O colapso do POSIX em clusters de IA e a arquitetura DAOS para bypass de kernel em NVMe

Entenda por que o padrão POSIX limita o desempenho de GPUs em clusters de IA e como a arquitetura DAOS utiliza bypass de kernel em NVMe para maximizar o throughput e reduzir o TCO.
A construção de clusters para treinamento de modelos massivos de inteligência artificial trouxe à tona uma falha fundamental na forma como pensamos a infraestrutura de dados. Compramos as GPUs mais rápidas do mercado, interligamos tudo com redes de altíssima velocidade e, no final do dia, observamos os aceleradores ociosos. O motivo raramente é a falta de capacidade bruta dos discos, mas sim a arquitetura de software que gerencia esses discos.
O padrão POSIX, que serviu como fundação para sistemas de arquivos por décadas, está colapsando sob o peso do I/O paralelo exigido pela IA moderna. A resposta padrão para problemas de performance em storage costumava ser a adição de mais hardware. Hoje, a resposta correta depende de repensar o caminho dos dados desde a aplicação até a mídia física.
Resumo em 30 segundos
- O gargalo mudou: GPUs modernas passam muito tempo ociosas esperando dados devido à sobrecarga do kernel Linux e bloqueios do padrão POSIX.
- A ilusão do hardware: Adicionar mais SSDs NVMe não resolve o problema se a arquitetura de software continuar serializando as requisições de I/O.
- A solução DAOS: O bypass de kernel transfere o processamento de I/O para o user space, permitindo acesso direto ao hardware e reduzindo o tempo de checkpointing drasticamente.
A fome das GPUs e a ociosidade disfarçada
O treinamento de um Large Language Model (LLM) não é apenas um problema de processamento matemático. É, fundamentalmente, um problema de movimentação de dados em escala extrema. Milhares de threads de GPU precisam ler tensores, atualizar pesos e gravar checkpoints simultaneamente.
Quando analisamos a telemetria de um cluster de IA tradicional, vemos um padrão preocupante. As GPUs apresentam picos de 100% de utilização seguidos por vales profundos de inatividade. Durante esses vales, os aceleradores estão literalmente esperando que o sistema de armazenamento entregue o próximo lote de dados.
O instinto de muitos engenheiros é culpar a latência da rede ou a velocidade dos SSDs. No entanto, ao monitorar os servidores de storage, notamos que as unidades NVMe (Non-Volatile Memory Express) raramente atingem seu limite de IOPS. O verdadeiro gargalo está na CPU do servidor de armazenamento, que atinge 100% de uso apenas tentando gerenciar as interrupções do sistema operacional.
A serialização do POSIX e o custo do context switch
O padrão POSIX (Portable Operating System Interface) foi desenhado em uma época onde discos magnéticos eram lentos e a consistência rigorosa de metadados era inegociável. Ele exige que cada operação de leitura ou escrita passe por uma série de verificações de permissão, atualizações de timestamp e bloqueios (locks) de arquivos.
Quando uma aplicação de IA solicita dados, ocorre uma transição de contexto (context switch) do espaço do usuário (user space) para o espaço do núcleo (kernel space). O kernel do Linux precisa processar a requisição através do Virtual File System (VFS), descer para a camada de blocos e, finalmente, acionar o driver NVMe.
⚠️ Perigo: Tentar escalar sistemas de arquivos paralelos tradicionais apenas adicionando mais discos NVMe é um erro comum de design. O gargalo não está na mídia física, mas na CPU do storage server que satura gerenciando interrupções do kernel e bloqueios de metadados.
Em um cenário com milhões de pequenos arquivos ou acessos paralelos massivos ao mesmo dataset, os bloqueios do POSIX forçam a serialização das requisições. O sistema operacional enfileira as chamadas, destruindo o paralelismo inerente que a arquitetura NVMe e o barramento PCIe oferecem.
Arquitetando DAOS para bypass de kernel
Para resolver esse problema arquitetural, a indústria de High Performance Computing (HPC) e IA começou a adotar o DAOS (Distributed Asynchronous Object Storage). O DAOS não é um sistema de arquivos tradicional, mas sim um contêiner de armazenamento de objetos definido por software que ignora completamente o kernel do sistema operacional.
A mágica do DAOS reside no conceito de kernel bypass. Utilizando bibliotecas como o SPDK (Storage Performance Development Kit) desenvolvido pela Intel, a aplicação de IA se comunica diretamente com as controladoras NVMe a partir do user space.
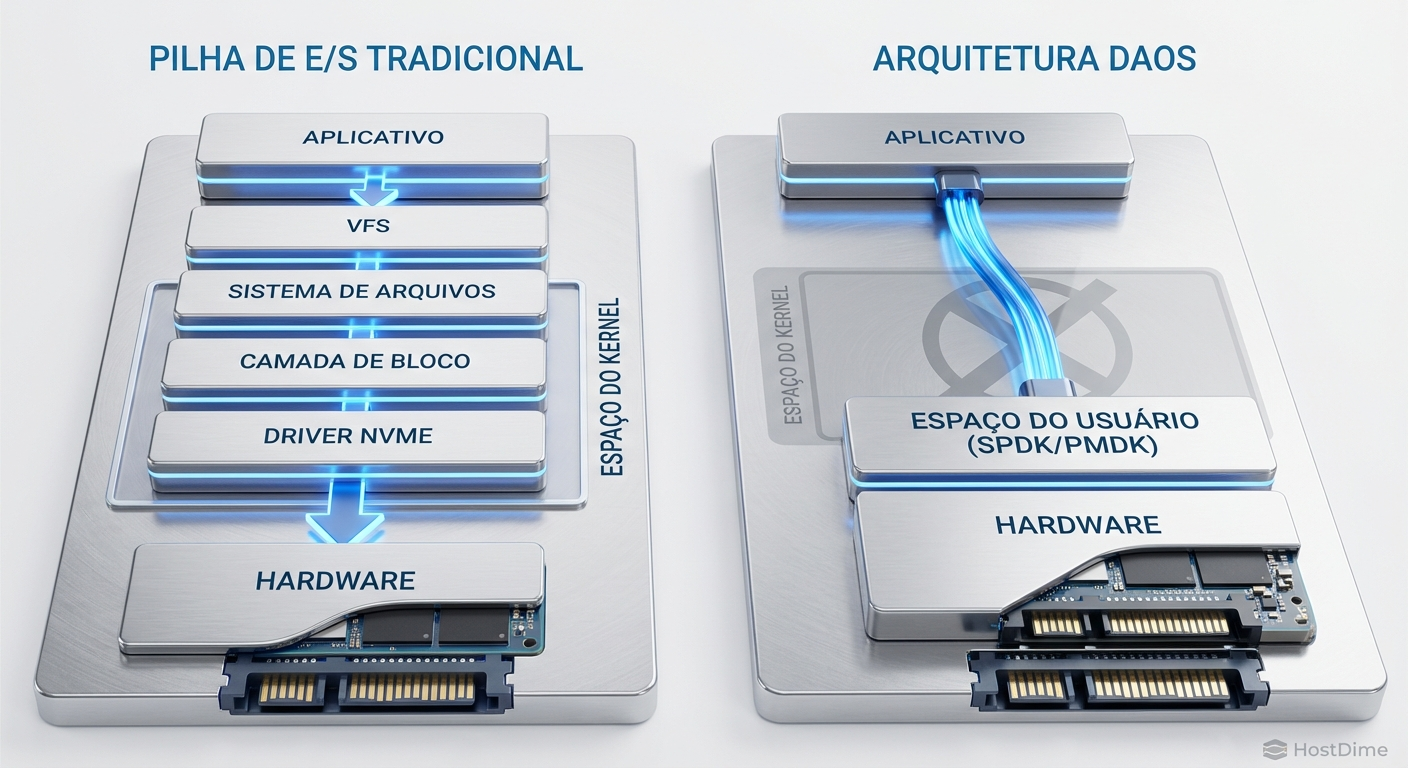 Figura: Comparativo arquitetural entre a pilha de I/O tradicional e o bypass de kernel utilizado pelo DAOS
Figura: Comparativo arquitetural entre a pilha de I/O tradicional e o bypass de kernel utilizado pelo DAOS
Ao eliminar o VFS e a camada de blocos do Linux, o DAOS remove as transições de contexto e as interrupções de hardware. O processamento de I/O passa a ser feito por polling (verificação contínua) em vez de interrupções, o que consome ciclos de CPU dedicados, mas reduz a latência de acesso ao NVMe para a casa dos microssegundos.
Tabela comparativa: POSIX tradicional vs Arquitetura DAOS
Para entender os trade-offs dessa mudança de paradigma, precisamos comparar as duas abordagens sob a ótica de infraestrutura enterprise.
| Característica | Sistema de Arquivos POSIX (ex: NFS, Ext4) | Arquitetura DAOS (Kernel Bypass) |
|---|---|---|
| Caminho de Dados | User Space -> Kernel Space -> Hardware | User Space -> Hardware Direto |
| Latência Típica | Alta (Milisegundos devido a context switch) | Ultra-baixa (Microssegundos) |
| Gerenciamento de I/O | Baseado em Interrupções (Interrupts) | Baseado em Polling (SPDK) |
| Consistência | Forte (Bloqueios rigorosos de metadados) | Eventual/Customizada para a aplicação |
| Complexidade de Rede | Padrão (TCP/IP tradicional funciona bem) | Alta (Exige RDMA, RoCE v2 ou InfiniBand) |
| Custo de Implementação | Baixo a Médio (Hardware comoditizado) | Alto (Requer rede dedicada e NVMe de alta performance) |
Reduzindo o tempo de checkpointing em clusters de alta densidade
O impacto financeiro do bypass de kernel torna-se evidente na operação de checkpointing. Durante o treinamento de modelos com bilhões de parâmetros, o estado atual da rede neural precisa ser salvo periodicamente no storage para evitar perda de progresso em caso de falha de hardware.
Esses checkpoints geram terabytes de dados que precisam ser gravados simultaneamente por todos os nós do cluster. Em sistemas baseados em POSIX, essa tempestade de I/O (I/O storm) pode levar horas para ser concluída. Durante esse período, as GPUs ficam paralisadas aguardando a confirmação de gravação.
💡 Dica Pro: Em modelagem financeira de TCO para clusters de IA, calcule o custo da hora ociosa da GPU durante o checkpointing. O investimento em uma rede RDMA e storage DAOS frequentemente se paga apenas com a recuperação desse tempo de processamento perdido.
Com a arquitetura DAOS, a gravação assíncrona e o acesso direto ao hardware NVMe permitem que o cluster absorva essa carga massiva em questão de minutos. A eliminação do gargalo de metadados significa que a velocidade de gravação é limitada apenas pela largura de banda física do barramento PCIe e da rede.
Trade-offs e a realidade do isolamento de dados
Como arquitetos de soluções, sabemos que não existe bala de prata. A adoção do DAOS e do bypass de kernel traz desafios significativos de segurança e infraestrutura.
Ao remover o kernel do caminho de dados, perdemos as proteções tradicionais de isolamento multi-tenant que o sistema operacional oferece. A responsabilidade de garantir que um processo não acesse os dados de outro passa para a aplicação e para tecnologias de hardware como o IOMMU (Input-Output Memory Management Unit).
 Figura: Topologia de rede demonstrando o fluxo de dados via RDMA direto para as GPUs, essencial para o funcionamento do DAOS
Figura: Topologia de rede demonstrando o fluxo de dados via RDMA direto para as GPUs, essencial para o funcionamento do DAOS
Além disso, o DAOS depende fortemente de redes com suporte a RDMA (Remote Direct Memory Access). Isso significa que sua infraestrutura precisará de switches InfiniBand ou Ethernet configurados com RoCE v2 (RDMA over Converged Ethernet). O design de rede torna-se tão crítico quanto o design do storage, exigindo controle rigoroso de congestionamento e buffers.
O futuro do armazenamento para inteligência artificial
O padrão POSIX não vai desaparecer. Ele continuará sendo a espinha dorsal para cargas de trabalho de propósito geral, servidores web e bancos de dados tradicionais. No entanto, para a fronteira da inteligência artificial e computação de alto desempenho, a abstração do sistema operacional tornou-se um luxo caro demais.
A transição para arquiteturas de user space como o DAOS é apenas o primeiro passo. O próximo horizonte envolve a adoção do CXL (Compute Express Link), um novo padrão de interconexão que permitirá o compartilhamento de memória persistente e NVMe diretamente entre nós, borrando ainda mais as linhas entre memória RAM e armazenamento de longo prazo.
Recomendo fortemente que equipes de engenharia de infraestrutura comecem a testar pilhas de I/O baseadas em SPDK em ambientes de laboratório. A capacidade de alimentar GPUs de forma eficiente será o principal diferencial competitivo na construção dos próximos datacenters focados em IA.
Referências e leitura complementar
Intel DAOS Documentation: Arquitetura oficial e guias de implementação do Distributed Asynchronous Object Storage.
SNIA (Storage Networking Industry Association): Especificações sobre Computational Storage e arquiteturas NVMe over Fabrics (NVMe-oF).
SPDK.io: Documentação técnica do Storage Performance Development Kit e guias de implementação de user-space I/O.
NVM Express Base Specification: Detalhes técnicos sobre o protocolo NVMe e gerenciamento de filas de submissão e conclusão.
O que é DAOS e como ele difere de sistemas de arquivos tradicionais?
O DAOS (Distributed Asynchronous Object Storage) é um sistema de armazenamento em cluster de código aberto que ignora o kernel do sistema operacional. Ele se comunica diretamente com o hardware NVMe e memórias persistentes via user space. Essa abordagem elimina a latência das chamadas de sistema tradicionais, oferecendo um caminho de dados muito mais curto e rápido em comparação com sistemas de arquivos legados.Por que o padrão POSIX se tornou um problema para cargas de trabalho de IA?
O POSIX exige bloqueios rigorosos de metadados e consistência forte para cada operação de arquivo. Quando milhares de threads de GPU tentam acessar ou gravar dados simultaneamente durante o treinamento de IA, essas regras criam gargalos de serialização severos. O resultado é a saturação da CPU do servidor de storage gerenciando interrupções, antes mesmo de atingir o limite físico de banda do barramento PCIe ou dos discos NVMe.O bypass de kernel compromete a segurança e o isolamento dos dados?
Depende da arquitetura da rede e do cluster. Ao remover o kernel do caminho de dados, a responsabilidade de isolamento passa para a aplicação e para o hardware, utilizando recursos como o IOMMU. Em ambientes de HPC e IA, essa troca é aceitável, pois esses clusters operam em redes isoladas e dedicadas, como InfiniBand ou RoCE. Nesses cenários específicos, prioriza-se a performance extrema sobre o isolamento multi-tenant tradicional encontrado em nuvens públicas genéricas.
Otávio Henriques
Arquiteto de Soluções Enterprise
"Com duas décadas desenhando infraestruturas críticas, olho além do hype. Foco em TCO, resiliência e trade-offs, pois na arquitetura corporativa a resposta correta quase sempre é 'depende'."