O paradoxo da densidade: discos de 30TB, SLAs de restore e a necessidade crítica dos multi-atuadores
Análise técnica sobre como a alta densidade de HDDs (30TB+) cria janelas de reconstrução insustentáveis e por que a tecnologia de duplo atuador é a única saída para manter o RTO.
O aumento vertiginoso da densidade de área nos discos rígidos (HDD) trouxe um benefício econômico inegável: o custo por terabyte nunca foi tão baixo. Com a chegada das unidades de 30TB e além, impulsionadas por tecnologias como HAMR (Heat-Assisted Magnetic Recording) e MAMR (Microwave-Assisted Magnetic Recording), data centers podem armazenar exabytes em um espaço físico reduzido. No entanto, como arquitetos de dados, precisamos encarar a física implacável que acompanha esse avanço.
Existe uma divergência crítica entre capacidade e performance. Enquanto a capacidade dos discos dobra a cada poucos anos, a velocidade mecânica de rotação (7200 RPM) e o tempo de busca do braço atuador permanecem estagnados há mais de uma década. Isso cria o que chamamos de "Paradoxo da Densidade": quanto maior o disco, menor a performance por terabyte e, mais perigosamente, maior o tempo necessário para recuperar dados após uma falha.
Resumo em 30 segundos
- A armadilha da reconstrução: Restaurar um array RAID com discos de 30TB usando tecnologias convencionais pode levar dias ou semanas, expondo o sistema a uma perda catastrófica de dados durante a janela de vulnerabilidade.
- Diluição de IOPS: A performance de acesso aleatório (IOPS) não cresce com a capacidade. Discos ultra-densos sem múltiplos atuadores tornam-se gargalos, onde os dados existem mas não podem ser acessados rápido o suficiente (dados "frios" forçados).
- A solução física: A tecnologia de múltiplos atuadores (Multi-Actuator) é a única resposta de hardware viável para manter o equilíbrio de IOPS/TB e reduzir janelas de reconstrução em HDDs de hiperescala.
A matemática do desastre: janelas de reconstrução
A métrica mais negligenciada em projetos de armazenamento de alta densidade é o MTTR (Mean Time to Repair ou Tempo Médio de Reparo). Em um cenário tradicional de RAID 5 ou 6, a reconstrução de um disco falho exige a leitura completa dos discos restantes para recalcular a paridade.
Considere um disco de 30TB. Em um cenário otimista, onde o disco sustenta uma taxa de transferência sequencial contínua de 270 MB/s (o que raramente acontece durante uma reconstrução, pois o disco também está servindo I/O de produção), a matemática é fria:
$$ \frac{30.000.000 \text{ MB}}{270 \text{ MB/s}} \approx 111.111 \text{ segundos} \approx 30,8 \text{ horas} $$
Isso é o cenário ideal, de laboratório. No mundo real, com a contenção de I/O de produção e a natureza aleatória das solicitações, esse tempo facilmente triplica ou quadruplica. Estamos falando de 4 a 6 dias para reconstruir um único drive.
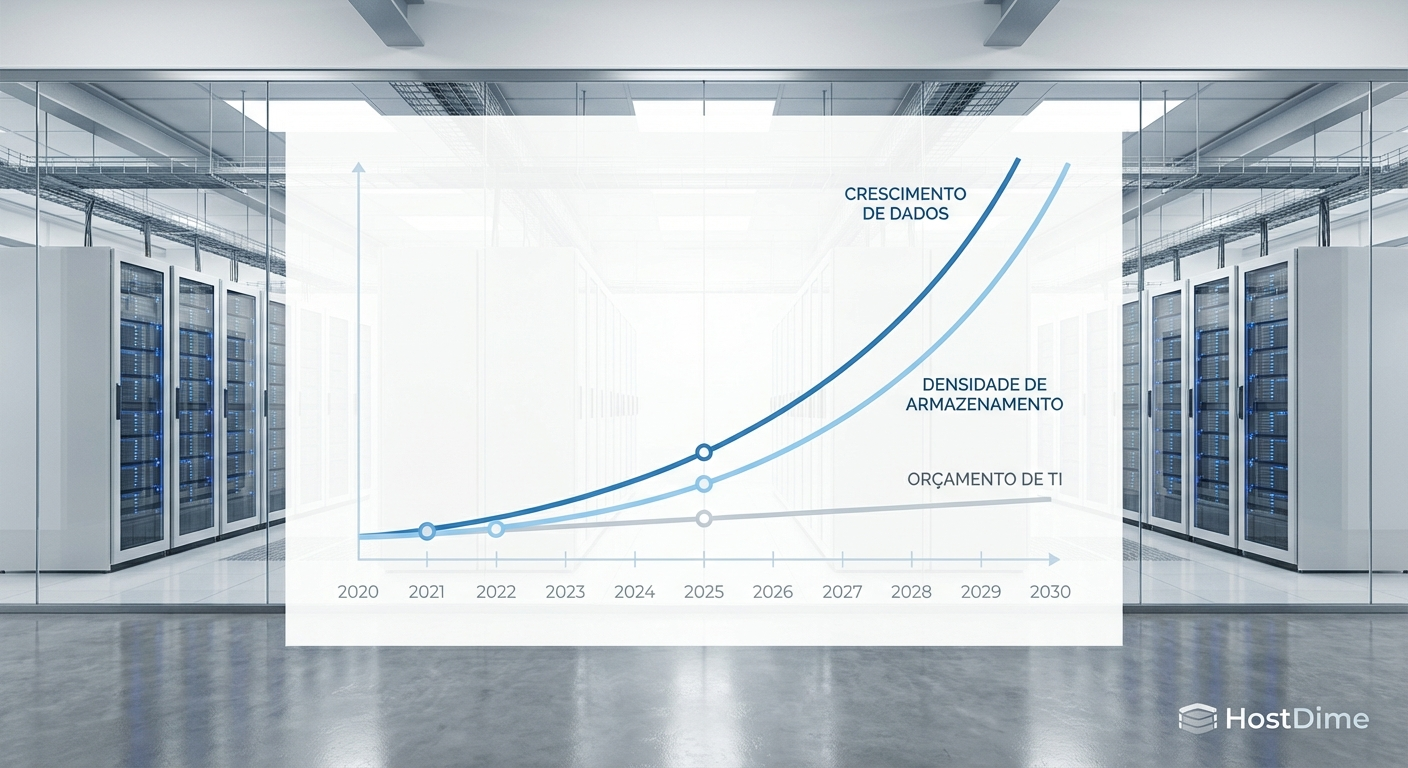
 Figura: Gráfico ilustrando o abismo crescente entre a capacidade de armazenamento e a velocidade de transferência, destacando a zona de risco operacional.
Figura: Gráfico ilustrando o abismo crescente entre a capacidade de armazenamento e a velocidade de transferência, destacando a zona de risco operacional.
⚠️ Perigo: Durante uma reconstrução de 100 horas, os discos restantes estão sob estresse mecânico máximo (leitura 100%). A probabilidade de um segundo disco falhar ou de ocorrer um erro de leitura irrecuperável (URE - Unrecoverable Read Error) aumenta exponencialmente. Se você usa RAID 5 com discos de 30TB, seus dados já estão estatisticamente comprometidos.
O colapso do IOPS por Terabyte
Para manter um SLA (Acordo de Nível de Serviço) saudável, geralmente buscamos uma certa quantidade de IOPS para cada TB de dados armazenados. Se um disco de 4TB entregava 80 IOPS aleatórios, tínhamos 20 IOPS/TB.
Um disco de 30TB com um único atuador ainda entrega os mesmos ~80 IOPS (limitados pela física da rotação e busca). O resultado é uma densidade de performance de 2,6 IOPS/TB.
Isso transforma o storage em um "cemitério de dados": você tem o espaço para guardar a informação, mas não tem a largura de banda mecânica para acessá-la em tempo hábil. Aplicações sensíveis à latência começam a falhar, e o tempo de ingest (gravação) de backups começa a estourar as janelas noturnas.
A resposta da engenharia: Tecnologia Multi-Atuador
Para resolver esse problema físico, a indústria (liderada por Seagate com a tecnologia MACH.2 e Western Digital) introduziu os discos com múltiplos atuadores. A premissa é dividir a tarefa de busca e transferência.
Em um drive convencional, todos os braços de leitura/gravação movem-se em uníssono, alinhados verticalmente. Em um drive de duplo atuador, o conjunto de braços é dividido em dois grupos independentes. Enquanto o grupo superior lê dados na borda externa do prato, o grupo inferior pode estar gravando dados na trilha interna simultaneamente.
 Figura: Corte técnico de um HDD com tecnologia de duplo atuador, demonstrando a movimentação independente dos braços superior e inferior sobre os pratos magnéticos.
Figura: Corte técnico de um HDD com tecnologia de duplo atuador, demonstrando a movimentação independente dos braços superior e inferior sobre os pratos magnéticos.
Isso efetivamente dobra o throughput sequencial (chegando a >500 MB/s) e dobra os IOPS aleatórios (para ~160 IOPS). Embora não transforme um HDD em um SSD, restaura o equilíbrio de IOPS/TB para níveis aceitáveis, similares aos discos de 10TB ou 12TB de gerações passadas.
Desafios de implementação lógica
A adoção de multi-atuadores não é "plug-and-play" para todos os sistemas. A forma como o sistema operacional enxerga esse dispositivo varia:
SAS Dual LUN: A implementação mais comum em Enterprise. O drive se apresenta ao host (controladora ou OS) como dois dispositivos lógicos (LUN 0 e LUN 1). Um disco físico de 30TB aparece como dois volumes de 15TB.
SATA: Devido às limitações do protocolo, implementações SATA são mais complexas e muitas vezes exigem que o drive gerencie o fluxo internamente ou apresente um único volume, o que pode mascarar os benefícios de performance se o enfileiramento de comandos não for otimizado.
💡 Dica Pro: Para extrair valor real de discos Dual Actuator, seu sistema de arquivos (ZFS, Ceph, Btrfs) ou software de SDS (Software-Defined Storage) deve estar ciente da topologia. Ele precisa paralelizar as gravações entre os dois LUNs lógicos do mesmo drive físico para obter o dobro de velocidade.
Mitigação avançada: Declustered RAID e Erasure Coding
Mesmo com atuadores duplos, o RAID tradicional (baseado em grupos fixos de discos) é insuficiente para capacidades de 30TB. A indústria está migrando massivamente para o Declustered RAID (dRAID).
No dRAID, não existem "grupos de paridade" fixos. Os dados e a paridade são pulverizados em todos os discos do chassi. Se você tem um pool de 100 discos e um falha:
A reconstrução não é feita por apenas 5 ou 6 discos sobreviventes.
Todos os 99 discos restantes participam da leitura e escrita dos dados reconstruídos.
A performance de reconstrução é multiplicada pelo número de discos no pool.
Combinando Discos de 30TB Multi-Atuador com dRAID, podemos reduzir o tempo de reconstrução de dias para horas, mantendo a integridade dos dados e o SLA.
 Figura: Comparativo visual entre a reconstrução de RAID Tradicional (alto estresse em poucos discos) e Declustered RAID (carga distribuída entre dezenas de discos).
Figura: Comparativo visual entre a reconstrução de RAID Tradicional (alto estresse em poucos discos) e Declustered RAID (carga distribuída entre dezenas de discos).
Comparativo de Tecnologias de Armazenamento Massivo
Para situar onde o multi-atuador se encaixa no seu datacenter, analisamos as métricas chave:
| Característica | HDD Single Actuator (30TB) | HDD Dual Actuator (30TB) | QLC Enterprise SSD (30TB) |
|---|---|---|---|
| Custo por TB | Baixo (Referência) | Baixo (Marginalmente superior) | Alto (5x - 10x) |
| Throughput Seq. | ~270 MB/s | ~550 MB/s | >3.000 MB/s |
| IOPS Aleatório | ~80 | ~160 | >100.000 |
| IOPS / TB | Crítico (<3) | Aceitável (~5-6) | Excelente |
| Tempo de Rebuild | Crítico (Dias) | Melhorado (Metade do tempo) | Muito Rápido |
| Caso de Uso | Cold Archive, Backup | Object Storage, Big Data, CDN | Hot Data, DBs, AI Training |
O imperativo da arquitetura moderna
A era dos discos de ultra capacidade exige uma reformulação da estratégia de proteção de dados. Não podemos mais tratar um disco de 30TB como tratávamos um de 4TB. A densidade sem performance é um risco operacional.
A recomendação para arquitetos de infraestrutura é clara: ao planejar a introdução de drives acima de 20TB, a tecnologia de múltiplos atuadores deixa de ser um luxo e torna-se um requisito funcional para manter janelas de recuperação viáveis. Além disso, o abandono de níveis de RAID tradicionais em favor de Erasure Coding ou Declustered RAID é mandatório para garantir que a economia no custo por terabyte não seja cobrada com juros na forma de perda de dados.
Referências & Leitura Complementar
Seagate: "Mach.2 Multi-Actuator Technology: The Solution for Performance Scaling" (Technical Paper).
SNIA (Storage Networking Industry Association): "Hyperscaler Storage Trends and the Impact on Data Protection".
Western Digital: "Ultrastar DC HS760 Data Sheet - Dual Actuator Hard Drive".
USENIX FAST: "Declustered RAID: Reducing Rebuild Time and Risk in Large Storage Systems".
Perguntas Frequentes (FAQ)
Por que discos de 30TB aumentam o risco de perda de dados mesmo em RAID?
O aumento da capacidade sem o aumento proporcional da velocidade de transferência estende o tempo de reconstrução (rebuild) para dias ou semanas. Durante esse período vulnerável, a probabilidade de uma segunda falha mecânica ou erro de leitura irrecuperável (URE) aumenta drasticamente, podendo levar à perda total do array.Como a tecnologia multi-atuador resolve o problema de performance em HDDs de alta densidade?
Ao dividir os braços atuadores em dois conjuntos independentes que podem ler e escrever simultaneamente, a tecnologia dobra efetivamente o throughput e os IOPS do disco. Isso mantém a métrica de 'IOPS por TB' equilibrada, permitindo que tempos de reconstrução e latências de acesso permaneçam dentro dos SLAs aceitáveis.O sistema operacional vê um disco multi-atuador como um ou dois volumes?
Depende da implementação. Em muitos casos (como SAS Dual LUN), o host enxerga dois dispositivos lógicos independentes (LUNs) dentro do mesmo chassi físico. Isso exige que o software de storage ou sistema de arquivos gerencie o balanceamento de carga e o endereçamento para aproveitar o paralelismo.
Mariana Costa
Arquiteto de Proteção de Dados
"Transformo conformidade e segurança em estratégia. Desenho arquiteturas que protegem a integridade do dado em cada etapa do seu ciclo de vida, unindo privacidade e resiliência cibernética."