O gargalo da reidratação: por que backups deduplicados falham no RTO

Entenda como o I/O aleatório destrói a performance de restores em sistemas deduplicados e descubra arquiteturas de storage para mitigar a latência de reidratação.
Você dorme tranquilo porque o relatório de backup das 08:00 mostrou "Sucesso" em letras verdes. Parabéns. Você caiu na armadilha mais antiga do livro. O sucesso do backup é irrelevante se a restauração não cumprir o RTO (Recovery Time Objective) estipulado pelo negócio. E é aqui que a matemática fria do armazenamento colide com a realidade do desastre: seus dados estão seguros, mas estão trancados atrás de uma parede de latência mecânica.
A deduplicação é uma maravilha para o orçamento de armazenamento. Ela permite guardar petabytes de histórico em alguns terabytes de disco físico. Mas essa eficiência cobra um imposto brutal no momento mais crítico da sua carreira: a recuperação. Quando o ransomware ataca ou o storage primário derrete, você descobre que "reidratar" esses dados deduplicados em discos rotacionais é como tentar beber um milkshake congelado por um canudo de café.
Resumo em 30 segundos
- Fragmentação Lógica: A deduplicação quebra arquivos grandes em milhares de blocos pequenos espalhados pelo disco, transformando leituras sequenciais em aleatórias.
- A Física do HDD: Discos mecânicos (NL-SAS) têm um limite físico de IOPS. A reidratação exige um número de operações de busca (seek) que excede a capacidade mecânica dos atuadores.
- Solução Híbrida: A única forma de garantir RTOs agressivos hoje é utilizar "Landing Zones" em flash ou manter o backup mais recente em formato nativo (não deduplicado).
A anatomia do desastre: o que é reidratação
Para entender o problema, precisamos olhar para como o dado é gravado no disco. Em um cenário sem deduplicação, um arquivo de VM (como um VMDK ou VHDX) é gravado de forma razoavelmente sequencial. Quando você precisa ler esse arquivo de volta, a cabeça do disco se posiciona e lê trilhas contínuas de dados. Isso é rápido. Discos rígidos amam I/O sequencial.
A deduplicação muda essa lógica. Ela analisa o fluxo de dados, identifica blocos únicos, salva apenas uma cópia desse bloco e cria um mapa de ponteiros (hash table/metadata) para reconstruir o arquivo depois.
Quando você clica em "Restore", o software de backup precisa realizar a reidratação. Ele consulta o mapa, busca o bloco A no setor X, depois o bloco B no setor Y, depois o bloco C (que pode ser uma referência a um backup de três meses atrás) no setor Z.
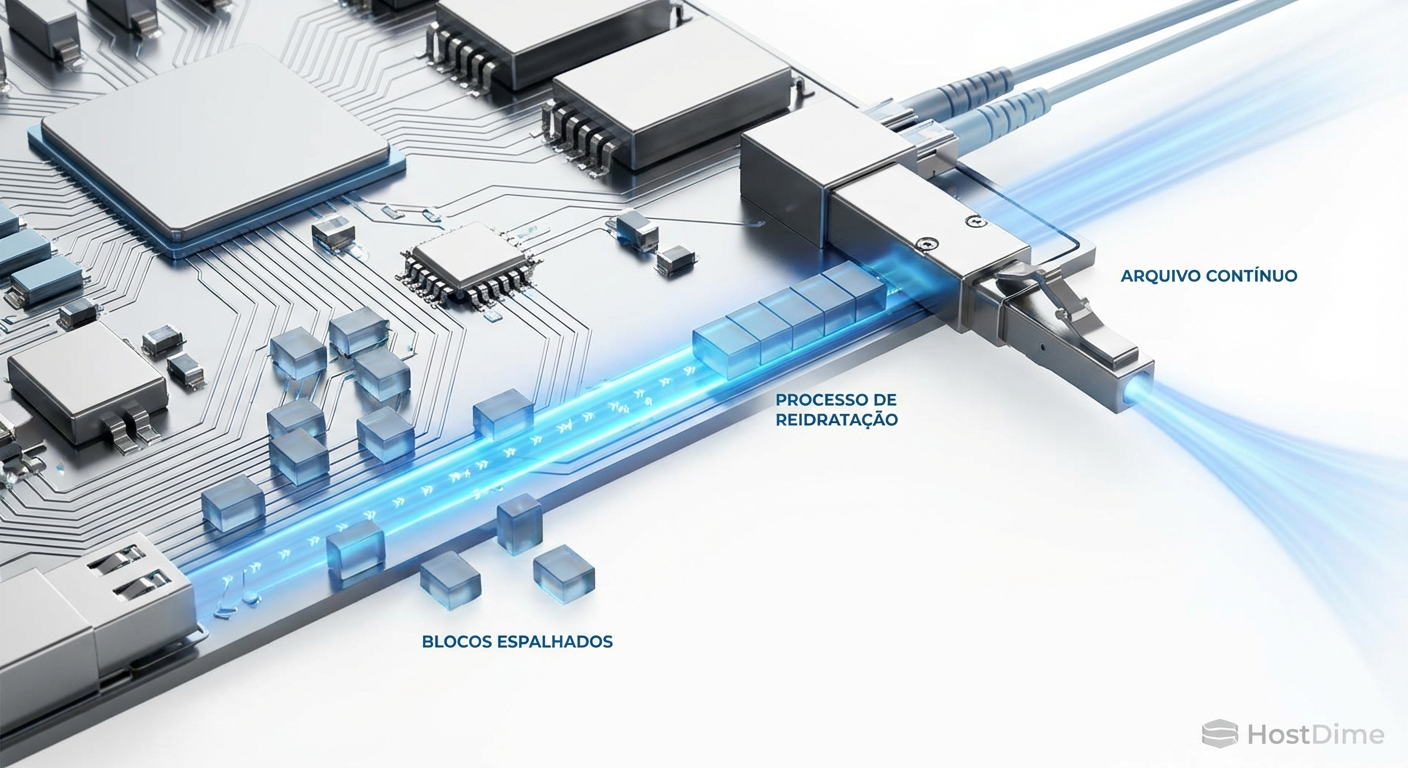 Figura: O processo de reidratação: remontando o quebra-cabeça de blocos espalhados para entregar um arquivo contínuo.
Figura: O processo de reidratação: remontando o quebra-cabeça de blocos espalhados para entregar um arquivo contínuo.
O resultado? O que deveria ser uma leitura sequencial de alto rendimento se transforma no pior pesadelo de um storage: I/O 100% aleatório de leitura.
A penalidade física do seek time em discos NL-SAS
Aqui entramos na física pura. A maioria dos repositórios de backup de alta densidade utiliza discos NL-SAS (Nearline SAS) de 7.200 RPM. Esses discos são excelentes para custo por TB, mas péssimos em latência.
Um disco de 7.200 RPM consegue entregar, em média, 80 a 120 IOPS (Input/Output Operations Per Second). Apenas isso. Se você tem um array RAID 6 com 12 discos, você tem um teto teórico de performance para leituras aleatórias.
⚠️ Perigo: A densidade dos discos aumentou (18TB, 22TB, 24TB), mas a velocidade do atuador mecânico permaneceu a mesma. Isso significa que a performance por TB caiu drasticamente na última década.
Durante uma reidratação de uma VM crítica de 2TB, o sistema de backup pode exigir milhares de IOPS para buscar os blocos fragmentados. Seus discos mecânicos entram em saturação total. A latência dispara de 10ms para 200ms, 500ms ou mais. A taxa de transferência, que no papel seria de 500 MB/s, cai para ridículos 20 MB/s.
Nesse ritmo, sua restauração de 4 horas vai levar 4 dias. E o CEO está na sua mesa perguntando por que o sistema ainda está fora do ar.
A falácia do upgrade de rede
É comum ver administradores de infraestrutura diagnosticarem esse problema de forma errada. Eles veem a taxa de transferência baixa no console do backup e culpam a rede.
"Vamos colocar placas de 25GbE ou fazer um LACP de 4 portas!"
Isso é jogar dinheiro fora. O gargalo não é o tubo por onde os dados passam; o gargalo é a capacidade do disco de encontrar os dados. Você pode ter um link de 100GbE entre o servidor de backup e o host de virtualização; se os discos estiverem "thrashing" (a cabeça de leitura batendo de um lado para o outro freneticamente) tentando remontar arquivos deduplicados, a rede ficará ociosa.
Landing Zones e a necessidade do Flash
Para mitigar esse cenário, a arquitetura de backup moderna precisou evoluir. A abordagem de "Deduplicação em Linha Direto para o Disco" (Inline Dedupe to Disk) pura tornou-se arriscada para cargas de trabalho Tier-1.
Surgiram duas abordagens principais para resolver o gargalo da reidratação:
Landing Zones (Zonas de Aterrissagem): Popularizada por vendors como a ExaGrid, essa arquitetura grava o backup mais recente em uma área do disco sem deduplicação (formato nativo). A deduplicação e compressão ocorrem em segundo plano para uma área de retenção de longo prazo.
- Vantagem: 95% das restaurações vêm do backup mais recente. Como os dados não estão fragmentados, a leitura é sequencial e rápida, limitada apenas pela velocidade física do disco, não pelo seek time.
Tiering com Flash/SSD: Utilizar um pool de SSDs como camada de ingestão e cache de leitura. Softwares modernos permitem configurar "Performance Tiers" onde os backups residem por alguns dias antes de serem movidos para discos capacitivos (Capacity Tier).
 Figura: Comparativo de arquitetura: Appliance tradicional sofrendo com latência vs. Arquitetura com Landing Zone em Flash para ingestão e restauração rápida.
Figura: Comparativo de arquitetura: Appliance tradicional sofrendo com latência vs. Arquitetura com Landing Zone em Flash para ingestão e restauração rápida.
Tabela Comparativa: Arquiteturas de Repositório
| Característica | Deduplicação Pura (HDD) | Landing Zone / Híbrido | All-Flash Backup |
|---|---|---|---|
| Custo por TB | Baixo ($) | Médio ($$) | Alto ($$$$) |
| Performance de Ingestão | Limitada pela CPU (hash) | Alta (escrita sequencial) | Altíssima |
| Performance de Restore (RTO) | Péssima (Gargalo de Reidratação) | Excelente (Leitura Nativa) | Instantânea |
| Instant VM Recovery | Lento/Inutilizável | Rápido | Nativo |
| Caso de Uso Ideal | Arquivamento / Longo Prazo | Recuperação Operacional | Cargas Críticas / DBs |
O teste de fogo: Instant VM Recovery
A prova definitiva de que seu repositório de backup não aguenta o tranco é o recurso de Instant VM Recovery (IVMR). Essa tecnologia permite ligar uma máquina virtual diretamente do arquivo de backup, sem precisar copiar os dados para o storage de produção primeiro.
O IVMR transforma seu repositório de backup em um datastore de produção temporário. Um sistema operacional moderno (Windows Server ou Linux) realiza muita leitura e escrita aleatória apenas para bootar e rodar serviços básicos.
Se o seu backup estiver deduplicado em discos mecânicos, a latência de I/O será tão alta que o sistema operacional da VM pode travar por timeout de disco. Você verá a VM ligada no console do Hypervisor, mas ela estará não responsiva.
💡 Dica Pro: Não confie no teste de "Verificação de Backup" padrão que apenas lê o arquivo para checar CRC. Agende testes automatizados que realmente ligam a VM a partir do backup e executam um script dentro dela. Se o script falhar por timeout, seu RTO é uma mentira.
O futuro é NVMe (e o fim da reidratação como problema)
Estamos nos aproximando de um ponto de inflexão no custo do armazenamento flash. Com a introdução de memórias QLC (Quad-Level Cell) de alta densidade e novos formatos de SSD Enterprise (como E1.S e E3), o custo do flash está se aproximando perigosamente do custo de discos SAS de alta performance (10k/15k RPM - que já estão mortos).
A adoção de repositórios baseados em NVMe elimina quase completamente a penalidade da reidratação. SSDs NVMe são massivamente paralelos. Eles não têm cabeças de leitura que precisam se mover fisicamente. Para um SSD, ler o bloco A e depois o bloco Z tem praticamente o mesmo custo de tempo que ler o bloco A e depois o bloco B.
 Figura: A estabilidade do NVMe: latência consistente independente da fragmentação dos dados, o fim do gargalo mecânico.
Figura: A estabilidade do NVMe: latência consistente independente da fragmentação dos dados, o fim do gargalo mecânico.
Enquanto o All-Flash não se torna barato o suficiente para retenção de 5 anos, a regra de ouro permanece: Discos rotacionais são para guardar dados frios. Flash (ou Landing Zones) é para recuperar dados quentes.
O veredito do operador
Não desenhe sua infraestrutura de backup pensando apenas em quanto espaço você vai economizar. O CFO adora ouvir que a taxa de deduplicação é de 20:1, mas ele vai demitir você se a restauração do ERP levar 18 horas em vez de 2.
A reidratação é um processo computacional e fisicamente intensivo. Se você depende de discos mecânicos, você deve garantir que seus dados mais recentes estejam em formato nativo ou ter uma camada de cache robusta.
Backup não é sobre copiar dados. É sobre a capacidade de trazê-los de volta quando o mundo está pegando fogo. Se você não testou a velocidade de reidratação do seu full backup deduplicado, você não tem um plano de DR; você tem apenas uma esperança. E esperança não é uma estratégia.
Referências & Leitura Complementar
SNIA (Storage Networking Industry Association): Dictionary of Storage Networking Terminology - Definições de Deduplicação e Data Hydration.
Veeam KB: "Restore performance best practices" - Documentação técnica sobre impacto de repositórios deduplicados.
Gartner: "Magic Quadrant for Enterprise Backup and Recovery Software Solutions" - Análises sobre arquiteturas de Tiered Backup Storage.
Seagate Datasheets: Especificações de discos Exos X-Series (demonstrando limites de IOPS em discos de alta densidade).
Perguntas Frequentes (FAQ)
O que é a reidratação de dados no contexto de backup?
É o processo inverso da deduplicação. Imagine que seu software de backup picotou seus arquivos em milhares de pedaços únicos para economizar espaço. A reidratação é o trabalho pesado de remontar esses blocos fragmentados e reconstruir o arquivo original (como uma VM ou banco de dados) para que ele possa ser usado novamente durante uma restauração.Por que a reidratação é lenta em discos rígidos (HDD)?
Porque é um problema de física. Os blocos de dados deduplicados estão espalhados fisicamente por todo o prato do disco. Para remontar o arquivo, a cabeça de leitura mecânica precisa realizar milhares de movimentos (seek) aleatórios para buscar cada pedacinho. HDDs são péssimos nisso; eles gostam de ler em linha reta, não de ficar pulando de um lado para o outro.Como o uso de SSDs ou Landing Zones resolve o problema da reidratação?
De duas formas. SSDs têm latência de busca próxima de zero, então eles não se importam se os dados estão espalhados; eles buscam tudo instantaneamente. Já as Landing Zones (Zonas de Aterrissagem) usam uma estratégia diferente: elas mantêm o backup mais recente "hidratado" (inteiro, sem deduplicação) ou usam flash como cache, permitindo que a leitura seja sequencial e rápida, sem o trabalho de remontagem.
Silvio Zimmerman
Operador de Backup & DR
"Vivo sob o lema de que backup não existe, apenas restore bem-sucedido. Minha religião é a regra 3-2-1 e meu hobby é desconfiar da integridade dos seus dados."