O fim do imposto de I/O: como as DPUs redefinem o storage desagregado no data center

Descubra como as Data Processing Units (DPUs) eliminam o gargalo da CPU em arquiteturas de storage desagregado, reduzindo o TCO e otimizando a topologia de I/O.
A arquitetura de data centers modernos vive um paradoxo fascinante. Por um lado, temos unidades de armazenamento NVMe (Non-Volatile Memory Express) capazes de entregar milhões de IOPS com latências na casa dos microssegundos. Por outro, temos aplicações famintas por dados que continuam esperando. A resposta padrão para o motivo desse gargalo quase sempre é: depende. Depende da sua rede, do seu hypervisor e, principalmente, de onde seus ciclos de CPU estão sendo gastos.
O problema central não está mais na mídia física. Os SSDs corporativos resolveram a física do armazenamento. O gargalo atual é arquitetural e reside no que chamamos de "imposto de I/O". Trata-se do custo computacional massivo exigido para mover dados do disco, através da rede, até a memória da aplicação. Para resolver isso, a indústria está redefinindo o papel do servidor tradicional através das DPUs (Data Processing Units).
Resumo em 30 segundos
- O processamento de protocolos de rede e storage (TCP/IP, NVMe-oF) consome até 30% dos núcleos de CPU x86 em servidores de alta densidade, gerando um "imposto de I/O" insustentável.
- As DPUs descarregam toda a pilha de infraestrutura do processador principal, gerenciando criptografia, compressão e roteamento de storage de forma independente.
- A adoção dessa arquitetura reduz drasticamente a latência de cauda e melhora o TCO, permitindo que os núcleos x86 sejam dedicados exclusivamente às aplicações faturáveis.
A saturação silenciosa dos cores de aplicação
Quando você instala um pool de drives NVMe PCIe Gen4 ou Gen5 em um servidor, a expectativa é de performance instantânea. No entanto, em um ambiente de storage desagregado (onde o armazenamento não está fisicamente no mesmo chassi que a computação), esses dados precisam trafegar pela rede. É aqui que a pilha TCP/IP do kernel Linux se torna um obstáculo formidável.
O kernel não foi desenhado para lidar com a velocidade do protocolo NVMe. Cada pacote de dados que chega pela placa de rede gera interrupções de hardware. A CPU precisa parar o que está fazendo, fazer a troca de contexto (context switch), copiar os dados do buffer do kernel para o espaço do usuário e só então entregar à aplicação. Em um cluster de storage de alto desempenho, esse processo satura rapidamente os núcleos do processador.
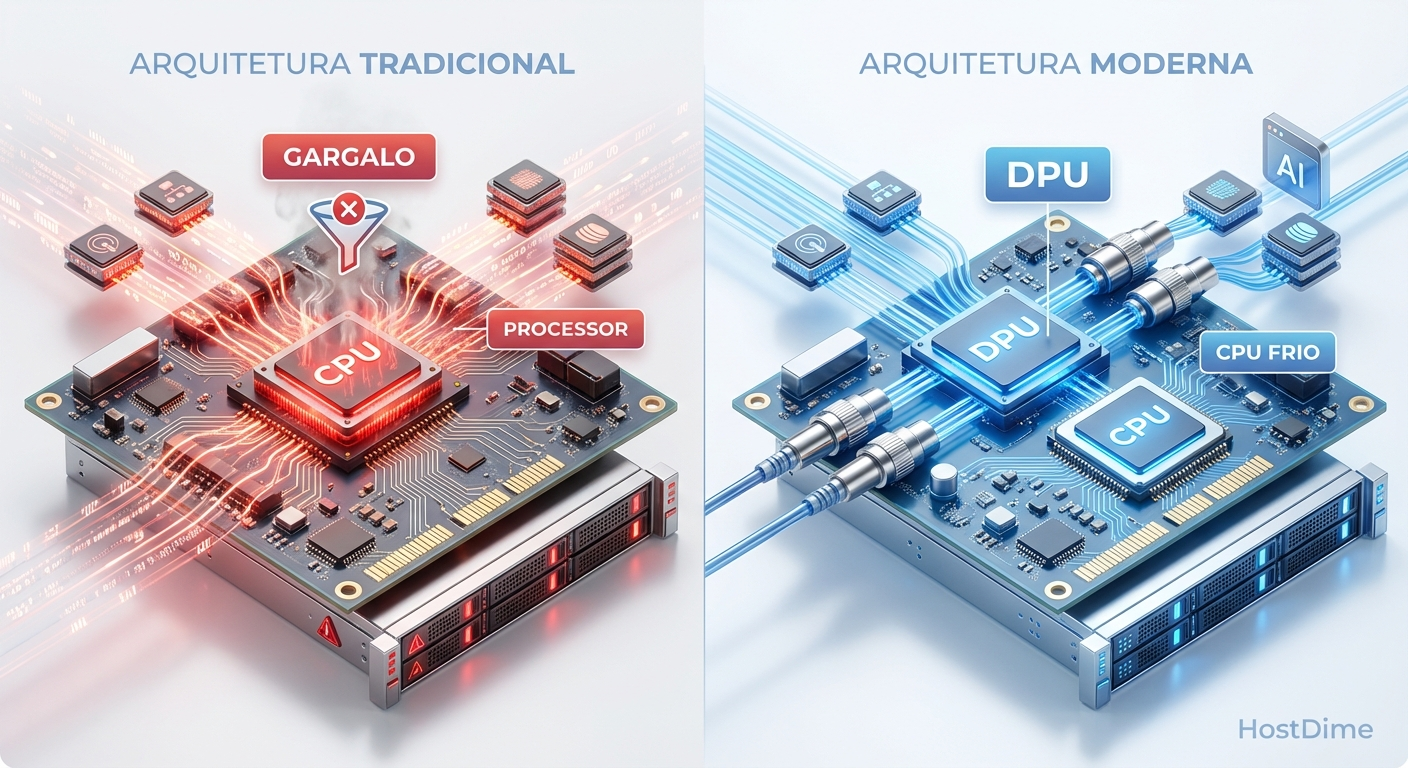 Figura: Comparação do fluxo de processamento: CPU saturada pelo imposto de I/O versus arquitetura descarregada pela DPU.
Figura: Comparação do fluxo de processamento: CPU saturada pelo imposto de I/O versus arquitetura descarregada pela DPU.
Esse fenômeno cria uma latência de cauda imprevisível. A latência de cauda (tail latency) refere-se aos tempos de resposta mais lentos experimentados pelos usuários (o percentil 99). Em bancos de dados distribuídos ou sistemas de arquivos paralelos, um único nó atrasado por interrupções de I/O compromete a performance de toda a transação.
A ilusão de escalar horizontalmente com mais processadores x86
Diante da lentidão, a reação instintiva de muitos arquitetos é adicionar mais servidores ao cluster. Se a CPU está em 100%, colocamos mais nós de computação. Essa abordagem de escalar horizontalmente (scale-out) adicionando processadores x86 de propósito geral é uma ilusão financeira e técnica.
Processadores x86 são excelentes para lógica de negócios complexa, mas são terrivelmente ineficientes para mover blocos de dados de um lado para o outro. Ao comprar um servidor de última geração apenas para lidar com o tráfego de um cluster Ceph ou vSAN, você está pagando o preço premium de núcleos de aplicação para realizar trabalho de encanamento de dados.
⚠️ Perigo: Utilizar CPUs de alto custo para gerenciar criptografia de disco (AES-XTS) ou compressão de blocos em tempo real destrói o TCO (Total Cost of Ownership) do seu projeto de storage. Você acaba comprando licenças de software e hardware caro para executar tarefas de infraestrutura.
Descarregando a infraestrutura com a arquitetura interna das DPUs
A solução para esse impasse arquitetural é a desagregação inteligente. É aqui que entram as DPUs. Uma DPU (Data Processing Unit) é um sistema em um chip (SoC) que combina núcleos de processamento eficientes (geralmente arquitetura ARM) com aceleradores de hardware dedicados para rede, storage e segurança.
Diferente de uma placa de rede tradicional, a DPU roda seu próprio sistema operacional (frequentemente um microkernel Linux). Ela se apresenta para o servidor host como um controlador NVMe padrão. O sistema operacional do servidor acha que está conversando com um disco local físico, mas a DPU está, na verdade, roteando esses blocos de dados através da rede para um array de storage remoto.
Para entender o salto evolutivo, precisamos observar as diferenças fundamentais entre os componentes de processamento no data center.
| Característica | CPU (x86/ARM Host) | SmartNIC Tradicional | DPU (Data Processing Unit) |
|---|---|---|---|
| Foco Principal | Lógica de aplicação e VMs | Aceleração básica de rede | Gestão completa de infraestrutura |
| Offload de Storage | Nenhum (Processa tudo no Kernel) | Checksums e desfragmentação | NVMe-oF, Compressão, Criptografia, RAID |
| Sistema Operacional | Roda o SO do Host (Windows/Linux) | Firmware fechado | Roda seu próprio SO independente |
| Isolamento de Segurança | Compartilhado com a aplicação | Baixo | Total (Air-gap lógico do host) |
| Impacto no TCO | Alto custo por ciclo de I/O | Redução marginal | Recupera até 30% dos cores do Host |
O impacto na latência de cauda e no TCO do servidor
A verdadeira mágica da DPU no ecossistema de storage acontece quando combinamos seu poder de processamento com protocolos modernos como o NVMe-oF (NVMe over Fabrics) utilizando RDMA (Remote Direct Memory Access).
O RDMA permite que os dados viajem do array de storage diretamente para a memória da aplicação no servidor de destino, ignorando completamente o kernel do sistema operacional e a CPU principal. A DPU gerencia essa transferência via hardware. O protocolo mais comum para isso hoje é o RoCEv2 (RDMA over Converged Ethernet).
 Figura: Fluxo de dados via RDMA: a DPU permite que o storage acesse a memória da aplicação ignorando o kernel do sistema operacional.
Figura: Fluxo de dados via RDMA: a DPU permite que o storage acesse a memória da aplicação ignorando o kernel do sistema operacional.
Ao implementar essa arquitetura, o impacto na latência de cauda é dramático. Transações de banco de dados que antes sofriam com picos de latência devido a interrupções de rede passam a ter um comportamento determinístico. A latência de acesso a um disco remoto via NVMe-oF com DPU torna-se virtualmente indistinguível da latência de um SSD NVMe espetado diretamente no barramento PCIe da placa-mãe (Direct Attached Storage).
Do ponto de vista financeiro, o TCO melhora significativamente. Se um servidor de virtualização gastava 30% de seus recursos gerenciando a pilha de storage distribuído, a introdução da DPU devolve esses recursos para o hypervisor. Isso significa que você pode hospedar 30% mais máquinas virtuais no mesmo hardware físico, adiando a necessidade de comprar novos servidores.
O futuro do storage desagregado com CXL e novos formatos
A evolução não para nas DPUs. O mercado de storage está se preparando para a adoção em massa do CXL (Compute Express Link). O CXL é um protocolo de interconexão aberto, baseado na camada física do PCIe, que permite coerência de cache entre processadores, memória e aceleradores.
Enquanto as DPUs resolvem o problema do tráfego de rede e storage em bloco, o CXL permitirá a desagregação da própria memória RAM. No futuro próximo, teremos pools de memória e pools de storage NVMe (utilizando formatos de alta densidade como o E1.S e E3.S do padrão EDSFF) gerenciados por DPUs avançadas em nível de rack.
💡 Dica Pro: O padrão EDSFF (Enterprise & Data Center Standard Form Factor) está substituindo os antigos formatos U.2. Discos E1.S (réguas curtas) permitem melhor fluxo de ar e maior densidade térmica, sendo ideais para servidores 1U equipados com DPUs de alto rendimento.
Nesse cenário, a DPU atuará como o maestro do tráfego de dados, decidindo em tempo real se um bloco de informação deve residir na memória CXL de acesso ultrarrápido ou em um array NVMe de alta capacidade, tudo de forma transparente para o servidor de aplicação.
 Figura: Visão em escala de rack: pools desagregados de computação, memória (CXL) e storage (NVMe) orquestrados por DPUs.
Figura: Visão em escala de rack: pools desagregados de computação, memória (CXL) e storage (NVMe) orquestrados por DPUs.
Recomendações para a próxima década de infraestrutura
A transição para arquiteturas baseadas em DPUs não é apenas uma atualização de hardware. É uma mudança de paradigma na forma como desenhamos data centers. Continuar comprando processadores de propósito geral para resolver problemas de I/O de storage é uma estratégia insustentável a longo prazo.
Se você está desenhando clusters de storage definido por software (SDS), ambientes de virtualização densos ou infraestruturas para inteligência artificial que exigem ingestão massiva de dados, a avaliação de DPUs deve ser mandatória. A separação clara entre o domínio da aplicação (CPU) e o domínio da infraestrutura (DPU) oferece segurança isolada, performance previsível e um TCO otimizado. O imposto de I/O finalmente encontrou seu fim.
Referências & Leitura Complementar
NVM Express Base Specification: Documentação oficial do protocolo NVMe e NVMe-oF (NVMe over Fabrics). Disponível em nvmexpress.org.
RFC 5040: A Remote Direct Memory Access Protocol Specification (IETF). Base fundamental para o entendimento de bypass de kernel.
SNIA (Storage Networking Industry Association): Especificações sobre EDSFF (Enterprise & Data Center Standard Form Factor) e arquiteturas de storage computacional.
CXL Consortium: Especificações do Compute Express Link 3.0 e seu impacto na desagregação de memória e storage.
O que diferencia uma DPU de uma SmartNIC tradicional no contexto de storage?
Depende da geração do hardware, mas fundamentalmente, uma DPU (Data Processing Unit) possui núcleos de processamento de propósito geral (como ARM) acoplados a aceleradores de hardware dedicados. Diferente de uma SmartNIC básica que apenas descarrega checksums de rede, a DPU roda seu próprio sistema operacional e gerencia toda a pilha de storage (como NVMe-oF, compressão e criptografia) de forma totalmente invisível para a CPU do host.A desagregação de storage através da rede não aumenta a latência das aplicações?
Se utilizarmos TCP/IP tradicional, sim. Porém, a arquitetura correta utiliza RDMA (Remote Direct Memory Access) sobre RoCEv2 gerenciado pela DPU. Isso permite que os dados viajem do storage array diretamente para a memória da aplicação, ignorando o kernel do host. O resultado é uma latência de rede na casa dos microssegundos, virtualmente idêntica à de um SSD NVMe local (Direct Attached Storage).Como a adoção de DPUs afeta o TCO (Total Cost of Ownership) do data center?
O impacto no TCO é altamente positivo. Em servidores de alta densidade de I/O, até 30% dos ciclos da CPU são gastos apenas gerenciando tráfego de rede e storage (o chamado 'imposto de I/O'). Ao transferir essa carga para a DPU, você recupera esses núcleos caros da CPU x86 para rodar máquinas virtuais ou contêineres faturáveis, reduzindo a necessidade de adquirir novos servidores físicos para escalar a capacidade computacional.
Otávio Henriques
Arquiteto de Soluções Enterprise
"Com duas décadas desenhando infraestruturas críticas, olho além do hype. Foco em TCO, resiliência e trade-offs, pois na arquitetura corporativa a resposta correta quase sempre é 'depende'."