O imposto da performance: por que jogar fora 20% do seu SSD é a única saída

Descubra como o over-provisioning manual reduz a latência de cauda e aumenta a vida útil dos seus SSDs enterprise. Um guia pragmático para sysadmins cansados de IOPS instáveis.
Você comprou o SSD mais rápido do mercado. Aquele com números sequenciais astronômicos na caixa, luzes RGB (espero que não no servidor) e promessas de IOPS infinitos. Você instalou, migrou o banco de dados e tudo voou. Por duas semanas.
Então, numa terça-feira qualquer, o Zabbix começa a gritar. A latência de disco, que era um traço plano no chão, agora parece o eletrocardiograma de alguém tendo um ataque cardíaco. O disco não está quebrado. O SMART diz que está tudo bem. Mas o seu banco de dados está se arrastando como se estivesse rodando em um HDD de 5400 RPM conectado via USB 2.0.
O problema não é o hardware. O problema é a ganância. Você tentou usar 100% do disco que pagou. E na física ingrata da memória NAND Flash, isso é um pecado capital punido com latência.
Resumo em 30 segundos
- A mentira do espaço livre: SSDs não conseguem sobrescrever dados diretamente. Eles precisam apagar blocos inteiros antes de escrever, um processo lento e custoso.
- O abismo dos 80%: Quando um SSD ultrapassa 80% de ocupação real, o controlador entra em pânico tentando encontrar blocos limpos, disparando a latência (p99) para a estratosfera.
- A solução impopular: Deixar 20% a 30% da capacidade bruta do disco não alocada (Over-provisioning) é a única forma física de garantir performance sustentada e evitar a morte prematura do drive.
A física hostil da memória NAND
Para entender por que você precisa jogar fora um quinto do seu armazenamento, precisamos descer ao nível microscópico. Diferente dos discos magnéticos, onde a cabeça de gravação simplesmente magnetiza um bit de 0 para 1 e vice-versa, a memória flash é temperamental.
Em um SSD, você pode ler e escrever em unidades pequenas chamadas Páginas (geralmente 4KB ou 8KB). No entanto, você só pode apagar em unidades muito maiores chamadas Blocos (que contêm centenas de páginas, totalizando vários MBs).
Aqui está a pegadinha: você não pode escrever em uma página que já tem dados. Você precisa apagá-la primeiro. Mas como você só pode apagar o bloco inteiro, o processo para modificar um mísero arquivo de 4KB em um disco cheio se torna um pesadelo logístico chamado "Read-Modify-Write".
O controlador lê o bloco inteiro (vários MBs) para a memória cache.
Ele modifica a página de 4KB na memória.
Ele apaga o bloco inteiro no chip NAND.
Ele reescreve o bloco inteiro de volta.
Isso é lento. Isso desgasta o disco. E isso mata a sua latência.
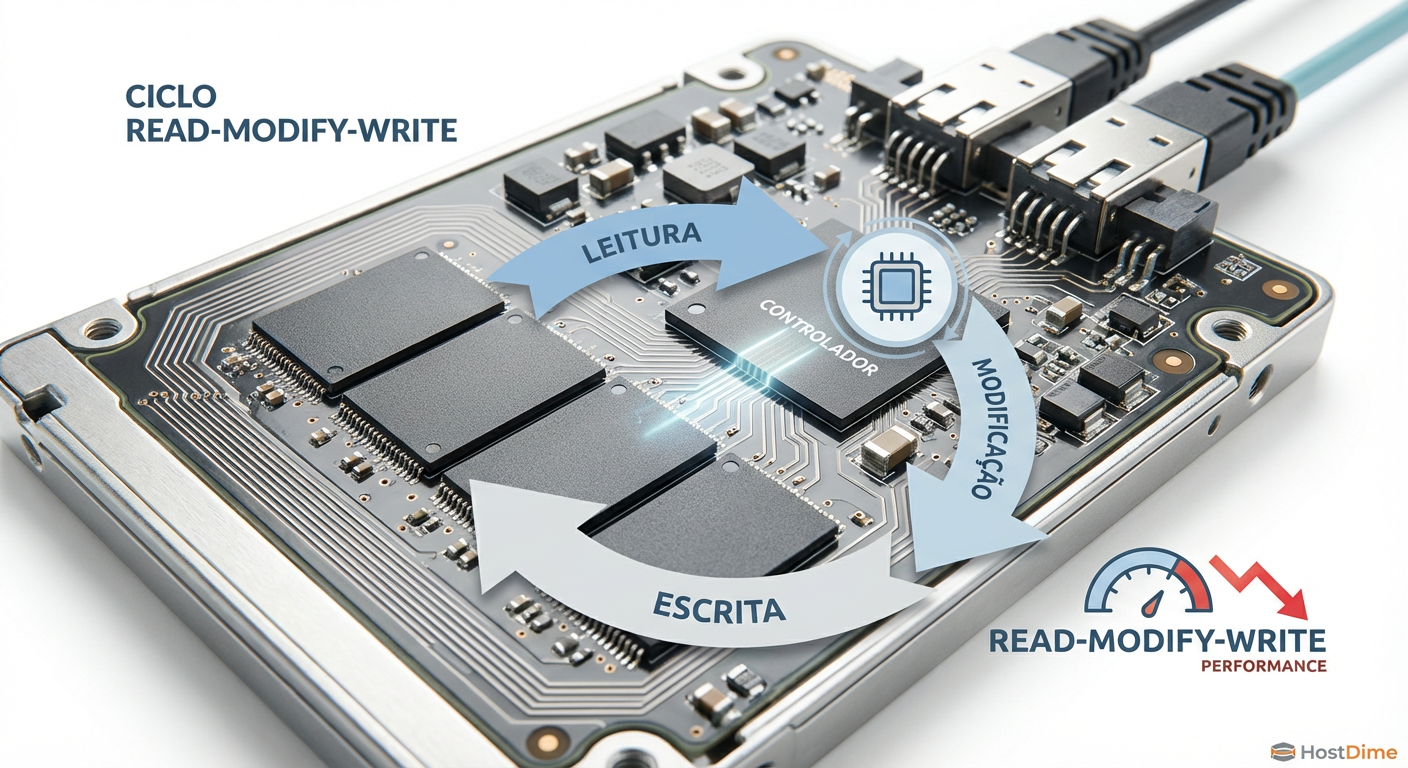 Figura: O ciclo infernal de Read-Modify-Write em um SSD sem espaço livre: onde a performance vai para morrer.
Figura: O ciclo infernal de Read-Modify-Write em um SSD sem espaço livre: onde a performance vai para morrer.
O mito do Garbage Collection mágico
Os fabricantes de controladores (Phison, Silicon Motion, Marvell) tentam esconder essa complexidade de você usando um processo de fundo chamado Garbage Collection (GC). O GC varre o disco nos momentos de inatividade, consolidando páginas válidas e apagando blocos sujos para deixá-los prontos para escrita.
Funciona bem quando você tem 50% de espaço livre. O controlador tem uma vasta "área de manobra" para mover dados sem impactar a operação principal.
Mas quando você enche o disco até a borda — digamos, 90% ou 95% de ocupação — o GC não tem para onde correr. Ele começa a competir diretamente com as suas escritas de produção. Cada comando INSERT no seu banco de dados tem que esperar o controlador limpar um bloco em tempo real. É aqui que a latência de cauda (p99) salta de 0.5ms para 50ms ou mais. O sistema trava, a aplicação dá timeout, e você recebe uma ligação.
⚠️ Perigo: Discos de consumo (Consumer/Client) são otimizados para "burst performance" (velocidade máxima por poucos segundos). Eles colapsam sob carga sustentada quando cheios. Discos Enterprise são projetados para manter a consistência, mas mesmo eles não podem violar as leis da física se não houver espaço livre.
Amplificação de Escrita: O assassino silencioso
A consequência direta de operar um SSD sem espaço de manobra é a Amplificação de Escrita (Write Amplification Factor - WAF).
Em um cenário ideal, você pede para o sistema operacional escrever 1GB, e o SSD escreve 1GB na NAND. WAF = 1. Em um cenário de disco cheio, para escrever aquele mesmo 1GB, o controlador pode precisar mover, consolidar e reescrever 4GB de dados internos para liberar espaço. WAF = 4.
Isso não apenas destrói a performance, mas tritura a vida útil do seu drive. Um SSD com durabilidade de 1 DWPD (Drive Writes Per Day) pode falhar em meses se o WAF for consistentemente alto devido à falta de espaço livre. Você está literalmente queimando dinheiro para manter dados que mal cabem no disco.
Over-provisioning: O imposto necessário
A solução é brutalmente simples e dói no bolso: Over-provisioning (OP).
OP é a prática de reservar uma porcentagem da capacidade total da memória flash para uso exclusivo do controlador do SSD. O sistema operacional não vê esse espaço. Ele não pode ser formatado. Ele não existe para o usuário. Ele é o "pulmão" do controlador.
Todos os SSDs já vêm com um mínimo de OP de fábrica (geralmente cerca de 7%, que é a diferença entre GiB binário e GB decimal). Mas para cargas de trabalho de servidor, especialmente bancos de dados transacionais ou virtualização, 7% é uma piada.
A regra de ouro do Sysadmin Veterano
Para garantir performance estável (Steady State), você deve configurar o OP manualmente.
Nível Conservador: 10-15% de espaço não alocado.
Nível Performance (Bancos de Dados): 20-28% de espaço não alocado.
Nível Paranoico (Write-Intensive/Logs): 40-50% de espaço não alocado.
Sim, isso significa comprar um drive de 2TB e formatar apenas 1.4TB. Parece desperdício? Compare o custo de um SSD extra com o custo da sua equipe parada ou clientes reclamando de lentidão.
💡 Dica Pro: Você pode aplicar OP via software em qualquer SSD. Basta usar o comando
hdparm(com cuidado extremo) para definir a HPA (Host Protected Area) ou, mais simplesmente, deixar o final do disco sem particionar na hora da instalação. O controlador do SSD é inteligente o suficiente para usar qualquer bloco LBA não mapeado como área de OP dinâmica.
Comparativo: O custo da teimosia
Vamos aos números. O que acontece quando você ignora o aviso e enche o disco versus quando você aceita pagar o imposto da performance.
| Métrica | SSD Cheio (95% Ocupado) | SSD com 25% de Over-provisioning | O que isso significa? |
|---|---|---|---|
| IOPS de Escrita Aleatória | 5.000 (Instável) | 45.000 (Estável) | O OP mantém o fluxo de escrita contínuo. |
| Latência p99 (QoS) | > 25ms | < 2ms | Seus usuários param de reclamar de "travadinhas". |
| Write Amplification (WAF) | 3.5x - 5.0x | 1.1x - 1.4x | Com OP, o disco dura 3x mais tempo. |
| Consistência | Dente de serra (Sobe e desce) | Linha reta | Previsibilidade é a chave para SLAs. |
| Custo por GB Útil | Baixo (mas lento) | Alto (mas rápido) | Você paga pela velocidade, não pelo espaço. |
O veredito do datacenter
A indústria de armazenamento adora vender terabytes. É fácil colocar "4TB" em um panfleto. É difícil explicar "3.2TB de performance sustentada".
Se você gerencia servidores, pare de tratar SSDs como baldes passivos de bits. Eles são sistemas computacionais complexos que precisam de ar para respirar. Aquele espaço "livre" que você vê no df -h não é desperdício; é a garantia de que o Garbage Collection pode trabalhar em paz sem sequestrar a latência da sua aplicação.
Na próxima vez que provisionar um servidor, faça um favor ao seu "eu" do futuro: corte a partição. Jogue fora esses 20%. Se o financeiro reclamar, mostre a eles o gráfico de latência do mês passado. A física não negocia, e o controlador do seu SSD também não.
Referências & Leitura Complementar
SNIA (Storage Networking Industry Association): "Solid State Drive (SSD) Performance Test Specification" (PTS) – O padrão ouro para testar performance real vs. estado fresco.
Micron Technical Brief: "SSD Over-provisioning and Its Benefits" – Dados técnicos detalhados sobre a relação entre OP e WAF.
Seagate/Nytro: "Understanding SSD Over-provisioning" – Análise de impacto em drives enterprise.
RFC 793: (Apenas para lembrar que latência de rede também importa, mas hoje a culpa é do disco).
Perguntas Frequentes (FAQ)
O over-provisioning de fábrica não é suficiente?
Geralmente não. A maioria dos drives de consumo ou "read-intensive" vem com apenas 7% de OP, o que é insuficiente para cargas de escrita pesada e sustentada, resultando em alta amplificação de escrita e latência imprevisível.Como o over-provisioning afeta a vida útil do SSD?
Ele aumenta drasticamente a vida útil (TBW) ao reduzir a Amplificação de Escrita (WAF). O controlador precisa mover menos dados internamente para liberar blocos, desgastando menos as células NAND a cada ciclo de escrita.Posso aplicar over-provisioning em um disco já cheio?
Tecnicamente sim, redimensionando a partição ou namespace, mas o controlador só recuperará a performance total após um ciclo completo de Garbage Collection ou um comando TRIM massivo. O ideal é fazer um Secure Erase e configurar do zero.
Roberto Uchoa
Sysadmin Veterano (Anti-Hype)
"Sobrevivente da bolha pontocom e do hype do Kubernetes. Troco qualquer arquitetura de microsserviços 'inovadora' por um script bash que funciona sem falhas há 15 anos. Uptime não é opcional."