O gargalo do instant recovery: como a latência do NL-SAS sabota seu RTO

Descubra por que o Instant Recovery falha miseravelmente em repositórios com discos NL-SAS e aprenda a arquitetar o storage de backup para garantir seu RTO.
O mercado de proteção de dados adora vender ilusões confortáveis. A maior delas é a promessa de que você pode ter um repositório de backup massivo, barato e, ao mesmo tempo, capaz de ressuscitar seu ambiente inteiro em segundos. Como um operador focado em recuperação de desastres, eu repito este mantra diariamente: o backup não existe, apenas o restore importa. Se o seu plano de continuidade de negócios depende de ligar máquinas virtuais críticas diretamente de um storage lotado de discos mecânicos de alta capacidade, você está caminhando para um abismo operacional.
A tecnologia de recuperação instantânea mudou as regras do jogo, permitindo que um hypervisor monte o arquivo de backup e inicie o sistema operacional sem copiar os dados de volta para o storage principal. O problema é que o marketing esqueceu de avisar sobre a física. Quando o desastre atinge seu datacenter e o relógio do RTO (Recovery Time Objective) começa a correr, a latência do seu repositório dita se você será o herói do dia ou o profissional que vai atualizar o currículo.
Resumo em 30 segundos
- A recuperação instantânea transforma seu storage de backup em um storage primário temporário, exigindo altíssima performance de leitura aleatória.
- Discos mecânicos de 7.200 RPM entregam no máximo 80 IOPS cada, sendo fisicamente incapazes de suportar a tempestade de I/O de múltiplos sistemas operacionais iniciando.
- A única arquitetura viável para RTOs agressivos é o uso de camadas, com uma zona de aterrissagem em flash (SSD/NVMe) para os backups mais recentes.
A ilusão do boot instantâneo e o colapso das máquinas virtuais
O conceito de Instant Recovery é brilhante no papel. O software de backup cria um datastore NFS ou iSCSI temporário, apresenta isso ao VMware vSphere ou Microsoft Hyper-V, e a máquina virtual (VM) é ligada diretamente do arquivo compactado e deduplicado. Para o hypervisor, aquele repositório de backup agora é um storage de produção.
Aqui começa o pesadelo. Um sistema operacional moderno iniciando gera uma carga massiva de leituras pequenas e totalmente aleatórias. O Windows ou o Linux estão buscando DLLs, arquivos de registro e drivers espalhados por todo o disco virtual. Se o seu repositório de backup foi desenhado apenas para ser um cofre barato e profundo, ele vai engasgar.
Quando a latência de leitura ultrapassa a marca dos 30 a 50 milissegundos, o sistema operacional convidado dentro da VM começa a apresentar falhas. Serviços críticos como bancos de dados entram em modo de pânico, conexões de rede expiram e, em muitos casos, a máquina virtual simplesmente exibe uma tela azul ou entra em um loop infinito de inicialização. Você tem o backup, o software diz que a VM está ligada, mas a aplicação continua fora do ar. O seu RTO foi sabotado pela infraestrutura subjacente.
⚠️ Perigo: Nunca confunda a velocidade de ingestão de backup com a velocidade de recuperação. Um storage pode gravar dados sequenciais a 2 GB/s e falhar miseravelmente ao tentar ler 50 MB/s de forma aleatória.
A física contra o marketing: por que 7.200 RPM não suportam IOPS aleatórios
Para entender o colapso, precisamos olhar para o hardware. A esmagadora maioria dos repositórios de backup corporativos é construída com discos NL-SAS (Nearline Serial Attached SCSI). Estes discos combinam a interface SAS corporativa com a mecânica dos discos SATA tradicionais, girando a 7.200 RPM (Rotações Por Minuto).
Eles são fantásticos para o propósito original: receber fluxos contínuos e sequenciais de dados. O braço mecânico do disco se posiciona e grava trilhas inteiras sem precisar pular de um lado para o outro. No entanto, a recuperação instantânea exige leitura aleatória. O braço mecânico precisa se mover fisicamente para buscar blocos de 4KB espalhados pelos pratos magnéticos.
A física pura dita que um disco de 7.200 RPM pode entregar, no melhor dos cenários, cerca de 75 a 80 IOPS (Input/Output Operations Per Second) aleatórios. Uma única máquina virtual Windows Server inicializando pode exigir picos de 500 a 1.000 IOPS. Se você tentar ligar cinco VMs simultaneamente a partir de um array com 12 discos NL-SAS, a fila de comandos no controlador de storage vai explodir.
Comparativo de performance em cenários de recuperação
Para ilustrar o abismo de performance, veja como as tecnologias se comportam quando forçadas a atuar como storage primário durante um desastre:
| Característica | Disco NL-SAS (7.200 RPM) | SSD Enterprise (SATA/SAS) | SSD NVMe (PCIe) |
|---|---|---|---|
| Foco de Arquitetura | Capacidade e retenção longa | Performance mista | Baixíssima latência |
| IOPS Aleatório (Leitura) | ~80 IOPS | ~80.000 IOPS | ~500.000+ IOPS |
| Latência Média | 10ms a 20ms+ | < 1ms | < 0.1ms |
| Comportamento no Boot Storm | Fila satura, VMs travam | Suporta múltiplas VMs | Suporta dezenas de VMs |
| Custo por Terabyte | Muito Baixo | Médio | Alto |
O erro de adicionar mais discos de alta capacidade para tentar diluir a latência
Uma armadilha comum na qual muitos administradores caem é tentar resolver o problema de IOPS adicionando mais discos ao array. No passado, quando usávamos discos de 1TB ou 2TB, criar um RAID 60 com 40 discos fornecia uma quantidade razoável de eixos mecânicos (spindles) trabalhando em paralelo, o que mitigava levemente a latência.
Hoje, a indústria de storage empurra discos NL-SAS de 18TB, 20TB e até 24TB. Se você precisa de 100TB de repositório, pode atingir essa marca com apenas cinco ou seis discos. O problema é que a densidade de dados aumentou exponencialmente, mas a performance mecânica continua exatamente a mesma de vinte anos atrás. Você tem uma quantidade colossal de dados dependendo de apenas meia dúzia de braços mecânicos.
 Figura: A densidade contra a performance: poucos discos de altíssima capacidade reduzem drasticamente a quantidade de braços mecânicos disponíveis para processar IOPS.
Figura: A densidade contra a performance: poucos discos de altíssima capacidade reduzem drasticamente a quantidade de braços mecânicos disponíveis para processar IOPS.
Tentar fazer Instant Recovery de um banco de dados SQL Server a partir de um array composto por poucos discos de 20TB é pedir para o sistema falhar. A latência de cauda (tail latency) vai disparar. A latência de cauda ocorre quando a maioria das requisições de I/O é atendida em tempo aceitável, mas uma pequena porcentagem demora centenas de milissegundos porque o disco estava ocupado buscando dados na outra extremidade do prato magnético. Para um banco de dados transacional, essa inconsistência é fatal.
Arquitetura de repositório em camadas: flash para aterrissagem e discos densos para retenção
Como um paranoico profissional, eu não confio em uma única camada de storage para resolver todos os problemas. A regra 3-2-1 (três cópias dos dados, em duas mídias diferentes, com uma cópia fora do site) exige inteligência na alocação. A solução definitiva para o gargalo do RTO é a arquitetura de storage em camadas (Tiered Storage).
Você deve desenhar seu repositório primário de backup com uma "Landing Zone" (zona de aterrissagem) baseada em armazenamento flash. Pode ser SSDs SAS corporativos ou, se o orçamento permitir, drives NVMe (Non-Volatile Memory Express), que se comunicam diretamente com o barramento PCIe do servidor, eliminando a latência das controladoras tradicionais.
Os backups diários mais recentes caem nesta camada flash. Estatisticamente, mais de 90% das restaurações operacionais ocorrem a partir de backups feitos nas últimas 48 horas. Se um servidor for infectado por ransomware ou um patch de atualização destruir o sistema operacional, você aciona o Instant Recovery a partir da camada flash. As VMs vão iniciar com latência sub-milissegundo, entregando uma experiência idêntica ou até superior ao storage de produção original.
💡 Dica Pro: Configure as políticas do seu software de proteção de dados para mover automaticamente os arquivos de backup mais antigos da camada flash para os discos NL-SAS após 3 ou 7 dias. Assim, você usa o flash para RTO agressivo e os discos mecânicos apenas para retenção de longo prazo e conformidade.
Teste de estresse do plano de recuperação: medindo a latência de leitura
Ter a arquitetura correta é apenas o primeiro passo. O verdadeiro teste de um operador de DR é provar que a teoria funciona sob pressão. Você não pode esperar um ataque cibernético para descobrir que seu storage de backup tem um gargalo de controladora ou de rede.
Você precisa simular um "Boot Storm" (tempestade de inicialização). Escolha um final de semana e inicie o processo de Instant Recovery de 10 a 20 máquinas virtuais simultaneamente a partir do seu repositório. Durante este processo, abra os monitores de performance do seu hypervisor e do seu storage.
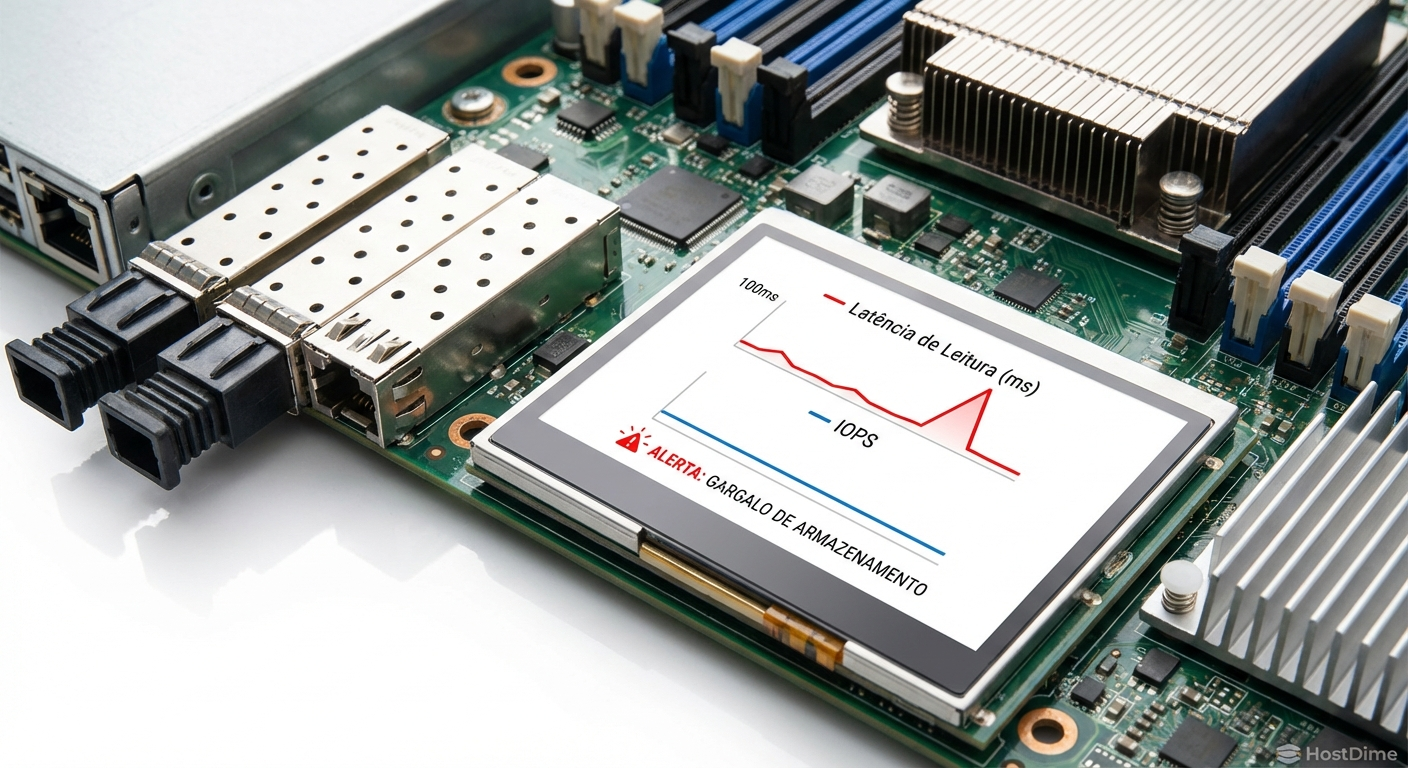 Figura: Monitoramento de latência: o gráfico exibe o exato momento em que a fila de I/O do storage satura durante a inicialização simultânea de várias máquinas virtuais.
Figura: Monitoramento de latência: o gráfico exibe o exato momento em que a fila de I/O do storage satura durante a inicialização simultânea de várias máquinas virtuais.
Observe atentamente a métrica de "Device Latency" (latência do dispositivo físico) e "Kernel Latency" (latência introduzida pela pilha de software do hypervisor). Se a latência de leitura sustentada ultrapassar 20ms, seu ambiente está em risco. Se bater 50ms, suas aplicações vão começar a falhar silenciosamente. Este teste de estresse revelará se a sua rede de backup (geralmente 10GbE ou 25GbE) está configurada corretamente com Jumbo Frames e se os discos estão realmente entregando o que o fabricante prometeu.
O veredito da recuperação
A infraestrutura de proteção de dados não é um depósito de lixo digital onde você joga arquivos e espera nunca mais olhar para eles. Ela é a sua apólice de seguro mais crítica. Continuar comprando storage de backup baseando-se apenas no menor custo por terabyte é uma negligência arquitetônica.
A latência do NL-SAS não é um defeito do disco, é uma característica física que não pode ser contornada por algoritmos mágicos de software. Se o seu negócio exige que os sistemas voltem ao ar em minutos após um desastre, você precisa investir em IOPS de leitura no seu repositório. Adote a zona de aterrissagem em flash, teste seus limites de I/O implacavelmente e pare de tratar o backup como um mal necessário. Trate-o como o seu storage de produção reserva, porque no dia em que tudo der errado, é exatamente isso que ele será.
Referências & Leitura Complementar
SNIA (Storage Networking Industry Association): Dicionário de termos de armazenamento e especificações de IOPS para mídias magnéticas e de estado sólido.
RFC 3720: Especificação do protocolo iSCSI (Internet Small Computer Systems Interface), fundamental para entender o encapsulamento de comandos SCSI sobre redes IP durante o Instant Recovery.
JEDEC Solid State Technology Association: Padrões de performance e resistência para drives SSD corporativos (JESD218).
O que é Instant Recovery e como ele interage com o storage de backup?
É a tecnologia que permite ligar uma máquina virtual diretamente dos arquivos de backup compactados, sem precisar copiá-los antes para o storage de produção. Ela exige altíssima performance de leitura aleatória do repositório, pois o hypervisor passa a ler blocos do sistema operacional diretamente dos discos de backup. Se o storage for lento, a recuperação falha.Por que discos NL-SAS são ruins para rodar máquinas virtuais?
Discos NL-SAS operam a 7.200 RPM e são otimizados para gravação sequencial de grandes blocos, o que é ideal para arquivamento profundo. Eles entregam um IOPS aleatório patético, cerca de 75 a 80 IOPS por disco. Quando um sistema operacional tenta dar boot a partir deles, a fila de I/O satura instantaneamente, causando latência extrema, telas azuis e o travamento completo da VM.Como posso usar discos de alta capacidade sem prejudicar o RTO?
A única saída segura é adotar uma arquitetura de storage em camadas (Tiered Storage). Utilize SSDs ou NVMe para a camada de aterrissagem (Landing Zone) e para a execução do Instant Recovery. Os backups mais antigos devem ser movidos para os discos NL-SAS apenas para retenção de longo prazo, onde a performance aleatória não é um requisito crítico e a física não vai sabotar sua operação.
Silvio Zimmerman
Operador de Backup & DR
"Vivo sob o lema de que backup não existe, apenas restore bem-sucedido. Minha religião é a regra 3-2-1 e meu hobby é desconfiar da integridade dos seus dados."