NVMe Of A Revolucao De Performance No Armazenamento Em Rede

A evolução do hardware de armazenamento expôs uma dívida técnica crítica na infraestrutura de datacenter. Enquanto a mídia de armazenamento transitou de **HDDs ...
NVMe Of A Revolucao De Performance No Armazenamento Em Rede
O Gargalo do Legado: Por que o iSCSI não basta mais
A evolução do hardware de armazenamento expôs uma dívida técnica crítica na infraestrutura de datacenter. Enquanto a mídia de armazenamento transitou de HDDs mecânicos (latência de milissegundos) para Flash/NVMe (latência de microssegundos), os protocolos de transporte estagnaram.
O iSCSI, embora onipresente e de baixo custo de implementação, baseia-se no conjunto de comandos SCSI, desenhado há décadas para dispositivos rotacionais. Este legado impõe limitações severas em cenários de alta performance:
Serialização vs. Paralelismo: O NVMe foi arquitetado para o paralelismo massivo das CPUs modernas (até 64.000 filas de comando). O iSCSI/SCSI opera fundamentalmente com uma fila única ou limitada, criando um gargalo de serialização que impede a saturação da banda disponível.
Overhead de Protocolo e CPU: O encapsulamento de comandos SCSI sobre TCP/IP exige ciclos excessivos de CPU para processamento de interrupções e context switching. Em arquiteturas de alta densidade, isso resulta em latência induzida pela rede superior à latência da própria mídia de armazenamento.
Custo de Oportunidade: Implementar All-Flash Arrays (AFA) de alto custo e conectá-los via iSCSI resulta em um ROI degradado. Você paga pela performance do NVMe, mas é limitado pela pilha de software do protocolo.
Para cargas de trabalho críticas que exigem IOPS massivo e latência determinística, o iSCSI deixou de ser uma opção de "bom custo-benefício" para se tornar o principal inibidor de escalabilidade.
O Que é NVMe-oF e Como Ele Funciona
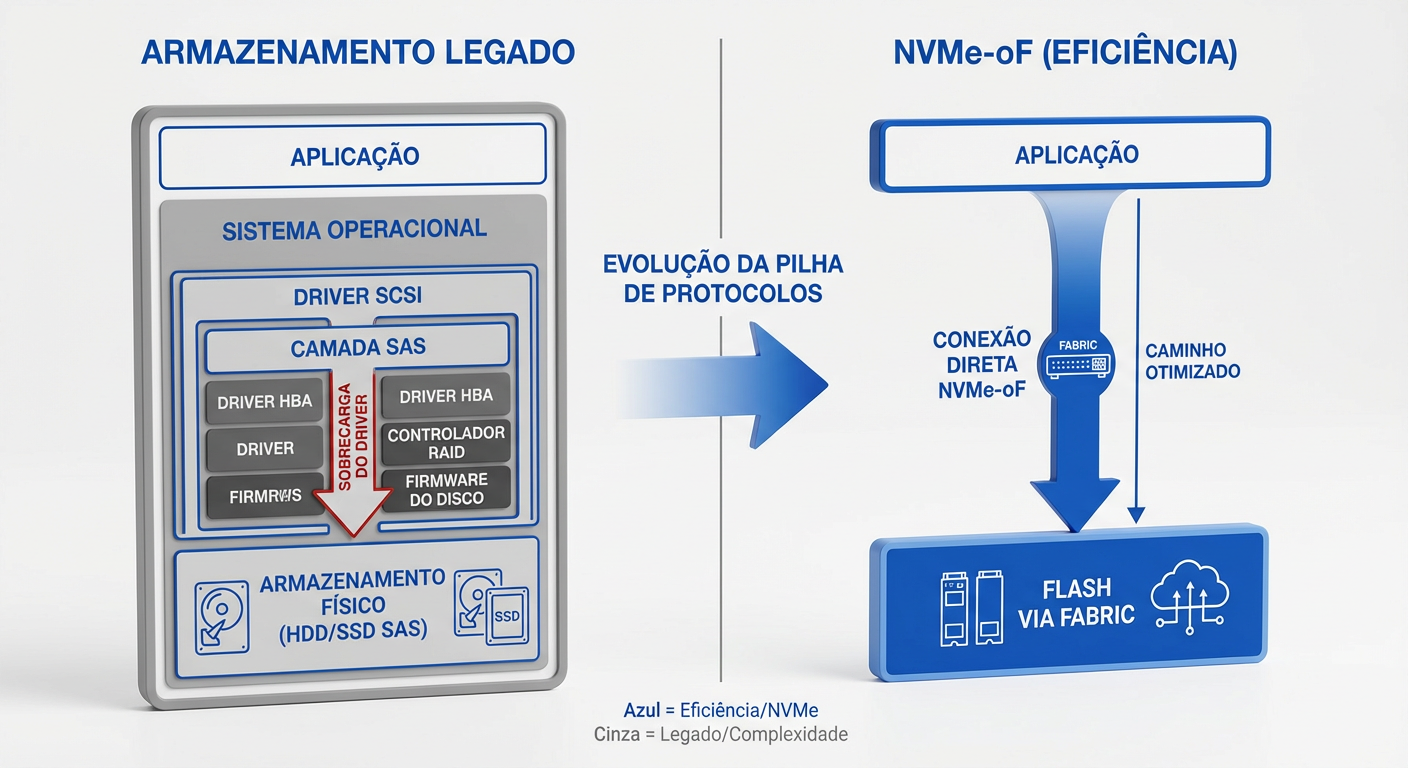
O NVMe over Fabrics (NVMe-oF) não é apenas um novo protocolo de transporte, mas uma extensão da arquitetura NVMe projetada para escalar o conjunto de comandos NVMe — nativo do barramento PCIe — através de malhas de rede de alta performance. O objetivo fundamental é desacoplar o armazenamento do compute, mantendo a latência em níveis de microssegundos, comparáveis ao armazenamento local.
Tecnicamente, o NVMe-oF elimina o gargalo histórico da tradução de comandos. Enquanto protocolos legados (iSCSI, FCP) exigem que o sistema operacional converta instruções de armazenamento para o padrão SCSI — serializando I/O e consumindo ciclos preciosos de CPU —, o NVMe-oF encapsula comandos NVMe diretamente em pacotes de transporte.
O funcionamento baseia-se na extensão lógica das filas de submissão e conclusão do NVMe através da rede. Ao utilizar transportes que suportam RDMA (Remote Direct Memory Access) ou Fibre Channel Gen 6+, o protocolo realiza um bypass do kernel do sistema operacional. Isso permite que dados sejam movidos diretamente da memória da aplicação para o array de storage, estendendo o barramento PCIe através do data center. O resultado é uma infraestrutura onde a latência de rede se torna negligenciável, entregando performance de Direct Attached Storage (DAS) com a eficiência de gerenciamento de uma SAN.
Os Três Pilares de Transporte: TCP, RDMA e FC
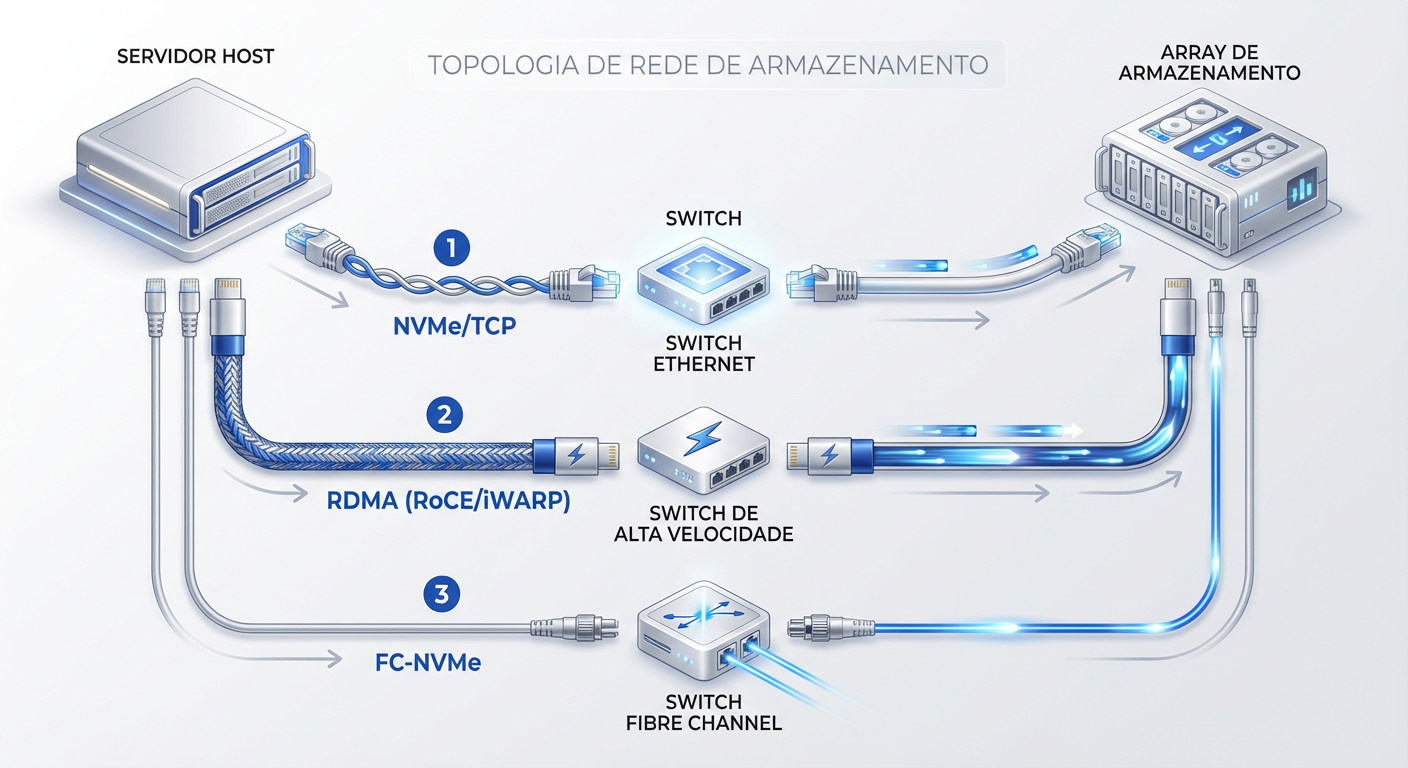
A desagregação do armazenamento via NVMe-oF depende fundamentalmente da escolha da camada de transporte ("Fabric"). Para o arquiteto, essa decisão não é apenas técnica, mas um balanço entre custo de infraestrutura (CAPEX), complexidade operacional (OPEX) e requisitos de latência.
1. NVMe/TCP: Custo e Ubiquidade
É a opção mais acessível e de rápida implementação.
Vantagem: Utiliza infraestrutura Ethernet padrão (switches e NICs comuns) e a pilha TCP/IP existente. Baixo CAPEX e facilidade de escala.
Trade-off: Introduz maior overhead de CPU no host e no target para processamento do protocolo, resultando em latência ligeiramente superior ao RDMA.
Veredito: Ideal para ambientes cloud-native, virtualização generalista e cenários onde o custo por porta é crítico.
2. RDMA (RoCE v2 e iWARP): Performance Extrema
Focado em eliminar gargalos de processamento através de Kernel Bypass e Zero-Copy Networking.
Vantagem: Permite leitura/escrita direta na memória remota sem intervenção da CPU do host. Oferece as menores latências (próximas ao DAS - Direct Attached Storage) e maior throughput.
Trade-off: Exige hardware específico (RNICs) e, no caso do RoCE v2, uma rede Ethernet configurada para ser lossless (PFC/ECN), aumentando a complexidade de gestão de rede.
Veredito: Obrigatório para HPC, Treinamento de IA/ML e bancos de dados de alta transação.
3. FC-NVMe: Proteção de Investimento
Projetado para ambientes brownfield com infraestrutura SAN Fibre Channel consolidada.
Vantagem: Confiabilidade determinística e entrega de pacotes sem perdas (credit-based flow control). Permite rodar tráfego NVMe e SCSI (FCP) simultaneamente na mesma fibra (Gen 5 16GFC ou superior).
Trade-off: Custo elevado de HBAs e switches FC dedicados. Isolado da rede de dados convergente.
Veredito: A escolha lógica para modernizar arrays em empresas que já possuem grandes investimentos em SAN Fibre Channel e equipes especializadas.
Arquitetura Desagregada e Casos de Uso Reais
O NVMe-oF é o habilitador técnico da Infraestrutura Composable, permitindo a transição do modelo rígido de DAS (Direct Attached Storage) para uma arquitetura totalmente desagregada. Neste cenário, o armazenamento é centralizado em JBOFs (Just a Bunch of Flash) acessíveis via fabric, desacoplando linearmente a escalabilidade de computação da escalabilidade de capacidade.
Do ponto de vista analítico, o principal trade-off é a introdução de uma camada de rede versus a eficiência de recursos. Contudo, com a sobrecarga do protocolo NVMe-oF sendo negligenciável (adicionando menos de 10µs de latência comparado ao NVMe local), o ganho em utilização de ativos supera a complexidade da fabric. Eliminamos o problema de "stranded capacity" (armazenamento ocioso preso em servidores de computação) e "stranded compute" (CPUs ociosas esperando I/O), otimizando drasticamente o TCO.
Aplicações Práticas e Impacto Arquitetural
AI/ML e HPC: Cargas de trabalho intensivas em dados exigem que o armazenamento acompanhe a velocidade das GPUs. O NVMe-oF permite que múltiplos servidores de GPU acessem um pool compartilhado de flash com throughput massivo, saturando links de 100/400GbE. Tecnologias como GPUDirect Storage alavancam o NVMe-oF para mover dados diretamente do JBOF para a memória da GPU, contornando a CPU e eliminando gargalos de barramento PCIe.
Bancos de Dados de Alta Transação (OLTP/NoSQL): Para aplicações sensíveis à latência (ex: Cassandra, MongoDB, Oracle Exadata), o NVMe-oF oferece performance de armazenamento local com a resiliência de um SAN. A arquitetura permite High Availability (HA) instantâneo: se um nó de computação falha, o volume de dados no JBOF pode ser remontado em outro nó em milissegundos, sem a necessidade de replicação síncrona custosa via rede.
Nuvem Privada e Virtualização: Em ambientes Kubernetes ou VMware, a desagregação permite alocação dinâmica de IOPS e capacidade por tenant. Isso facilita a implementação de QoS (Quality of Service) granular e reduz o over-provisioning, permitindo que arquitetos desenhem clusters onde o armazenamento cresce independentemente do número de licenças de hypervisor ou núcleos de CPU.
Veredito Técnico: O Futuro do Storage é na Fabric
A transição para NVMe-oF (NVMe over Fabrics) não representa apenas um ganho incremental de velocidade, mas uma mudança fundamental na arquitetura de data centers: a desagregação total entre computação e armazenamento sem penalidade de latência.
Para o Arquiteto de Soluções, a decisão de migração deve basear-se em uma análise rigorosa de custo-benefício:
Trade-offs e Custo: A implementação exige investimento inicial elevado em infraestrutura de rede (switches 100GbE+, SmartNICs, RDMA). Contudo, o retorno sobre o investimento (ROI) é realizado através da maximização da utilização dos recursos. Ao eliminar o over-provisioning típico de arquiteturas DAS (Direct Attached Storage), reduz-se o footprint físico e o consumo energético.
Escalabilidade: A tecnologia permite escalar performance e capacidade de forma independente. O gargalo deixa de ser o protocolo de transporte (SCSI) e passa a ser a eficiência da própria aplicação.
Estratégia de Adoção: Evite a abordagem "big bang". Priorize a migração para workloads sensíveis à latência (HPC, AI/ML, Bancos de Dados em Tempo Real). Aplicações legadas com baixo I/O não justificarão o custo do prêmio por porta na Fabric.
Em suma, o NVMe-oF é o alicerce para infraestruturas definidas por software (SDS) de próxima geração. A pergunta não é "se" adotar, mas quando a densidade dos seus workloads tornará o armazenamento tradicional o maior passivo da sua operação.

Ricardo Vilela
Especialista em Compras/Procurement
"Especialista em dissecar contratos e destruir argumentos de vendas. Meu foco é TCO, SLAs blindados e evitar armadilhas de lock-in. Se não está no papel, não existe."