O perigo oculto do block cloning: fragmentação de metadados no XFS e ReFS contra o RTO

O block cloning acelera backups, mas a fragmentação de metadados no XFS e ReFS pode destruir seu RTO na hora do restore. Entenda a anatomia deste problema.
O mundo da proteção de dados vive uma epidemia de otimismo perigoso. Administradores de infraestrutura olham para seus painéis de controle, veem rotinas de backup concluídas em minutos e vão dormir tranquilos. Eles acreditam que a tecnologia de block cloning resolveu o problema da janela de backup para sempre. Mas eu repito este mantra há décadas: backup não existe, só o restore importa.
Quando o desastre atinge seu datacenter e você precisa recuperar terabytes de máquinas virtuais críticas, a realidade bate à porta. Aquele repositório de backup super rápido pode se transformar no seu pior pesadelo. O motivo é um inimigo silencioso que destrói o seu RTO (Recovery Time Objective): a fragmentação severa de metadados em sistemas de arquivos modernos.
Resumo em 30 segundos
- O block cloning acelera backups criando ponteiros em vez de copiar dados, mas gera uma teia complexa de metadados no storage.
- Durante um restore massivo, a leitura desses ponteiros fragmentados no ReFS ou XFS causa um gargalo brutal de I/O (operações de entrada e saída).
- A única defesa real contra a falha de RTO no repositório primário é a aplicação rigorosa da regra 3-2-1 com mídias independentes.
A ilusão do backup rápido e o choque da latência no restore
Sistemas de arquivos avançados trouxeram recursos incríveis para o armazenamento corporativo. O block cloning, conhecido em algumas plataformas como Fast Clone, permite que arquivos compartilhem os mesmos blocos físicos no disco. Se você tem um backup completo e faz uma nova cópia sintética, o storage não grava os dados novamente. Ele apenas cria ponteiros de metadados referenciando os blocos originais.
Isso economiza uma quantidade absurda de espaço em disco e reduz o tempo de gravação para uma fração do original. O problema começa quando você entende a física por trás da leitura desses dados. Cada alteração diária nos seus backups cria novos ponteiros. Com o passar dos meses, um único arquivo de disco virtual (VMDK ou VHDX) pode estar espalhado por milhares de fragmentos lógicos.
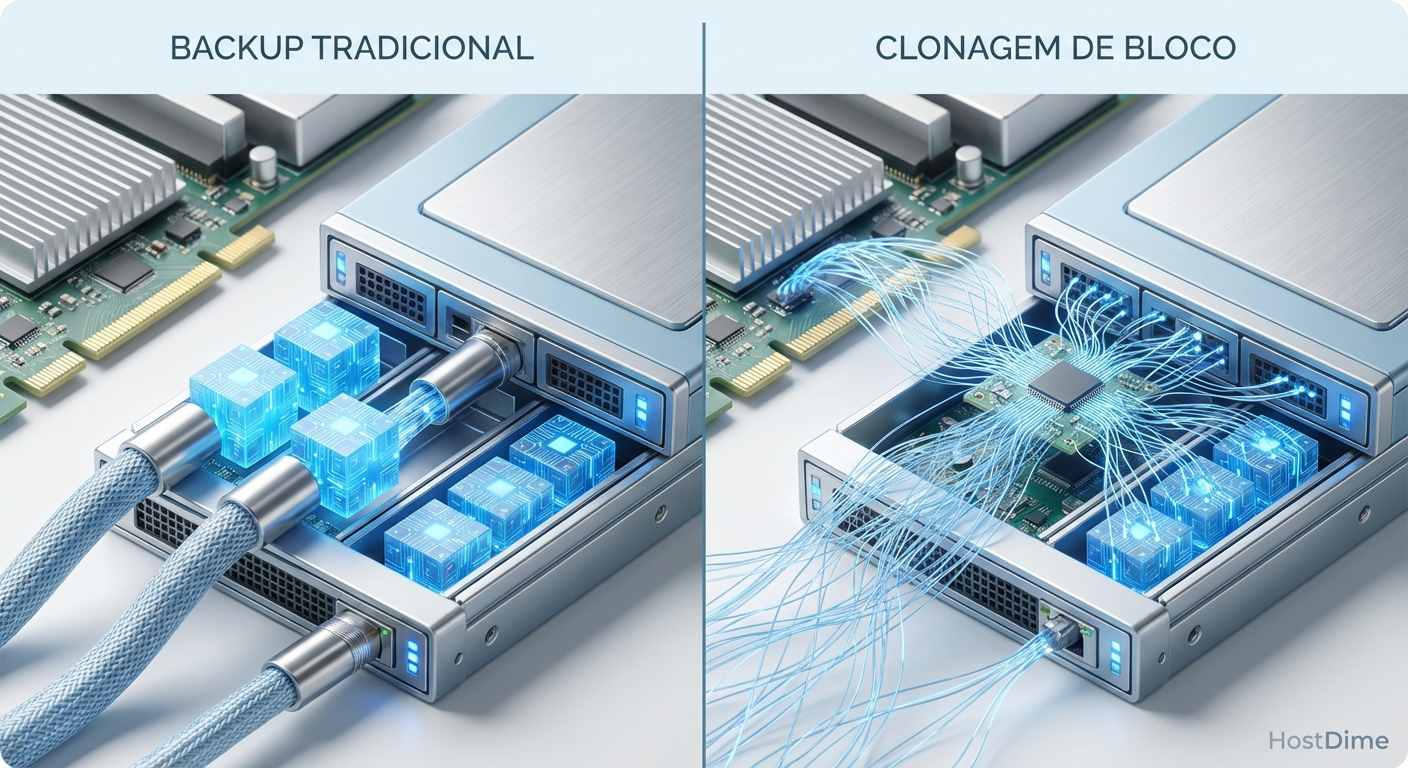 Figura: Diagrama conceitual mostrando a diferença de I/O entre um backup tradicional e o uso de block cloning com ponteiros de metadados
Figura: Diagrama conceitual mostrando a diferença de I/O entre um backup tradicional e o uso de block cloning com ponteiros de metadados
Na hora do restore, o sistema operacional precisa remontar esse quebra-cabeça. O que deveria ser uma leitura sequencial rápida se transforma em milhares de leituras aleatórias. Se o seu repositório for baseado em discos mecânicos (HDDs) de alta capacidade, a latência mecânica da cabeça de leitura vai destruir a performance. O seu RTO, que foi planejado para duas horas, pode facilmente se transformar em dois dias.
Como os ponteiros do ReFS e XFS criam um labirinto de I/O
No ecossistema de storage para proteção de dados, dois sistemas de arquivos dominam o uso de block cloning. No mundo Windows Server, temos o ReFS (Resilient File System). No universo Linux, o XFS com o recurso de reflink ativado é o padrão da indústria. Ambos são robustos, mas sofrem do mesmo mal arquitetural quando submetidos a cargas de trabalho de backup contínuo.
O ReFS utiliza uma estrutura de árvore B+ para gerenciar seus metadados. Quando o block cloning é usado intensamente, essa árvore cresce de forma desproporcional. O Windows precisa alocar muita memória RAM para mapear esses ponteiros. Se a RAM acabar, o sistema faz paginação no disco, e a performance de leitura despenca para níveis inutilizáveis.
O XFS gerencia a memória de forma um pouco mais eficiente através de sua arquitetura baseada em extents (grupos de blocos contíguos). No entanto, o recurso de reflink também fragmenta o arquivo no nível lógico. Quando o software de backup solicita a leitura de um bloco, o XFS precisa consultar sua própria árvore B+ interna para descobrir onde o dado real reside no disco físico.
| Característica | Microsoft ReFS | Linux XFS (com reflink) |
|---|---|---|
| Mecanismo de Clone | Block Cloning nativo | Reflink (Copy-on-Write) |
| Consumo de RAM | Muito alto em repositórios grandes | Moderado a alto |
| Estrutura de Metadados | Árvore B+ agressiva | Árvore B+ baseada em extents |
| Impacto no Restore | Alta latência se faltar RAM | Alta latência em discos mecânicos |
| Tamanho de Bloco Ideal | 64KB (Obrigatório para backup) | 4KB (Padrão) ou ajustado via stripe |
Por que desfragmentadores e expansão de volumes falham
A reação instintiva de qualquer administrador de sistemas ao ouvir a palavra "fragmentação" é rodar um utilitário de desfragmentação. No contexto de block cloning, isso é um erro fatal. Desfragmentadores tradicionais não entendem a estrutura de ponteiros compartilhados.
Se você tentar desfragmentar um volume ReFS ou XFS cheio de clones, o utilitário vai ler o arquivo lógico e gravá-lo novamente como blocos físicos independentes. O resultado? Você quebra o block cloning. O que antes ocupava 10 TB de espaço físico pode inflar instantaneamente para 50 TB, lotando seu storage e derrubando o ambiente inteiro.
 Figura: Representação visual da fragmentação severa de metadados, onde ponteiros precisam cruzar todo o disco para remontar um único arquivo
Figura: Representação visual da fragmentação severa de metadados, onde ponteiros precisam cruzar todo o disco para remontar um único arquivo
Outra tática comum é simplesmente adicionar mais discos ao array (expansão de volume) para diluir o I/O. Embora mais spindles (eixos de disco) forneçam mais IOPS brutos, eles não resolvem a latência de busca dos metadados. Você está apenas criando um labirinto maior para a controladora de storage percorrer. A raiz do problema permanece intacta.
Arquitetura de storage e dimensionamento para mitigar o caos
Para sobreviver a esse cenário, o design da infraestrutura de storage precisa ser intencional desde o dia zero. A primeira linha de defesa é o dimensionamento correto dos blocos do sistema de arquivos. Formatar um repositório de backup com o tamanho de bloco errado é assinar uma sentença de morte para o seu RTO.
⚠️ Perigo: Nunca formate um volume ReFS destinado a repositórios de backup com clusters de 4KB. Isso multiplica a quantidade de metadados gerados de forma exponencial. O padrão absoluto e inegociável para essa carga de trabalho é 64KB.
Além do tamanho do bloco, a arquitetura física do storage dita as regras do jogo. Se o orçamento permitir, o uso de arrays híbridos ou all-flash (SSDs/NVMe) mitiga drasticamente a penalidade da fragmentação. O NVMe (Non-Volatile Memory Express) elimina a latência mecânica, permitindo que o sistema leia milhares de ponteiros espalhados em microssegundos.
Se você precisa usar discos mecânicos por questões de custo por terabyte, considere controladoras de storage que suportam tiering de metadados. Algumas soluções corporativas permitem fixar a tabela de metadados do sistema de arquivos em um espelho de SSDs, enquanto os blocos de dados pesados ficam nos HDDs. Isso acelera a resolução dos ponteiros durante o restore.
Testando o RTO real e a salvação pela regra 3-2-1
A paranoia profissional exige que você não confie em planilhas teóricas. A única forma de saber se a fragmentação do seu XFS ou ReFS atingiu um nível crítico é realizando simulações de desastre reais. Você precisa iniciar um restore completo da sua VM mais pesada e monitorar a latência de leitura no nível do disco.
Se a latência de leitura ultrapassar a marca de 30 a 50 milissegundos de forma sustentada durante a recuperação, seu repositório está engasgando com os metadados. É neste momento de pânico que a arquitetura de proteção de dados separa os amadores dos profissionais. É aqui que a regra 3-2-1 salva o seu emprego.
 Figura: Arquitetura de proteção de dados baseada na regra 3-2-1, isolando o risco de fragmentação do repositório primário
Figura: Arquitetura de proteção de dados baseada na regra 3-2-1, isolando o risco de fragmentação do repositório primário
A regra 3-2-1 exige três cópias dos dados, em duas mídias diferentes, com uma cópia fora do site. Se o seu repositório primário local (baseado em block storage) falhar em entregar o RTO devido à fragmentação, você recorre à sua cópia secundária. Hoje, a melhor prática é que essa cópia resida em Object Storage (armazenamento de objetos) imutável.
O Object Storage não usa sistemas de arquivos tradicionais. Ele não sofre da mesma fragmentação de árvore B+ que o ReFS ou XFS. Quando você solicita um objeto, ele é entregue de forma íntegra. Ter essa via alternativa de recuperação garante que uma falha arquitetural no storage primário não resulte na perda definitiva do negócio.
O veredito da recuperação
A tecnologia de block cloning é um mal necessário. Sem ela, não conseguiríamos proteger os volumes massivos de dados gerados pelas empresas modernas dentro das janelas de backup disponíveis. No entanto, ignorar a dívida técnica que ela cria no seu storage é um erro amador.
Não confie cegamente na velocidade de gravação dos seus backups. Audite o consumo de memória dos seus servidores de repositório, monitore a latência de leitura dos seus discos e, acima de tudo, teste suas recuperações em escala. O verdadeiro teste de uma infraestrutura de storage não é o quão rápido ela ingere os dados, mas o quão rápido ela os devolve quando a sua empresa está sangrando dinheiro a cada minuto de inatividade.
Referências & leitura complementar
Microsoft Learn: Resilient File System (ReFS) overview and Block Cloning capabilities.
Red Hat Customer Portal: XFS File System documentation and reflink feature specifications.
SNIA (Storage Networking Industry Association): Dictionary of Storage Terms (Metadata, Extents, IOPS).
Veeam Help Center: Fast Clone requirements and limitations for Backup Repositories.
O que é block cloning e por que ele causa fragmentação?
O block cloning é uma técnica de storage que permite que arquivos compartilhem os mesmos blocos de dados físicos no disco. Isso economiza muito espaço e tempo de gravação durante os backups. A fragmentação acontece porque as alterações diárias criam uma teia complexa de ponteiros de metadados. Na hora da recuperação, o storage precisa dar múltiplos saltos de leitura mecânica ou de estado sólido para remontar o arquivo, destruindo a performance.O ReFS é pior que o XFS para fragmentação de metadados?
Ambos sofrem do mesmo mal arquitetural ao lidar com block cloning intensivo em repositórios de backup. O ReFS no Windows Server tem um histórico de consumo excessivo de RAM para mapear esses metadados em sua árvore B+. O XFS no Linux gerencia a memória de forma um pouco mais eficiente usando extents, mas a penalidade de latência de disco afeta ambos de forma severa durante um restore massivo.Como a regra 3-2-1 protege contra a fragmentação do repositório primário?
A regra 3-2-1 exige que você mantenha cópias em mídias e sistemas diferentes. Se o seu repositório primário baseado em ReFS ou XFS estiver severamente fragmentado e não conseguir entregar o tempo de recuperação exigido, você não fica sem opções. Uma cópia secundária em object storage imutável garante que os dados possam ser restaurados com performance previsível, ignorando completamente o gargalo do sistema de arquivos local.
Silvio Zimmerman
Operador de Backup & DR
"Vivo sob o lema de que backup não existe, apenas restore bem-sucedido. Minha religião é a regra 3-2-1 e meu hobby é desconfiar da integridade dos seus dados."