NVMe/TCP: Alta performance de storage sem decretar falência

Descubra por que o NVMe-oF sobre TCP é a arquitetura de armazenamento híbrido que mata o iSCSI e evita a complexidade cara do RDMA/RoCE.
Se você já olhou para a fatura de um array All-Flash moderno e sentiu uma pontada no peito, você não está sozinho. A indústria de storage adora vender a ideia de que "velocidade custa caro". E, por muito tempo, eles estavam certos.
Nós passamos a última década migrando de HDDs giratórios para SSDs SATA, e depois para NVMe. O problema? A nossa rede não acompanhou. Continuamos enfiando comandos NVMe ultrarrápidos dentro de protocolos desenhados na era em que "disco rápido" significava 15.000 RPM e barulho de turbina de avião.
O iSCSI foi um herói. Ele democratizou a SAN (Storage Area Network). Mas em um mundo de redes 100GbE e latências de microssegundos, o iSCSI é o equivalente a rebocar uma Ferrari com uma carroça. A solução "premium" que os vendedores empurram é o NVMe over Fabrics (NVMe-oF) usando RDMA (RoCE). É rápido? Sim. É complexo e caro a ponto de fazer você questionar suas escolhas de carreira? Absolutamente.
É aqui que entra o NVMe/TCP. É a tecnologia que promete performance quase nativa de NVMe, usando a infraestrutura Ethernet que você já tem, sem exigir que você venda um rim para pagar switches proprietários.
Resumo em 30 segundos
- O problema: O protocolo iSCSI adiciona uma latência massiva ao traduzir comandos NVMe para SCSI, matando a performance dos SSDs modernos.
- A armadilha: O RDMA (RoCE) resolve a latência, mas exige switches caros, configurações de rede "lossless" complexas e NICs específicas.
- A solução: O NVMe/TCP entrega performance similar ao RDMA, mas roda em switches Ethernet padrão e usa o protocolo TCP que todo engenheiro já conhece, democratizando o storage de alta performance.
Quando o iSCSI se torna o gargalo em redes de 100GbE
Vamos ser honestos: o iSCSI é o "tiozão do churrasco" do data center. Ele é confiável, está lá há anos e todo mundo conhece. Mas quando você coloca um array NVMe capaz de 1 milhão de IOPS atrás de uma conexão iSCSI, você está cometendo um crime contra o silício.
O problema fundamental é a tradução de protocolo. O NVMe (Non-Volatile Memory Express) foi desenhado para paralelismo massivo, com 64.000 filas de comando. O SCSI (Small Computer System Interface), base do iSCSI, foi desenhado nos anos 80 para dispositivos seriais que processavam uma coisa de cada vez.
Quando seu servidor envia um dado via iSCSI:
O comando NVMe é encapsulado em SCSI.
O SCSI é encapsulado em TCP/IP.
O pacote viaja pela rede.
O storage desembrulha o TCP, desembrulha o SCSI, traduz para NVMe e grava no disco.
Essa "serialização" consome ciclos preciosos de CPU. Em redes de 10GbE, isso era aceitável. Em 100GbE, a CPU do seu servidor gasta mais tempo empacotando dados do que rodando sua aplicação. É o que chamamos de overhead de protocolo.
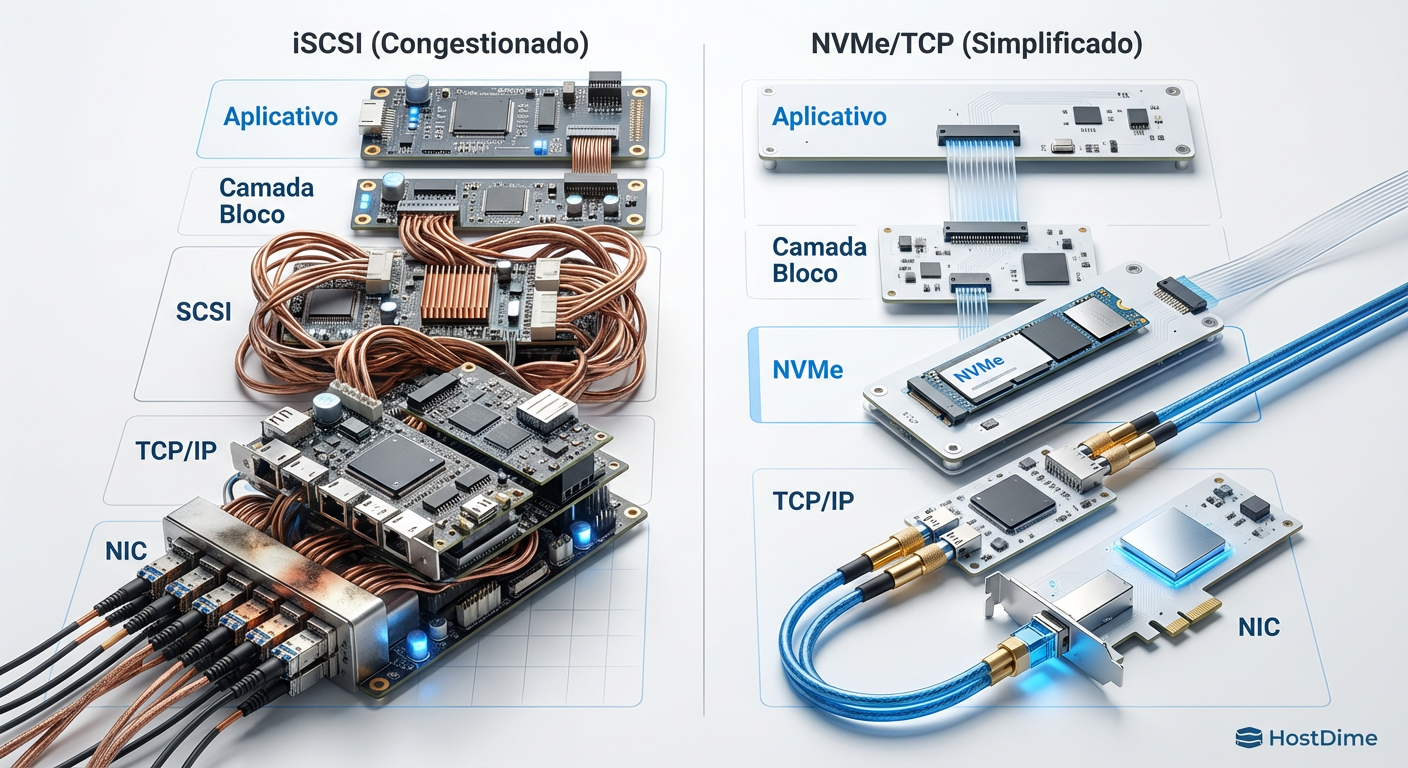 Figura: Comparativo visual das pilhas de protocolo: a complexidade da tradução SCSI vs a eficiência do NVMe nativo.
Figura: Comparativo visual das pilhas de protocolo: a complexidade da tradução SCSI vs a eficiência do NVMe nativo.
A armadilha financeira do RoCEv2 e switches dedicados
Para resolver o problema do iSCSI, a indústria correu para o RDMA (Remote Direct Memory Access). A ideia é linda: permitir que um computador acesse a memória de outro sem envolver a CPU. Latência baixíssima, throughput altíssimo.
No mundo Ethernet, isso se materializou como RoCEv2 (RDMA over Converged Ethernet). Se você perguntar a um vendedor de hardware, ele dirá que é o futuro. O que ele não te conta (e que vai aparecer no seu orçamento de Capex) é o custo oculto da complexidade.
O RoCEv2 exige uma rede Lossless Ethernet (Ethernet sem perdas). O protocolo RDMA é alérgico a perda de pacotes. Se um pacote cai, a performance despenca. Para evitar isso, você precisa configurar PFC (Priority Flow Control) e ECN (Explicit Congestion Notification) em todos os seus switches.
⚠️ Perigo: Configurar PFC em uma rede mista é um convite para o desastre. Se mal configurado, você pode criar um "Head-of-Line Blocking" que trava não só o storage, mas todo o tráfego da rede. Além disso, você fica preso a switches de classe Data Center (leia-se: caros) e NICs específicas que suportam offload de RDMA.
Basicamente, você está construindo uma rede Fibre Channel glorificada usando cabos Ethernet. É caro, difícil de manter e, se quebrar às 3 da manhã, boa sorte para debugar o fluxo de prioridade nos buffers do switch.
Implementando NVMe/TCP com hardware commodity
Aqui brilha o NVMe/TCP. Padronizado em 2018 pela NVM Express organization, ele pega os comandos NVMe e os encapsula diretamente em quadros TCP padrão.
Por que isso é genial? Porque a internet inteira roda sobre TCP.
Controle de Fluxo: O TCP já lida nativamente com congestionamento e retransmissão. Você não precisa de uma rede "lossless". Pode ter perda de pacote? Pode. O TCP resolve.
Hardware Padrão: Funciona no switch Top-of-Rack que você comprou ano passado. Funciona na placa de rede Intel ou Broadcom genérica que veio no seu servidor Dell/HPE.
Custo: Zero custo adicional de licenciamento de hardware específico.
A crítica comum é: "Mas o TCP usa muita CPU!". Isso era verdade em 2010. Hoje, com processadores EPYC e Xeon modernos, e com as otimizações no Kernel Linux (Zero Copy), o overhead do NVMe/TCP é marginalmente superior ao do RDMA, mas a complexidade operacional é ordens de magnitude menor.
Como funciona no mundo real (Linux Kernel 5.x+)
Se você roda uma distribuição Linux moderna (Ubuntu 22.04+, RHEL 9+), você já tem tudo o que precisa. O módulo nvme-tcp já vem no kernel.
Para conectar um host a um target NVMe/TCP, o processo é ridiculamente simples, muito similar ao iSCSI, mas sem a dor de cabeça do iscsiadm:
# Carregar o módulo (se ainda não estiver carregado)
modprobe nvme-tcp
# Descobrir targets no controlador (Discovery)
nvme discover -t tcp -a 192.168.10.50 -s 8009
# Conectar ao target
nvme connect -t tcp -n nqn.2014-08.org.nvmexpress:uuid:f81d4fae-7dec-11d0-a765-00a0c91e6bf6 -a 192.168.10.50 -s 8009
Pronto. Um novo dispositivo /dev/nvme0n1 aparece no seu sistema. Sem zoneamento de Fibre Channel, sem configuração de PFC no switch. Apenas sockets TCP voando baixo.
 Figura: Topologia Leaf-Spine padrão suportando tráfego NVMe/TCP sem necessidade de hardware proprietário ou redes segregadas.
Figura: Topologia Leaf-Spine padrão suportando tráfego NVMe/TCP sem necessidade de hardware proprietário ou redes segregadas.
Comparativo de latência de cauda: Onde a batalha é vencida
Muitos benchmarks focam em IOPS máximos, mas IOPS é métrica de vaidade. O que importa para seu banco de dados é a latência, especificamente a latência de cauda (p99 ou p99.9) — quanto tempo as requisições mais lentas demoram.
Em testes recentes comparando iSCSI vs NVMe/TCP em hardware idêntico (NICs 25GbE):
iSCSI: Latência média de 250µs, mas p99 saltando para 2ms+ sob carga devido ao bloqueio de filas e overhead de tradução.
NVMe/TCP: Latência média de 180µs, com p99 estável em ~300µs.
A consistência do NVMe/TCP é o que impressiona. Como ele utiliza o paralelismo nativo do NVMe (múltiplas filas de hardware mapeadas para múltiplos núcleos de CPU), ele não engasga quando você bombardeia o storage com requisições simultâneas.
💡 Dica Pro: Para extrair o máximo do NVMe/TCP, habilite o Jumbo Frames (MTU 9000) em toda a cadeia (Servidor -> Switch -> Storage). Isso reduz a quantidade de pacotes que a CPU precisa processar para o mesmo volume de dados, melhorando a eficiência do throughput.
Tabela Comparativa: O Veredito Técnico
| Característica | iSCSI | NVMe over RoCEv2 (RDMA) | NVMe/TCP |
|---|---|---|---|
| Performance (Latência) | Alta (Gargalo de tradução) | Baixíssima (Bypass de CPU) | Baixa (Próxima ao RDMA) |
| Custo de Hardware | Baixo (Ethernet Padrão) | Alto (NICs e Switches Específicos) | Baixo (Ethernet Padrão) |
| Complexidade de Rede | Baixa | Insana (PFC, ECN, Lossless) | Baixa (TCP/IP Padrão) |
| Uso de CPU no Host | Alto | Mínimo | Médio (Otimizável) |
| Roteamento | Simples (L3) | Complexo (Exige suporte a RoCEv2 L3) | Simples (L3 Nativo) |
| Caso de Uso Ideal | Legado, HDDs, Labs | HPC, AI/ML Clusters, Supercomputadores | Enterprise Generalista, Cloud, Virtualização |
Veredito Técnico
O NVMe/TCP não é apenas uma "alternativa barata" ao RDMA. É a evolução racional do storage em rede para 99% das empresas. A menos que você esteja treinando o próximo LLM da OpenAI ou simulando dobramento de proteínas em tempo real, o ganho marginal de latência do RoCEv2 não justifica o custo financeiro e a dívida técnica operacional.
Estamos vendo uma mudança tectônica. O iSCSI serviu bem, mas é hora de aposentá-lo para cargas de trabalho flash. O NVMe/TCP permite que você escale sua infraestrutura de storage horizontalmente, usando switches commodity, mantendo a latência baixa e, o mais importante, mantendo seu orçamento de TI sob controle.
No final do dia, a melhor tecnologia é aquela que funciona de forma invisível e não te acorda de madrugada porque um buffer de switch estourou. O NVMe/TCP é essa tecnologia.
O NVMe/TCP é mais lento que o RDMA (RoCE)?
Tecnicamente, sim. O RDMA oferece latências na casa dos 5-10µs a menos por pular a CPU. Porém, para 99% das cargas de trabalho (bancos de dados, virtualização), a complexidade de configurar uma rede 'Lossless Ethernet' para RoCE não compensa o ganho marginal sobre o NVMe/TCP, que já entrega performance quase nativa.Preciso de switches especiais para usar NVMe/TCP?
Não. Essa é a grande vantagem. Ao contrário do Fibre Channel ou RoCEv2 que exigem configurações de PFC (Priority Flow Control) e hardware específico, o NVMe/TCP roda na sua infraestrutura Ethernet padrão existente, seja ela 10GbE, 25GbE ou 100GbE.O VMware vSphere suporta NVMe sobre TCP?
Sim, nativamente a partir do vSphere 7.0 Update 3. Isso permite montar datastores de altíssima performance usando redes padrão, aposentando o iSCSI para workloads críticos.Referências & Leitura Complementar
NVM Express Base Specification 2.0: Detalhes oficiais sobre o transporte NVMe over Fabrics.
SNIA (Storage Networking Industry Association): Whitepapers sobre a eficiência do protocolo TCP para storage.
Linux Kernel Documentation (drivers/nvme/host/tcp.c): Documentação técnica da implementação do driver initiator no Linux.
RFC 793 (Transmission Control Protocol): Porque nunca é demais lembrar como a base da internet funciona.

Rafael Barros
Arquiteto de Cloud Storage
"Desenho arquiteturas de object storage escaláveis e guiadas por API. Meu foco é performance máxima sem deixar o orçamento sangrar com taxas de egress ocultas."