O mistério dos milissegundos perdidos: rastreando latência de I/O com eBPF

Descubra como médias escondem a verdade sobre seu storage. Aprenda a usar eBPF e OpenTelemetry para expor latência de cauda no nível do kernel Linux.
O silêncio nos seus dashboards de monitoramento é, muitas vezes, o som mais perigoso que existe. Seus gráficos de CPU estão estáveis, a memória tem folga e o throughput de disco parece constante. No entanto, seus usuários reclamam de lentidão intermitente, timeouts aleatórios e uma experiência degradada.
Bem-vindo ao mundo da latência de cauda (tail latency) em sistemas de armazenamento. O problema não é o que você vê; é o que suas ferramentas tradicionais de médias agregadas estão escondendo de você.
Resumo em 30 segundos
- Médias mentem: Ferramentas como
iostatou métricas de nuvem com granularidade de 1 minuto achatam picos de latência de milissegundos que destroem a performance de bancos de dados.- O Kernel sabe tudo: A latência real de I/O acontece nas camadas profundas do kernel (Block Layer, Driver NVMe), invisíveis para métricas de espaço de usuário padrão.
- eBPF é a resposta: Usar Extended Berkeley Packet Filter permite interceptar cada operação de disco individualmente, com overhead quase nulo, transformando "o disco está lento" em "o setor X demorou 500ms".
Quando o dashboard mente: a invisibilidade dos picos
Nós fomos condicionados a olhar para médias. "A latência média do disco é 2ms". Isso soa ótimo para um SSD Enterprise ou um volume EBS gp3. Mas em sistemas distribuídos e bancos de dados de alta performance, a média é uma métrica de vaidade.
Imagine um drive NVMe capaz de 100.000 IOPS. Se você monitora isso a cada 1 segundo (o padrão do iostat), você está tirando uma média de 100.000 eventos. Se 99.000 requisições levam 0.1ms, mas 1.000 requisições levam 500ms (devido a uma coleta de lixo no firmware do SSD ou contenção de fila), sua média ainda parecerá excelente.
No entanto, para as 1.000 threads de aplicação que ficaram presas esperando meio segundo pelo disco, o sistema parou. Isso é latência de cauda. E é aqui que a observabilidade real começa.
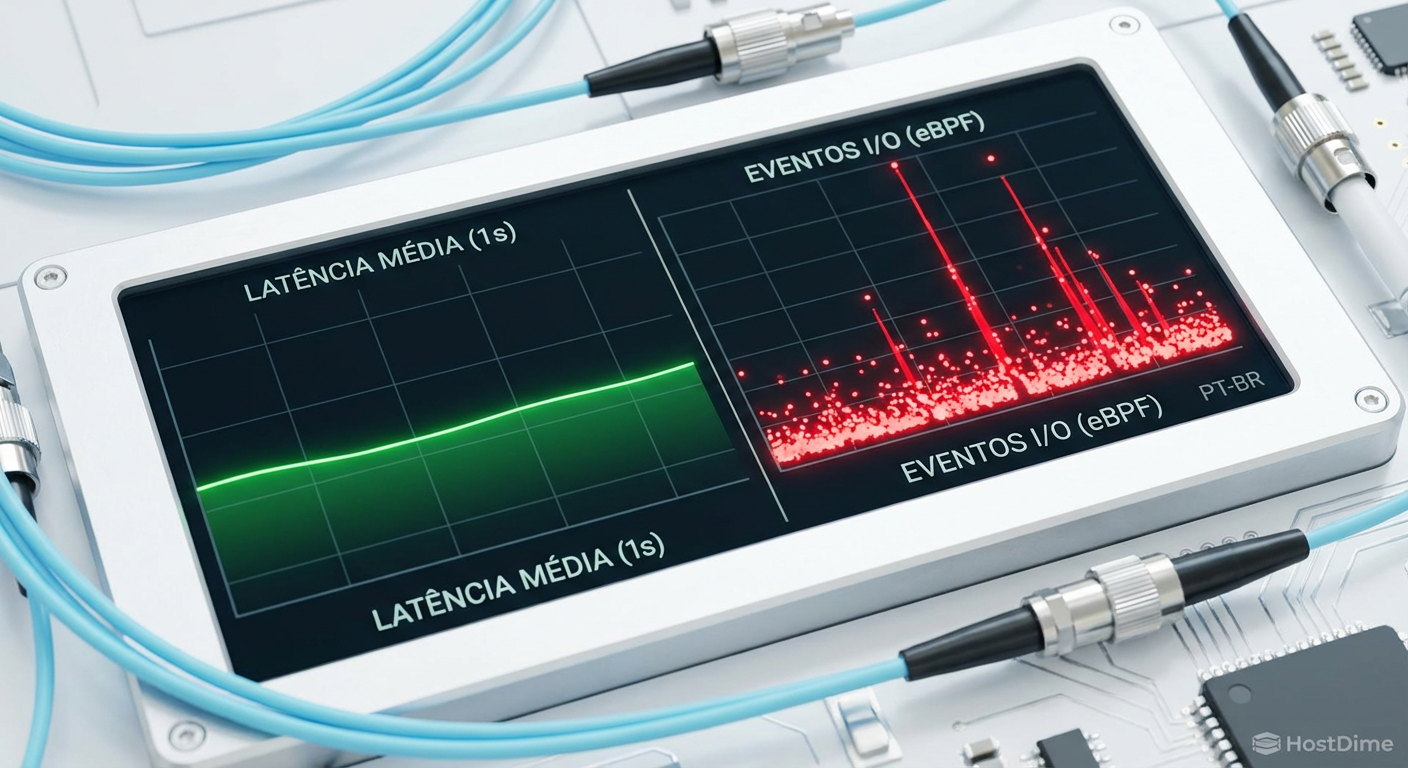 Figura: Comparativo visual entre a ilusão da média e a realidade dos eventos individuais de I/O.
Figura: Comparativo visual entre a ilusão da média e a realidade dos eventos individuais de I/O.
A anatomia de uma operação de I/O
Para entender onde os milissegundos se perdem, precisamos descer ao porão do sistema operacional. Quando seu banco de dados (Postgres, MySQL, Cassandra) pede para ler um bloco, a jornada é longa e cheia de perigos.
VFS (Virtual File System): A chamada de sistema entra.
Page Cache: O kernel verifica se o dado já está na RAM. Se não, descemos.
Block Layer: Aqui a mágica e o caos acontecem. O I/O é enfileirado, fundido (merged) ou reordenado pelo scheduler.
Driver (NVMe/SCSI): O pedido é formatado para o protocolo do hardware.
Dispositivo Físico: O controlador do SSD recebe o comando, traduz endereços lógicos para físicos (FTL), lida com wear leveling e finalmente lê a célula NAND.
Ferramentas tradicionais olham apenas para o início e o fim dessa cadeia de forma agregada. Com eBPF, podemos colocar "sondas" (probes) em cada uma dessas etapas.
💡 Dica Pro: Em ambientes virtualizados (VMware, KVM, EC2), a camada de "Driver" do seu sistema operacional convidado é apenas o começo. A latência pode estar no hypervisor ou na rede de armazenamento (SAN/Ceph) abaixo dele. O eBPF no guest OS mostrará isso como "tempo de dispositivo" alto.
Interceptando a stack com eBPF
O eBPF (Extended Berkeley Packet Filter) permite rodar programas em sandbox dentro do kernel do Linux de forma segura e performática. Para engenharia de storage, isso é revolucionário. Não precisamos mais adivinhar se a lentidão é fila de software ou resposta do disco.
Podemos atrelar programas eBPF a tracepoints estáticos ou kprobes dinâmicos.
Pontos de instrumentação críticos:
block_rq_issue: O momento exato que o pedido é enviado ao driver do dispositivo.block_rq_complete: O momento que o dispositivo confirma que terminou.nvme_setup_cmd: Específico para entender a latência de preparação do comando NVMe.
Ao calcular o delta de tempo entre issue e complete, obtemos a latência real vista pelo hardware, isolando o tempo que o I/O passou na fila do scheduler do OS.
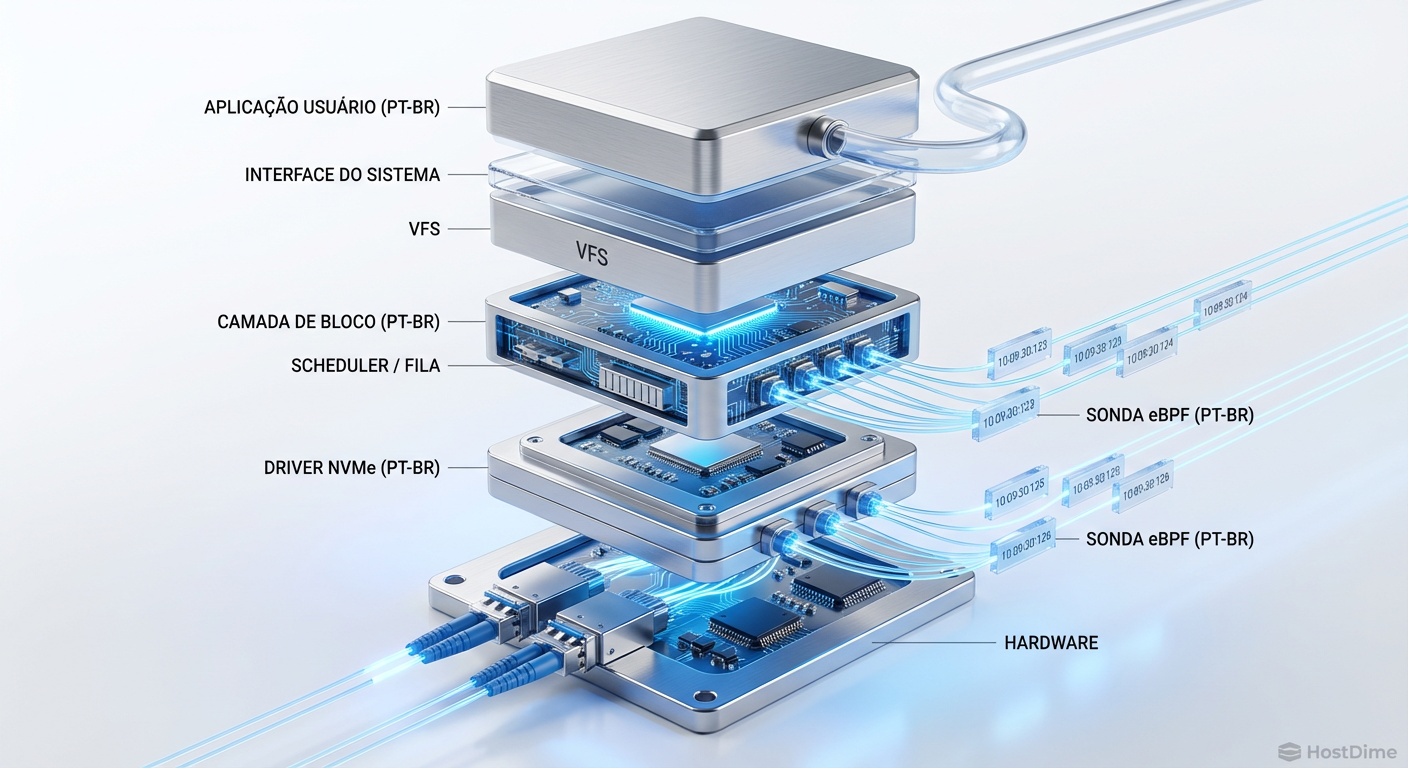 Figura: Diagrama da stack de I/O do Linux destacando os pontos de inserção das sondas eBPF.
Figura: Diagrama da stack de I/O do Linux destacando os pontos de inserção das sondas eBPF.
Comparativo: Ferramentas Legadas vs. Observabilidade Moderna
A diferença entre monitoramento (o sistema está saudável?) e observabilidade (por que o sistema está estranho?) fica clara na comparação abaixo:
| Característica | Ferramentas Tradicionais (iostat, sar) | Observabilidade com eBPF (bcc, bpftrace) |
|---|---|---|
| Resolução | Médias por segundo (amostragem) | Evento a evento (captura total ou histograma) |
| Contexto | Apenas dispositivo (ex: nvme0n1) |
Processo, PID, Latência, Tipo de I/O, Tamanho |
| Overhead | Baixo | Baixo (graças à agregação em kernel-space) |
| Visibilidade | Caixa preta (Input -> Output) | Raio-X (Tempo em fila vs. Tempo em dispositivo) |
| Diagnóstico | "O disco está lento" | "O processo X causou latência no setor Y" |
Transformando histogramas em traces distribuídos
Aqui é onde a mágica acontece para quem vive de SRE. Saber que o disco está lento é útil. Saber qual requisição de usuário sofreu com isso é transformador.
Ferramentas modernas permitem exportar métricas de eBPF diretamente para formatos compatíveis com OpenTelemetry. Em vez de apenas um gráfico de linha, você pode gerar Heatmaps (Mapas de Calor).
Um heatmap de latência mostra a distribuição dos I/Os ao longo do tempo. Você verá uma banda grossa na parte inferior (seus I/Os rápidos de 100us) e, ocasionalmente, pontos ou linhas na parte superior (seus outliers de 50ms).
⚠️ Perigo: Cuidado com a cardinalidade ao exportar dados de eBPF para seu backend de observabilidade. Não tente exportar cada evento de I/O individualmente se você tem 500k IOPS. Use histogramas agregados no kernel e exporte os buckets para o Prometheus ou Honeycomb.
O poder da correlação
Imagine um trace distribuído de uma API lenta. O span da aplicação mostra 2 segundos de duração. Normalmente, você veria um buraco negro chamado "Database Call".
Com eBPF correlacionado, podemos anexar metadados ao trace. Se o kernel detectou que, durante aquele período, o dispositivo /dev/nvme0n1 teve um pico de latência de fila, você correlaciona a causa raiz infraestrutural com o sintoma da aplicação.
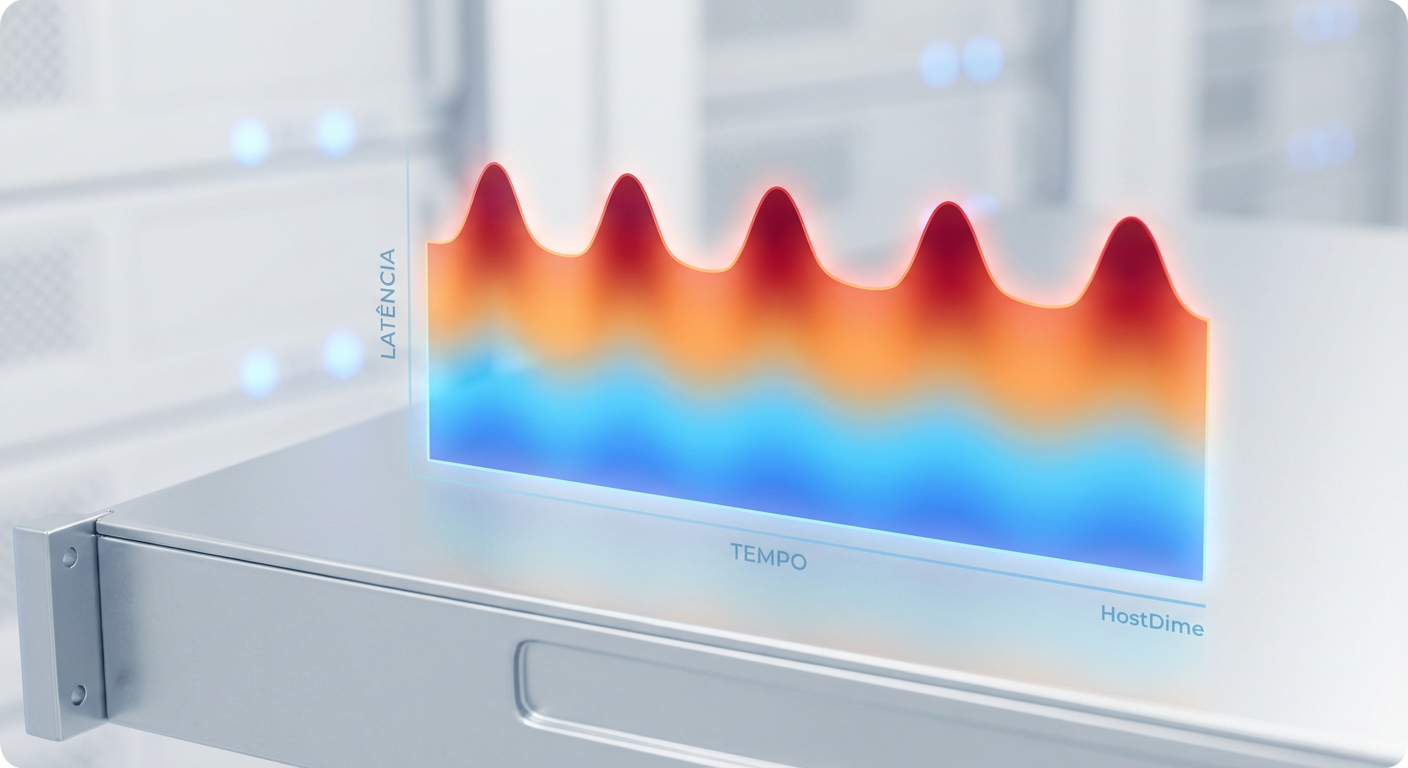 Figura: Mapa de calor (Heatmap) revelando padrões de latência de cauda invisíveis em gráficos lineares.
Figura: Mapa de calor (Heatmap) revelando padrões de latência de cauda invisíveis em gráficos lineares.
O fim da era das médias
Não estamos mais em 2010. Discos mecânicos mascaravam muitas ineficiências de software. Hoje, com SSDs NVMe Gen4 e Gen5 entregando latências na casa dos microssegundos, o sistema operacional e a estratégia de observabilidade tornaram-se o gargalo.
Se você gerencia bancos de dados, clusters Kubernetes com armazenamento persistente ou sistemas de arquivos distribuídos como Ceph, você não pode se dar ao luxo de ser cego aos outliers. A latência de cauda é onde seus usuários vivem a frustração.
Adotar eBPF não é apenas sobre usar uma ferramenta nova; é sobre mudar a mentalidade de "o sistema está funcionando?" para "como o sistema está se comportando para cada requisição?". Pare de olhar para as médias. Elas são o refúgio de quem não quer ver a verdade.
Referências & Leitura Complementar
eBPF Documentation: ebpf.io - A fonte autoritativa sobre a tecnologia.
NVMe Specification: NVM Express Base Specification - Para entender os comandos e filas reais.
Brendan Gregg's Blog: Referência mundial em performance e eBPF, criador das ferramentas do pacote BCC.
Linux Kernel Block Layer Documentation: kernel.org - Detalhes sobre schedulers e bio structures.
Perguntas Frequentes (FAQ)
Por que o iostat não mostra meus picos de latência?
O iostat trabalha com médias amostrais (geralmente intervalos de 1 segundo). Um pico de latência de 500ms que ocorre em apenas 1% das requisições é matematicamente diluído na média, fazendo o disco parecer rápido quando, na verdade, ele está travando requisições críticas.Qual o overhead de rodar eBPF em produção para storage?
Mínimo. O eBPF roda no kernel e usa mapas eficientes (eBPF maps) para agregação de dados antes de enviá-los ao espaço do usuário. Técnicas modernas (pós-2024) utilizam timestamps nativos da 'struct request' do kernel para reduzir ainda mais o custo de CPU, tornando-o seguro até para ambientes de alta carga.Como o OpenTelemetry ajuda na análise de disco local?
Ele não analisa apenas o disco local isoladamente; ele permite correlacionar a latência do disco (como um span filho ou atributo) com a requisição da aplicação (span pai). Isso permite que você veja exatamente qual query SQL ou chamada de API causou o I/O lento, unindo infraestrutura e aplicação.
Lucas Ferreira
Engenheiro de Observabilidade
"Transformo o caos de logs, métricas e traces em clareza operacional. Minha missão é eliminar pontos cegos e garantir que nada permaneça invisível na infraestrutura."