O custo oculto do rebuild em all-flash: definindo SLOs de performance para evitar multas de SLA

Descubra como gerenciar a degradação de performance durante o rebuild em arrays all-flash. Aprenda a definir SLOs realistas e proteger sua operação contra multas contratuais.
A gestão de serviços de TI baseada nas melhores práticas da ITIL exige uma compreensão rigorosa dos contratos estabelecidos. No universo do armazenamento de dados corporativo, existe uma ilusão perigosa de que matrizes all-flash garantem performance infinita e ininterrupta. A realidade técnica e jurídica é muito mais severa. Quando um disco falha, o processo de reconstrução de dados se inicia e a performance invariavelmente sofre degradação. Se o seu contrato não prevê essa janela de impacto, sua operação está exposta a penalidades financeiras severas.
Resumo em 30 segundos
- A reconstrução de dados em storages all-flash consome ciclos críticos de CPU da controladora, gerando gargalos temporários.
- Prometer latência zero ininterrupta em um Acordo de Nível de Serviço (SLA) é um erro jurídico que resulta em multas.
- Estabelecer Objetivos de Nível de Serviço (SLOs) dinâmicos para estados degradados protege o provedor e alinha expectativas com o cliente.
O impacto financeiro da degradação de IOPS em infraestruturas all-flash
Para entender o risco contratual, precisamos analisar a mecânica de uma falha. Quando um disco de estado sólido (SSD) com protocolo NVMe (Non-Volatile Memory Express) apresenta defeito, a controladora do storage precisa recriar os dados perdidos usando bits de paridade distribuídos nos discos restantes. Esse processo é conhecido como rebuild.
Embora os discos NVMe sejam extremamente rápidos, o gargalo durante o rebuild não está na mídia de armazenamento. O problema reside na CPU da controladora de storage e na saturação do barramento PCIe. A controladora precisa ler os dados remanescentes, calcular a paridade e gravar as novas informações, tudo isso enquanto tenta atender às requisições normais de leitura e gravação do cliente.
O resultado direto é a queda drástica de IOPS (Operações de Entrada e Saída por Segundo) e o aumento da latência. Se um cliente financeiro executa bancos de dados transacionais que dependem de respostas em submilisegundos, essa degradação afeta diretamente o faturamento dele. Consequentemente, o prejuízo será repassado ao provedor de infraestrutura na forma de multas contratuais.
⚠️ Perigo: Ignorar o consumo de CPU durante o rebuild em matrizes all-flash é a principal causa de violação de SLAs de performance em datacenters modernos.
A armadilha contratual da latência zero durante a reconstrução de blocos
No gerenciamento de nível de serviço, a precisão matemática é inegociável. Entregar 99.9% de disponibilidade ou performance não é o mesmo que entregar 99.999%. Muitos contratos de SLA são redigidos por equipes comerciais que prometem "latência inferior a 1 milissegundo em 100% do tempo". Essa é uma armadilha jurídica clássica.
Quando o rebuild de um array RAID ou de um pool de armazenamento definido por software (como ZFS) entra em ação, a latência de cauda pode saltar de 0.5ms para 5ms ou mais. Se o SLA não possui uma cláusula de exceção ou um limite de tolerância para o estado degradado, o provedor entra em violação no exato segundo em que a latência ultrapassa o limite acordado.
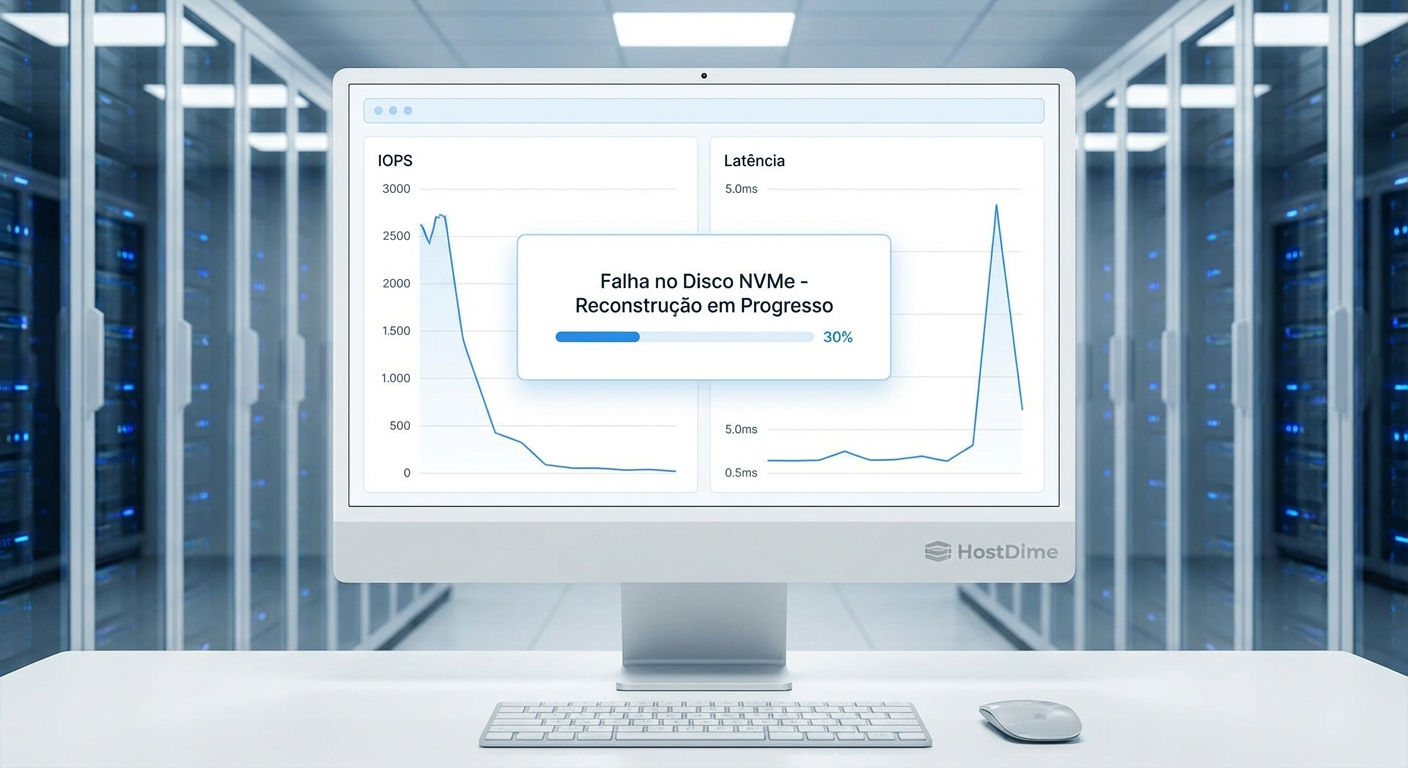 Figura: Dashboard de monitoramento de storage exibindo queda de IOPS e pico de latência durante o rebuild de um disco NVMe
Figura: Dashboard de monitoramento de storage exibindo queda de IOPS e pico de latência durante o rebuild de um disco NVMe
A ausência de salvaguardas contratuais transforma um evento de manutenção rotineiro (a troca de um disco) em um incidente crítico de quebra de contrato. O cliente não quer saber se o storage está protegendo os dados. O cliente avalia apenas se a métrica acordada no papel está sendo cumprida.
Calculando o risco: over-provisioning de controladoras vs multas por quebra de SLA
Para mitigar esse risco de performance, os arquitetos de infraestrutura geralmente recorrem ao over-provisioning. Isso significa comprar controladoras de storage com processadores muito mais potentes do que o necessário para a carga de trabalho normal, garantindo que haja CPU ociosa suficiente para absorver o impacto de um rebuild sem afetar o cliente.
No entanto, hardware enterprise de alto desempenho tem um custo elevado. O gerente de nível de serviço deve calcular o custo desse hardware adicional em comparação com o risco financeiro das multas por quebra de SLA. Em muitos casos, a engenharia financeira demonstra que é mais eficiente negociar contratos mais inteligentes do que comprar hardware ocioso.
Abaixo, detalhamos a comparação entre as duas abordagens de mitigação de risco:
| Critério de Avaliação | Over-provisioning de Hardware | SLO Dinâmico Contratual |
|---|---|---|
| Custo Inicial (CAPEX) | Altíssimo (Aquisição de controladoras premium) | Zero (Ajuste jurídico e de processos) |
| Risco de Multa (SLA) | Baixo (Hardware absorve o impacto) | Nulo (Degradação prevista em contrato) |
| Complexidade Técnica | Média (Requer dimensionamento preciso) | Baixa (Depende apenas de monitoramento) |
| Impacto no Cliente | Transparente (Performance mantida) | Visível (Queda de performance acordada) |
Como negociar janelas de degradação tolerável e estabelecer SLOs dinâmicos
A solução definitiva para este impasse é a implementação de SLOs (Service Level Objectives) dinâmicos. O SLO é a métrica interna que compõe o SLA maior. Em vez de um número estático, o contrato deve prever diferentes estados operacionais para a infraestrutura de storage.
Um contrato maduro deve estipular que, em estado normal, a latência garantida é de 1ms. Porém, deve incluir uma cláusula clara informando que, durante a reconstrução de dados devido a falhas de hardware, o SLO de latência aceitável passa a ser de 5ms por um período máximo de 12 horas.
💡 Dica Pro: Utilize ferramentas de Quality of Service (QoS) no hypervisor ou no próprio storage para limitar a velocidade do rebuild. Isso prolonga a reconstrução, mas garante que a performance do cliente não caia abaixo do SLO dinâmico acordado.
Essa abordagem legalista protege o provedor de serviços. Se o cliente exigir latência de 1ms mesmo durante falhas catastróficas, o provedor deve cobrar um prêmio financeiro substancial para justificar o investimento em espelhamento síncrono ou arquiteturas active-active de altíssimo custo.
A transparência no tempo de recuperação de dados como diferencial
A gestão de serviços de TI moderna valoriza a transparência acima de promessas irreais. Clientes corporativos que operam cargas de trabalho críticas preferem previsibilidade a surpresas. Informar proativamente o tempo estimado de recuperação e o impacto exato na performance constrói confiança.
Quando um disco falha, o sistema de monitoramento deve gerar um alerta não apenas para a equipe de infraestrutura, mas também para o painel do cliente. Mostrar que o storage está em estado de rebuild, exibindo o SLO degradado em tempo real, demonstra maturidade operacional.
Ocultar a degradação de performance e torcer para que o cliente não perceba a lentidão nas aplicações é uma falha grave de governança. A retenção de contratos enterprise depende da capacidade do provedor de provar que tem controle absoluto sobre o comportamento da infraestrutura, mesmo nos piores cenários.
Recomendação executiva para gestão de serviços
A garantia de performance em ambientes all-flash não é apenas um desafio de engenharia de storage. É fundamentalmente um desafio de gestão de contratos e alinhamento de expectativas. Revisar os SLAs atuais para incluir cláusulas de estado degradado não é um sinal de fraqueza técnica, mas sim uma demonstração de maturidade em governança de TI. Proteja sua operação documentando os limites físicos do hardware e transformando essas restrições em regras de negócio claras e auditáveis.
O que é um SLO de performance em estado degradado?
É a métrica contratual rigorosa que define o limite aceitável de queda de IOPS ou o aumento tolerável de latência enquanto a controladora do storage all-flash executa a reconstrução dos dados de um disco SSD NVMe que apresentou falha física ou lógica.Por que o rebuild em all-flash afeta a latência se os discos são rápidos?
A reconstrução de dados exige ciclos intensivos de processamento da CPU da controladora de storage e satura a largura de banda do barramento PCIe. Esse cálculo de paridade compete diretamente com as operações de leitura e gravação do cliente, gerando gargalos temporários inevitáveis na arquitetura.Como evitar multas de SLA durante falhas de hardware no storage?
A mitigação exige o estabelecimento de cláusulas contratuais explícitas que prevejam SLOs específicos e temporários para janelas de rebuild. Essa prática alinha a expectativa de degradação temporária com o cliente, garantindo a integridade dos dados sem configurar quebra de garantias ou gerar penalidades financeiras.
Arthur Sales
Gerente de Nível de Serviço
"Vivo na linha tênue entre a conformidade e a violação contratual. Para mim, 99,9% não é disponibilidade; é prejuízo. Exijo garantias absolutas e aplicação rigorosa de penalidades."