O custo invisível da capacidade ociosa: otimizando o storage com NVMe-oF desagregado

Descubra como a arquitetura NVMe-oF elimina o desperdício de armazenamento em DAS, reduz o TCO e transforma a capacidade ociosa em eficiência matemática para o seu data center.
A matemática do planejamento de capacidade é implacável quando lidamos com infraestruturas rígidas. Em data centers tradicionais, a alocação de recursos frequentemente esbarra em um limite físico que gera um dreno financeiro silencioso. Comprar discos de alta performance e deixá-los ociosos porque o processador do servidor atingiu seu limite é um erro de modelagem que custa milhões anualmente.
Resumo em 30 segundos
- A arquitetura tradicional de armazenamento direto (DAS) cria "ilhas" de recursos, resultando em capacidade de disco paga, mas inutilizável.
- O protocolo NVMe-oF quebra essa barreira física, permitindo que discos flash sejam acessados via rede com latência de barramento local.
- Desagregar o storage do processamento transforma o gasto de capital (CAPEX) em um modelo elástico, otimizando o TCO e evitando o superprovisionamento.
A matemática do desperdício em arquiteturas de armazenamento direto
O modelo de Direct Attached Storage (DAS) foi o padrão da indústria por décadas. Nele, os discos rígidos ou SSDs são instalados diretamente no chassi do servidor físico. Do ponto de vista da teoria das filas, essa arquitetura cria um sistema fechado e inflexível.
Quando modelamos o crescimento de uma aplicação em um ambiente DAS, invariavelmente encontramos o problema da capacidade ociosa (stranded capacity). Se um banco de dados consome 100% da CPU de um nó, mas apenas 20% do espaço em disco NVMe (Non-Volatile Memory Express), os 80% restantes ficam isolados.
Nenhum outro servidor na rede pode utilizar esse espaço de armazenamento de altíssima velocidade. O capital foi imobilizado, a energia está sendo gasta para manter os discos ligados, mas o retorno sobre o investimento (ROI) é nulo para aquela fração do hardware.
 Figura: Representação visual da capacidade ociosa: CPU no limite enquanto discos NVMe permanecem subutilizados e inacessíveis para a rede.
Figura: Representação visual da capacidade ociosa: CPU no limite enquanto discos NVMe permanecem subutilizados e inacessíveis para a rede.
Para compensar essa assimetria, os administradores recorrem ao superprovisionamento. Eles compram mais servidores inteiros apenas para obter mais poder de processamento, adquirindo discos adicionais que não precisavam. Isso cria um efeito cascata no orçamento de TI.
Desagregação de recursos e a ascensão do NVMe over Fabrics
A solução matemática para o problema das ilhas de recursos é a desagregação. Precisamos separar a curva de crescimento do processamento da curva de crescimento do armazenamento. É aqui que o protocolo NVMe over Fabrics (NVMe-oF) altera fundamentalmente a topologia do data center.
O NVMe-oF foi projetado para estender a eficiência do barramento PCIe (Peripheral Component Interconnect Express) através de uma rede. Ele permite que um servidor acesse um pool centralizado de discos flash com uma latência quase indistinguível de um disco conectado diretamente à sua própria placa-mãe.
⚠️ Perigo: Tentar implementar NVMe-oF em redes legadas sem suporte a controle de fluxo prioritário pode resultar em micro-explosões de tráfego (microbursts), elevando a latência de cauda e destruindo os benefícios do protocolo.
Ao mover os discos para um chassi de armazenamento dedicado (JBOF - Just a Bunch of Flash), criamos um pool de dados elástico. Os servidores de aplicação tornam-se nós de computação puros (stateless). Se um servidor precisa de mais 10 Terabytes de altíssima performance, o volume é mapeado via rede em milissegundos.
Comparativo arquitetural: armazenamento local versus pool de dados
Para quantificar o impacto dessa mudança, precisamos comparar as métricas operacionais entre o modelo tradicional e a infraestrutura desagregada. A tabela abaixo modela as diferenças fundamentais no planejamento de capacidade.
| Métrica de Avaliação | Arquitetura DAS (Local) | Arquitetura NVMe-oF (Desagregada) |
|---|---|---|
| Utilização de Capacidade | Baixa (Média de 30% a 40%) | Alta (Acima de 85% com thin provisioning) |
| Escalabilidade | Acoplada (Exige compra de CPU + Disco) | Independente (Adiciona-se apenas o recurso necessário) |
| Latência de Acesso | Microsegundos (Barramento PCIe local) | Microsegundos (Adição marginal de ~5 a 10µs via rede) |
| Complexidade de Rede | Baixa (Tráfego contido no chassi) | Alta (Exige switches de baixa latência e QoS rigoroso) |
| Custo de Expansão (TCO) | Alto (Degraus acentuados de investimento) | Otimizado (Crescimento linear e previsível) |
Modelando o retorno financeiro ao eliminar o superprovisionamento
No planejamento de capacidade, evitamos o que chamamos de "cliff" de recursos (um penhasco onde o custo salta abruptamente). O modelo DAS força esses saltos. A desagregação com NVMe-oF suaviza a curva de aquisição, permitindo um modelo de crescimento just-in-time.
Ao consolidar o armazenamento, as taxas de utilização globais disparam. Em vez de ter 50 servidores com 2 TB ociosos cada (100 TB desperdiçados), você mantém um pool centralizado que atende à demanda exata de cada nó.
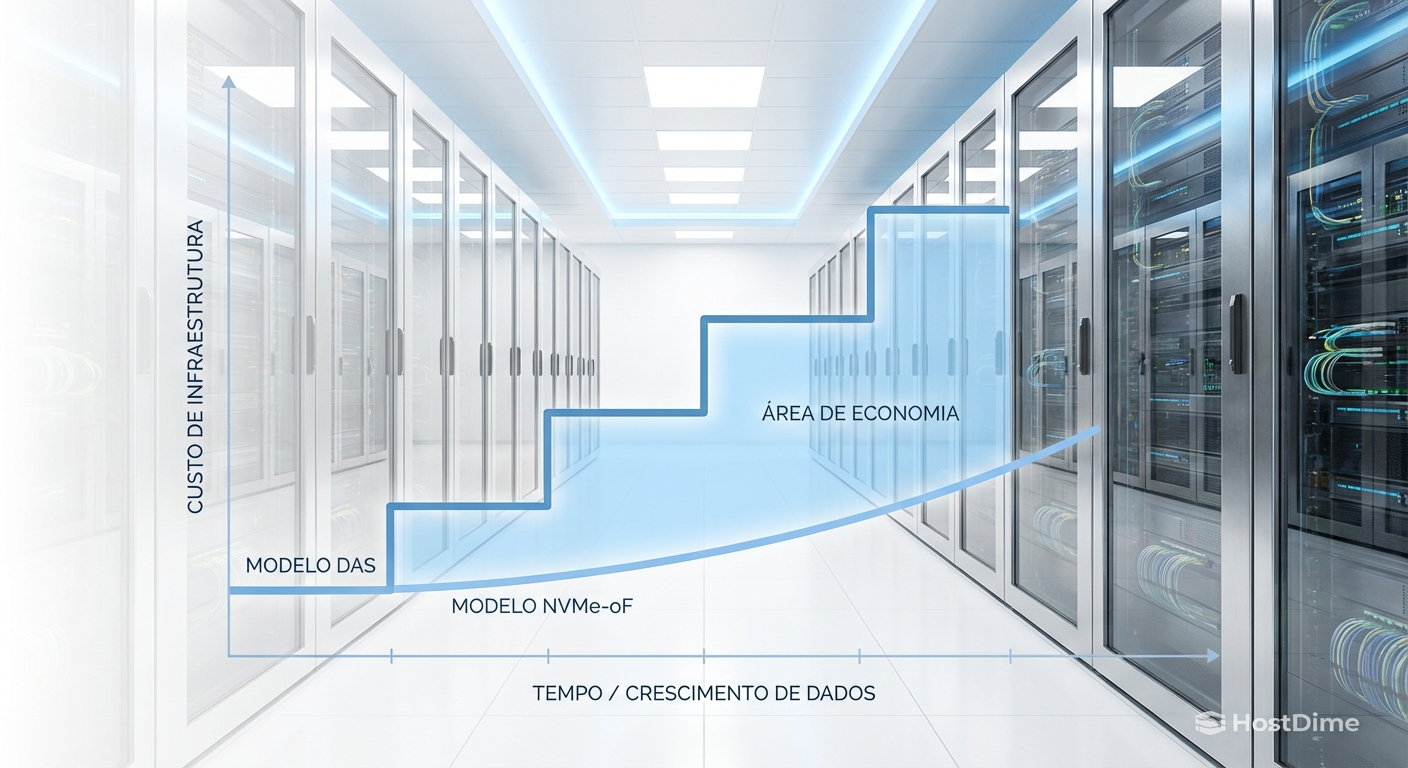 Figura: Gráfico comparativo de TCO: o crescimento em degraus do modelo DAS versus a curva linear e otimizada do armazenamento desagregado.
Figura: Gráfico comparativo de TCO: o crescimento em degraus do modelo DAS versus a curva linear e otimizada do armazenamento desagregado.
Além da economia direta em hardware, há uma redução drástica no consumo de energia e refrigeração. Discos de alta densidade, como os baseados no padrão EDSFF (Enterprise & Data Center Standard Form Factor), especificamente o formato E1.S, permitem empacotar petabytes em poucas unidades de rack (RU).
Isso significa que o custo por IOPS (Operações de Entrada e Saída por Segundo) despenca. A matemática prova que o investimento inicial na infraestrutura de rede de alta performance se paga rapidamente pela eliminação da compra de discos redundantes.
Estratégia de transição para infraestrutura combinável
Migrar para uma arquitetura totalmente desagregada não exige a substituição imediata de todo o data center. A modelagem de transição deve focar em equilibrar o fluxo de caixa com os ganhos de performance.
Existem diferentes sabores de NVMe-oF. O NVMe sobre RDMA (RoCEv2) oferece a menor latência possível, mas exige placas de rede (NICs) específicas e switches configurados para tráfego sem perdas (lossless). É ideal para clusters de inteligência artificial e bancos de dados in-memory.
Por outro lado, o padrão NVMe/TCP democratizou a desagregação. Ele encapsula os comandos NVMe em pacotes TCP/IP padrão. Embora adicione alguns microssegundos de latência em comparação ao RoCE, permite utilizar a infraestrutura Ethernet existente.
💡 Dica Pro: Para cargas de trabalho de virtualização padrão (VMware, KVM), inicie a transição utilizando NVMe/TCP. O ganho de eficiência na alocação de capacidade supera amplamente a latência marginal da rede TCP.
 Figura: Topologia de rede ilustrando a adoção de NVMe/TCP sobre infraestrutura Ethernet padrão, facilitando a transição.
Figura: Topologia de rede ilustrando a adoção de NVMe/TCP sobre infraestrutura Ethernet padrão, facilitando a transição.
Essa flexibilidade permite que as equipes de engenharia criem pools de armazenamento em camadas (tiering). Aplicações críticas rodam em RoCEv2, enquanto o volume massivo de dados corporativos trafega via NVMe/TCP, tudo gerenciado a partir de um único cluster de storage.
Previsão para a próxima década de dados
A desagregação do armazenamento via NVMe-oF é apenas a primeira fase de uma transformação arquitetural inevitável. A modelagem matemática do crescimento de dados gerados por IA indica que o acoplamento de recursos dentro de um único servidor se tornará insustentável financeiramente.
A recomendação para arquitetos de infraestrutura é interromper imediatamente a compra de servidores com armazenamento interno massivo para cargas de trabalho escaláveis. O futuro pertence à infraestrutura combinável (composable infrastructure).
Em breve, tecnologias como o CXL (Compute Express Link) farão com a memória RAM o que o NVMe-oF fez com os discos flash. Preparar sua rede de armazenamento hoje, adotando pools desagregados, é o único caminho seguro para evitar a falência técnica e financeira do seu data center nos próximos cinco anos.
O que é capacidade ociosa (stranded capacity) no contexto de servidores?
É o espaço de armazenamento ou poder de processamento que foi adquirido e instalado em um servidor físico (como em arquiteturas DAS), mas que não pode ser utilizado por outras máquinas na rede. Se um servidor atinge 100% de uso de CPU mas apenas 20% de uso de disco, os 80% restantes tornam-se capacidade ociosa e representam capital imobilizado sem retorno.Como o protocolo NVMe-oF resolve o problema do armazenamento isolado?
O NVMe over Fabrics (NVMe-oF) permite que os discos NVMe sejam acessados através de uma rede (como Ethernet via RoCE ou TCP) com latência quase idêntica à de um disco conectado diretamente à placa-mãe (PCIe). Isso permite agrupar todos os discos em um pool centralizado e alocar a capacidade dinamicamente para os servidores que precisam, eliminando o desperdício.A migração para NVMe-oF exige a substituição de toda a infraestrutura de rede?
Não necessariamente. Embora o NVMe-oF sobre RDMA (RoCEv2) exija switches compatíveis e placas de rede específicas para máxima performance, o padrão NVMe/TCP permite utilizar a infraestrutura Ethernet padrão existente. Isso possibilita uma adoção gradual, equilibrando o custo de capital (CAPEX) com os ganhos imediatos de eficiência.
Roberto Sato
Planejador de Capacidade
"Traduzo métricas de consumo em modelos de crescimento sustentável. Minha missão é antecipar gargalos e garantir que sua infraestrutura escale matematicamente antes de atingir o limite crítico."