NVMe over TCP: O Fim do Gargalo SCSI nas Redes Corporativas

Descubra como o NVMe over TCP elimina a latência do iSCSI sem a complexidade do RoCE. Análise técnica de filas, overhead de CPU e benchmarks reais para arquitetos de storage.
Você já investiu uma fortuna em arrays All-Flash, migrou seus servidores para as gerações mais recentes de processadores e implementou uma rede de 100GbE. Ainda assim, seu DBA continua reclamando de latência em picos de carga e o tempo de resposta das VMs críticas não condiz com o hardware instalado. O culpado provável não é o disco, nem o cabo, mas o idioma que eles falam.
Durante décadas, o protocolo SCSI foi a lingua franca do armazenamento. Ele serviu bem na era dos HDDs mecânicos, onde a latência do disco (ms) mascarava a ineficiência do protocolo. Mas na era do NVMe, onde a latência é medida em microssegundos (µs), encapsular comandos NVMe dentro de frames SCSI (como fazemos no iSCSI tradicional) é como tentar transmitir vídeo 4K via código morse.
O NVMe over TCP (NVMe/TCP) surgiu não apenas como uma evolução, mas como uma necessidade fisiológica do datacenter moderno. Ele promete entregar a performance do barramento PCIe através da rede Ethernet padrão, sem a complexidade de configurações lossless exigidas pelo RDMA.
Resumo em 30 segundos
- O problema: O protocolo iSCSI exige uma tradução custosa (SCSI para NVMe) que consome CPU e adiciona latência, desperdiçando o potencial dos SSDs modernos.
- A solução: O NVMe/TCP transporta comandos NVMe nativos dentro de pacotes TCP padrão, eliminando a camada SCSI e permitindo paralelismo massivo.
- A vantagem: Diferente do RoCE (RDMA), o NVMe/TCP funciona na sua infraestrutura de switches e cabos atual, sem necessidade de configurações complexas de Flow Control (PFC/ECN).
O gargalo oculto na tradução do protocolo
Para entender por que precisamos mudar, precisamos olhar para a fila de comandos. O protocolo SCSI foi desenhado em uma época de processadores single-core e discos rotacionais. Ele opera, fundamentalmente, com uma única fila de comandos que suporta até 256 instruções.
O protocolo NVMe, por outro lado, foi desenhado para a era multi-core. Ele suporta 64.000 filas, com cada fila suportando 64.000 comandos. Quando você usa iSCSI ou Fibre Channel tradicional para acessar um array All-Flash NVMe, você está forçando esse tráfego massivamente paralelo a passar por um funil serializado.
O processador do seu storage controller gasta ciclos preciosos traduzindo comandos SCSI para NVMe e vice-versa. Esse overhead de tradução é o que chamamos de "imposto de protocolo". Em redes de alta velocidade (25GbE, 100GbE), o iSCSI simplesmente não consegue saturar o link antes de estourar a CPU do host ou do storage devido a essa ineficiência.
 Figura: Comparativo visual de filas: O gargalo da fila única do SCSI versus o paralelismo massivo das filas NVMe.
Figura: Comparativo visual de filas: O gargalo da fila única do SCSI versus o paralelismo massivo das filas NVMe.
A armadilha da complexidade do RDMA (RoCEv2)
Quando a indústria percebeu que o SCSI era o gargalo, a primeira resposta foi o NVMe over Fabrics (NVMe-oF) usando RDMA (Remote Direct Memory Access). As variantes mais comuns são RoCEv2 (RDMA over Converged Ethernet) e iWARP.
O RDMA é fantástico no papel. Ele permite que os dados passem da memória do storage direto para a memória do servidor, ignorando a CPU. A latência é mínima. No entanto, o RoCEv2 exige uma rede Lossless (sem perda de pacotes).
⚠️ Perigo: Implementar RoCEv2 exige configurar Priority Flow Control (PFC) e Explicit Congestion Notification (ECN) em todos os switches da malha. Uma configuração errada pode causar o temido "Head-of-Line Blocking", paralisando toda a rede de storage.
Para a maioria das empresas, a complexidade de manter uma rede lossless não compensa o ganho marginal de performance. É aqui que o NVMe/TCP brilha.
A democratização da baixa latência via NVMe over TCP
O NVMe/TCP, ratificado pela NVM Express org em 2018, pega a semântica do NVMe e a encapsula diretamente em datagramas TCP.
A genialidade dessa abordagem é o pragmatismo. O TCP é o protocolo mais robusto e bem compreendido do mundo. Ele lida nativamente com congestionamento, retransmissão e roteamento. Ao usar o TCP como transporte:
Independência de Hardware: Você não precisa de placas de rede (NICs) com suporte a RDMA ou switches com DCB (Data Center Bridging). Se o switch passa tráfego IP, ele suporta NVMe/TCP.
Custo: Você pode usar a infraestrutura brownfield (existente). Basta atualizar o software do storage e do hypervisor (vSphere 7.0 U3 e superiores já suportam nativamente).
Escalabilidade: O TCP roteia através de sub-redes e WANs muito melhor que o RoCE, facilitando replicação remota e arquiteturas de stretched cluster.
 Figura: Comparação da pilha de protocolos: A eliminação da camada de tradução SCSI no NVMe/TCP reduz drasticamente o overhead de CPU.
Figura: Comparação da pilha de protocolos: A eliminação da camada de tradução SCSI no NVMe/TCP reduz drasticamente o overhead de CPU.
Comparativo técnico: Protocolos de armazenamento em rede
Para arquitetos de solução, a escolha do protocolo depende do equilíbrio entre custo, complexidade e performance. Veja como o NVMe/TCP se posiciona:
| Característica | iSCSI (Tradicional) | Fibre Channel (FC) | NVMe over RoCEv2 | NVMe over TCP |
|---|---|---|---|---|
| Protocolo Base | SCSI | SCSI / NVMe | NVMe (RDMA) | NVMe |
| Infraestrutura | Ethernet Padrão | Rede FC Dedicada (HBA/Switch) | Ethernet com DCB/PFC | Ethernet Padrão |
| Custo por Porta | Baixo | Alto | Médio/Alto | Baixo |
| Complexidade | Baixa | Média | Alta (Lossless req.) | Baixa |
| Latência Típica | Alta (>100µs add) | Baixa | Ultra-Baixa (<10µs add) | Muito Baixa (<20µs add) |
| Uso de CPU | Alto | Baixo (Offload HBA) | Mínimo (Zero Copy) | Médio (Otimizado) |
Métricas reais e o papel do ANA
Uma preocupação comum é o uso de CPU. "Se o NVMe/TCP não faz offload total como o RDMA, ele não vai matar meu servidor?"
A resposta reside na eficiência do código. Embora o NVMe/TCP use ciclos de CPU para processar o encapsulamento, ele elimina a pesada máquina de estados do SCSI. Testes de campo em ambientes 100GbE mostram que o NVMe/TCP pode entregar 2x a 3x mais IOPS que o iSCSI com o mesmo consumo de CPU, simplesmente porque o processamento é mais linear e eficiente.
Além disso, placas de rede modernas (SmartNICs ou DPUs) já começam a oferecer offload parcial de TCP e CRC, mitigando ainda mais esse impacto.
Multipath moderno: Adeus ALUA, olá ANA
No mundo SCSI, lidamos com ALUA (Asymmetric Logical Unit Access) para gerenciar caminhos ativos e passivos. No NVMe-oF, o padrão é o ANA (Asymmetric Namespace Access).
O ANA é muito mais dinâmico. Ele permite que o array de storage informe ao host (iniciador) o estado de cada caminho em tempo real e com granularidade de Namespace (o equivalente a LUN no mundo NVMe). Isso resulta em failovers quase instantâneos e um balanceamento de carga muito mais efetivo em arquiteturas active-active.
💡 Dica Pro: Ao configurar NVMe/TCP no VMware vSphere ou Linux, certifique-se de aumentar o MTU para 9000 (Jumbo Frames) de ponta a ponta. Como o NVMe transfere blocos de 4KB ou maiores, a fragmentação em pacotes de 1500 bytes adiciona um overhead de processamento de pacotes desnecessário.
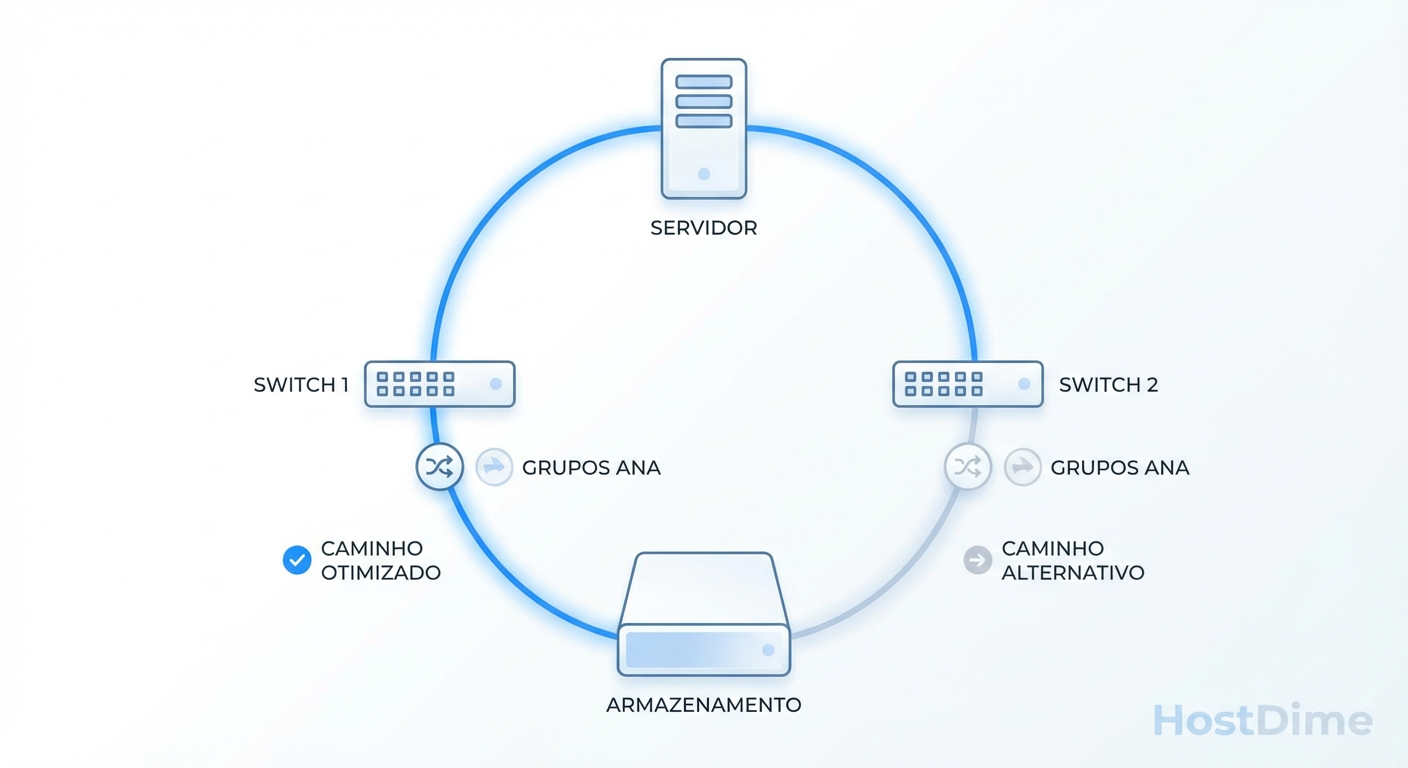 Figura: Topologia de Multipath com ANA: O host identifica dinamicamente os caminhos otimizados para cada Namespace NVMe.
Figura: Topologia de Multipath com ANA: O host identifica dinamicamente os caminhos otimizados para cada Namespace NVMe.
O futuro do SAN é Ethernet
Estamos observando um ponto de inflexão. O Fibre Channel de 32Gb e 64Gb ainda tem seu lugar em ambientes de missão crítica legados e mainframes, mas o custo por gigabit do Ethernet é imbatível. Com switches de 100GbE e 400GbE se tornando comuns no spine do datacenter, a convergência é inevitável.
O NVMe/TCP remove a última barreira que mantinha o iSCSI vivo: a facilidade de uso. Ele oferece a simplicidade do iSCSI com a performance próxima do Fibre Channel ou RDMA. Para 95% das cargas de trabalho corporativas, incluindo bancos de dados SQL de alta performance e VDI, o NVMe/TCP é mais do que suficiente; é a escolha lógica.
Se você está planejando sua próxima renovação de infraestrutura de armazenamento, não solicite apenas "suporte a NVMe" nos discos. Exija suporte a NVMe-oF/TCP no fabric. Continuar investindo em iSCSI para novos deployments All-Flash é comprar um carro esportivo e colocar pneus de bicicleta.
Referências & Leitura Complementar
NVM Express Base Specification 2.0: Detalhes técnicos sobre o transporte TCP e a arquitetura de filas.
SNIA (Storage Networking Industry Association): "NVMe over TCP: Performance and Deployment Guide".
RFC 793 / RFC 9293: Especificações do Transmission Control Protocol (TCP) que fundamentam o transporte.
VMware vSphere 8 Storage Guide: Documentação oficial sobre a implementação e requisitos do NVMe/TCP em ambientes virtualizados.
Perguntas Frequentes (FAQ)
O NVMe over TCP exige switches especiais?
Não. Diferente do RoCEv2, que exige suporte a DCB (Data Center Bridging) e PFC para garantir uma rede sem perdas, o NVMe/TCP roda em qualquer switch Ethernet padrão. Isso facilita enormemente a adoção em infraestruturas existentes (Brownfield), pois não requer a substituição do hardware de rede.Qual a diferença de performance entre iSCSI e NVMe/TCP?
Em média, o NVMe/TCP oferece até 35% mais IOPS e reduz a latência em cerca de 25% comparado ao iSCSI no mesmo hardware. O ganho vem principalmente da eliminação da camada de tradução SCSI e do paralelismo massivo de filas (64k filas vs 1 fila do SCSI), permitindo que o protocolo acompanhe a velocidade dos SSDs modernos.O NVMe/TCP consome mais CPU que o iSCSI?
Geralmente, o NVMe/TCP é mais eficiente por IOPS processado. Embora utilize a CPU do host para o processamento TCP (ao contrário do RoCE que faz offload total), ele elimina o overhead pesado da tradução SCSI-para-NVMe. O resultado é um menor uso total de CPU para a mesma carga de trabalho, ou muito mais performance com o mesmo uso de CPU.
Alexandre Tavares
Operador de Storage em Rede (SAN/NAS)
"Respiro Fibre Channel e NVMe-oF. Meu foco é eliminar gargalos de I/O e otimizar rotas multipath para garantir que seus dados trafeguem com a menor latência possível."