável, muitas vezes abaixo de 2ms, mesmo com o backup rodando no namespace vizinho.
 Figura: Comparativo de latência: Namespaces oferecem consistência e previsibilidade sob carga pesada.
Figura: Comparativo de latência: Namespaces oferecem consistência e previsibilidade sob carga pesada.
Além do Básico: NVM Sets e Endurance Groups
Para os puristas do isolamento, o padrão NVMe 1.4 introduziu conceitos ainda mais profundos: NVM Sets e Endurance Groups.
Enquanto Namespaces são divisões lógicas, NVM Sets tentam alinhar esses namespaces a canais físicos de NAND específicos no controlador. Isso significa isolamento físico real dentro do mesmo pacote. Se o canal 1 e 2 estão ocupados gravando no Namespace A, o Namespace B (nos canais 3 e 4) tem largura de banda intocada.
Isso é raro em drives de entrada, mas comum em hardware de Datacenter (como a série DC da Intel/Solidigm ou Kioxia CM6/7). Se você tem um desses no seu homelab, configurar NVM Sets é o ápice da performance sem comprar múltiplos drives.
Veredito do Homelab
Vale a pena o trabalho?
Se você roda um servidor de arquivos simples ou um media center onde tudo é leitura sequencial, não. O particionamento padrão é suficiente e menos arriscado.
Porém, se você está construindo um hypervisor (Proxmox/ESXi/XCP-ng) e quer extrair cada gota de performance de um único SSD NVMe U.2 ou U.3 de alta capacidade, sim. Usar namespaces permite que você entregue dispositivos de bloco "quase-físicos" para suas VMs críticas, garantindo que o banco de dados do Home Assistant não engasgue quando o Nextcloud estiver fazendo indexação.
É uma daquelas otimizações que não custa dinheiro (apenas tempo de leitura de manual), mas que separa os entusiastas dos operadores sérios.
 Figura: O hardware certo na configuração certa: SSDs Enterprise U.2 são os candidatos ideais para uso de múltiplos namespaces.
Figura: O hardware certo na configuração certa: SSDs Enterprise U.2 são os candidatos ideais para uso de múltiplos namespaces.
Referências & Leitura Complementar
Para quem quer ir direto à fonte e entender os bits e bytes:
NVM Express Base Specification 2.0: Seção sobre Namespace Management e I/O Command Sets.
SNIA (Storage Networking Industry Association): Whitepapers sobre Performance Isolation in NVMe SSDs.
Manuais do nvme-cli: Documentação oficial da ferramenta de linha de comando para Linux.
Perguntas Frequentes (FAQ)
Qual a diferença entre particionar com fdisk e criar Namespaces NVMe?
O particionamento (fdisk/gdisk) é uma abstração de software que o sistema operacional gerencia; o controlador do SSD vê tudo como um único volume e mistura as operações. Namespaces são divisões lógicas no nível do firmware do controlador, permitindo que o sistema veja múltiplos dispositivos físicos independentes, possibilitando filas de I/O dedicadas e isolamento real de recursos.Todo SSD NVMe suporta múltiplos namespaces?
Não. A maioria dos SSDs de consumo (M.2 para desktops e laptops) suporta apenas um namespace padrão, pois o foco é custo e simplicidade. O suporte a múltiplos namespaces (geralmente até 128) é uma característica comum em SSDs Enterprise (formatos U.2, U.3, E1.S) e alguns modelos "Prosumer" de alto desempenho focados em workstation.Namespaces NVMe substituem o SR-IOV?
Eles são complementares, não substitutos. Namespaces dividem o armazenamento lógico dentro do drive. O SR-IOV (Single Root I/O Virtualization) virtualiza a interface PCIe para apresentar múltiplos controladores virtuais (VFs) ao sistema. Usar ambos juntos oferece o "santo graal" do isolamento: cada VM recebe seu próprio controlador virtual PCIe (via SR-IOV) atrelado a um namespace dedicado, eliminando quase todo o overhead do hypervisor.
Marcos Lopes
Operador Open Source (Self-Hosted)
"Troco licenças proprietárias por soluções open source robustas, ciente de que a economia financeira custa suor na manutenção. Defensor da soberania de dados e da força da comunidade."