O playbook de contenção de ransomware em arrays SAN e isolamento de LUNs

Guia tático para comandantes de incidentes: aprenda a isolar LUNs, conter ataques de ransomware em redes SAN e restaurar serviços de storage crítico.
Um incidente de segurança na camada de armazenamento não é apenas uma violação de dados, é uma ameaça direta à continuidade dos negócios. Quando um ataque de ransomware ultrapassa as defesas do sistema operacional e atinge a infraestrutura de Storage Area Network (SAN), o tempo de resposta dita a diferença entre uma recuperação de duas horas e a perda total do datacenter.
Como comandantes de incidentes, nossa prioridade durante um evento de criptografia em massa é a contenção imediata. A malha de armazenamento exige um playbook específico, focado em isolar as Logical Unit Numbers (LUNs) comprometidas sem causar uma interrupção em cascata nos clusters de hypervisors saudáveis.
Resumo em 30 segundos
- A criptografia em nível de bloco destrói a integridade de datastores inteiros, ignorando permissões de arquivos do sistema operacional convidado.
- Snapshots tradicionais são vulneráveis à escalada de privilégios e exclusão em massa por atacantes com acesso administrativo ao array.
- A contenção eficaz exige o isolamento cirúrgico via zoneamento Fibre Channel ou desativação de targets iSCSI, preservando hosts não infectados.
A anatomia do ataque na camada de bloco
Atores de ameaças modernos não se limitam a criptografar arquivos dentro de uma máquina virtual. O vetor de ataque evoluiu para a infraestrutura subjacente. A escalada de privilégios visa as interfaces de gerenciamento dos arrays SAN ou os próprios hosts de virtualização.
Uma vez que o atacante compromete um host conectado à malha Fibre Channel (FC) ou iSCSI, ele ganha acesso direto aos blocos brutos de armazenamento. A partir desse ponto, o ransomware inicia operações de gravação maliciosas diretamente no volume compartilhado.
O impacto dessa ação é devastador para ambientes virtualizados. Datastores baseados em Virtual Machine File System (VMFS) ou Cluster Shared Volumes (CSV) dependem de metadados rigorosos para coordenar o acesso simultâneo de múltiplos hosts. A criptografia em nível de bloco corrompe esses metadados instantaneamente.
O resultado é a perda de acesso a dezenas ou centenas de máquinas virtuais de uma só vez. O hypervisor reporta falhas de I/O (Input/Output), os sistemas operacionais convidados travam em estado de pânico e os serviços críticos saem do ar. A propagação lateral ocorre na velocidade do barramento de armazenamento.
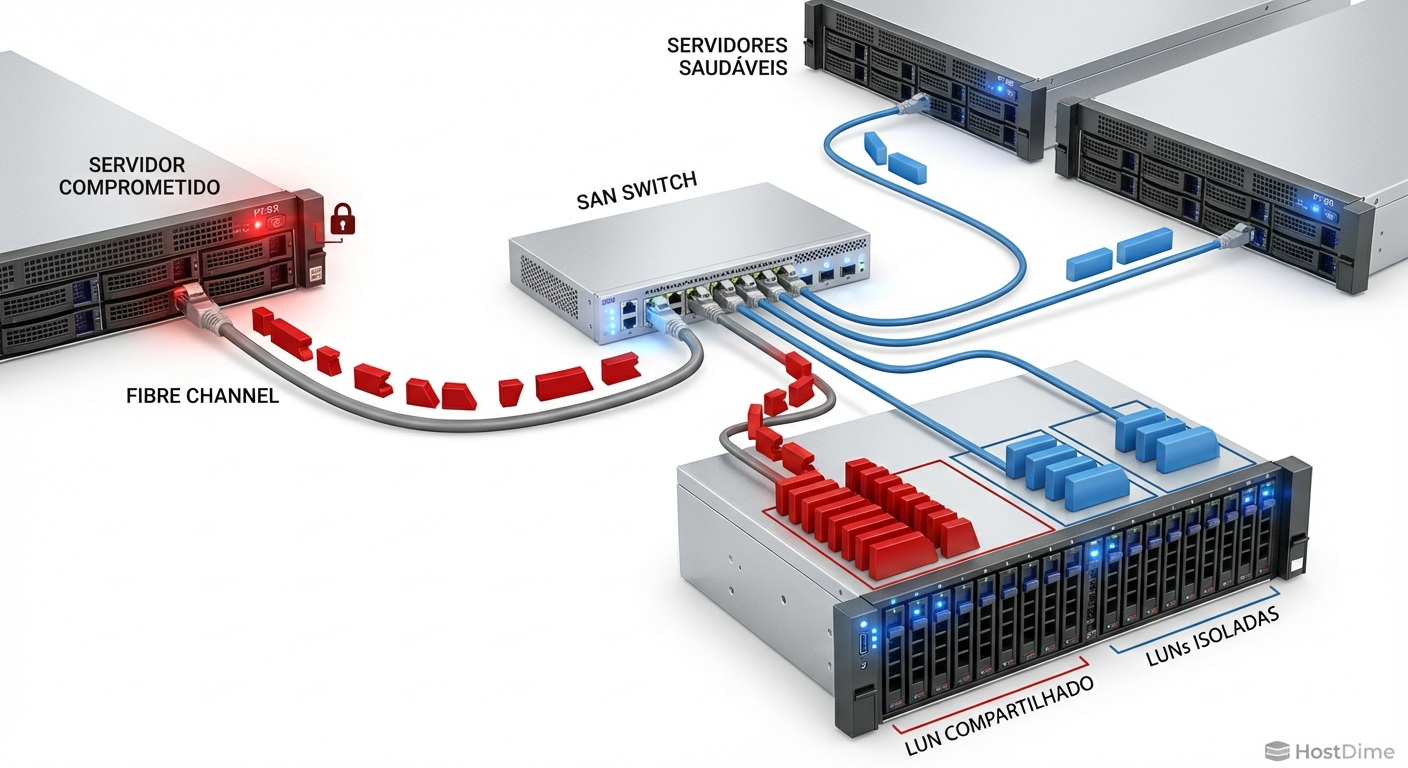 Figura: Diagrama ilustrando a propagação de I/O malicioso de um host comprometido para uma LUN compartilhada na malha Fibre Channel.
Figura: Diagrama ilustrando a propagação de I/O malicioso de um host comprometido para uma LUN compartilhada na malha Fibre Channel.
A falsa sensação de segurança dos snapshots in-band
Historicamente, as equipes de infraestrutura confiaram nos snapshots nativos do array SAN como a principal linha de defesa contra corrupção de dados. A premissa era simples: reverter a LUN para o estado de uma hora atrás e restaurar o serviço.
No entanto, essa estratégia falha miseravelmente contra ataques direcionados à infraestrutura. Snapshots in-band tradicionais são gerenciados pelo mesmo plano de controle que o atacante busca comprometer. Se as credenciais do administrador do storage forem vazadas, o jogo acaba.
O primeiro passo de um ransomware focado em storage, após o reconhecimento da rede, é emitir comandos via API ou interface de linha de comando (CLI) para expurgar todos os snapshots existentes. Sem os pontos de recuperação, a extorsão se torna muito mais eficaz.
⚠️ Perigo: Confiar apenas em snapshots tradicionais com permissões de leitura e gravação para a equipe de administração padrão é um risco crítico. Se o Active Directory for comprometido e o storage usar autenticação integrada, seus backups primários serão destruídos antes da criptografia começar.
Para entender a diferença de postura de segurança, precisamos avaliar como as tecnologias de proteção de dados evoluíram dentro dos arrays modernos.
| Característica | Snapshots Tradicionais | Snapshots Imutáveis (WORM) |
|---|---|---|
| Modificação | Podem ser deletados por admins | Bloqueados contra exclusão (Retention Lock) |
| Isolamento | Residem no mesmo domínio de falha | Podem ser replicados para um cofre lógico |
| Performance | Alta (Zero impacto no I/O) | Alta (Zero impacto no I/O) |
| Complexidade | Baixa (Nativo na maioria dos arrays) | Média (Exige planejamento de capacidade estrito) |
| Segurança | Baixa contra ataques de infraestrutura | Altíssima contra ransomware e ameaças internas |
Execução do playbook de contenção e isolamento
Quando os alertas de anomalia de I/O disparam, indicando picos massivos de gravação ou mudanças drásticas na taxa de desduplicação de um volume, o Comandante de Incidentes deve declarar estado de crise. A meta imediata é estancar a sangria.
O isolamento de LUNs não deve ser feito desligando o array SAN inteiro. Isso causaria um apagão de dados desnecessário para serviços não afetados. A contenção deve ser cirúrgica, operando nas camadas de rede de armazenamento e mascaramento de LUNs (LUN masking).
Passo 1: Identificação do host ofensor
Utilize as ferramentas de monitoramento de performance do storage para identificar qual World Wide Port Name (WWPN) no Fibre Channel, ou qual iSCSI Qualified Name (IQN), está gerando a carga de gravação anômala. O isolamento começa pelo bloqueio desse iniciador específico.
Passo 2: Corte de sessões na malha
Acesse o switch SAN (Brocade, Cisco MDS, etc.) e remova o host comprometido da zona (zoning) ativa. Em ambientes iSCSI, derrube as sessões TCP ativas e revogue as credenciais CHAP do host suspeito. Isso corta fisicamente ou logicamente o caminho de dados entre o servidor infectado e o storage.
Passo 3: Proteção da LUN no array
Imediatamente após o corte da sessão, acesse a gerência do array de storage. Altere o status da LUN afetada para "Read-Only" (Somente Leitura). Isso garante que, mesmo que o atacante encontre um caminho alternativo (multipathing), ele não conseguirá alterar mais nenhum bloco de dados.
💡 Dica Pro: Tenha scripts de automação pré-aprovados e testados para executar o isolamento de LUNs e a alteração de zoneamento. Durante um ataque, a pressão psicológica induz a erros de digitação na CLI que podem derrubar o cluster inteiro.
 Figura: Execução do playbook de contenção: identificação da anomalia de I/O e isolamento cirúrgico do host via CLI.
Figura: Execução do playbook de contenção: identificação da anomalia de I/O e isolamento cirúrgico do host via CLI.
Arquitetura de resiliência com air-gap lógico
A contenção é apenas a resposta reativa. A verdadeira engenharia de confiabilidade exige que a arquitetura do datacenter seja desenhada assumindo que a violação vai ocorrer. É aqui que entra o conceito de air-gap lógico e armazenamento imutável.
A tecnologia WORM (Write Once, Read Many) garante que, uma vez que os dados sejam gravados, eles não possam ser alterados ou excluídos por um período de retenção predefinido. Aplicar políticas WORM aos snapshots do array cria uma barreira intransponível para o ransomware.
Mesmo com credenciais de administrador máximo (root), o sistema operacional do storage (como o ONTAP, Purity ou PowerMaxOS) negará qualquer comando de exclusão do snapshot até que o relógio de retenção expire. Isso garante um ponto de recuperação limpo.
Para elevar a segurança, implementamos o air-gap lógico. Diferente da replicação síncrona tradicional, onde a corrupção no site principal é imediatamente replicada para o site de desastre, o air-gap lógico utiliza um array de cofre (vault) isolado.
O array de cofre permanece com suas portas de rede de dados desativadas a maior parte do tempo. Periodicamente, ele abre a conexão, "puxa" (pull) os dados alterados do storage principal, cria um snapshot imutável local e fecha a conexão novamente. O storage principal nunca tem permissão para "empurrar" (push) dados ou comandos para o cofre.
Recomendação de arquitetura para o próximo ciclo
A era de confiar implicitamente nas defesas de perímetro e nos sistemas operacionais acabou. A camada de armazenamento deve operar sob os princípios de Zero Trust. Avalie imediatamente a postura de segurança dos seus arrays SAN.
Se a sua infraestrutura atual permite que um único administrador exclua todos os volumes e snapshots sem um fluxo de aprovação de múltiplas pessoas (Quorum/Multi-Admin Verify), seu datacenter está operando com risco crítico aceito. A transição para arquiteturas com snapshots imutáveis e isolamento lógico não é mais um diferencial técnico, é um requisito básico de sobrevivência corporativa.
Referências & Leitura Complementar
NIST Special Publication 800-209: Security Guidelines for Storage Infrastructure. Documento fundamental sobre proteção de dados em nível de bloco e gerenciamento seguro de arrays.
SNIA (Storage Networking Industry Association): Dicionário oficial e especificações sobre arquiteturas WORM, Fibre Channel Zoning e segurança em redes de armazenamento.
RFC 3720: Internet Small Computer Systems Interface (iSCSI). Leitura técnica essencial para entender a mecânica de sessões e autenticação CHAP na camada de bloco.
Como isolar uma LUN comprometida sem derrubar o cluster inteiro?
O isolamento cirúrgico deve ser executado na camada de zoneamento (zoning) do switch Fibre Channel ou desativando o target iSCSI específico diretamente na interface de gerência do array SAN. Isso garante que os hosts não infectados mantenham acesso aos seus respectivos volumes.Snapshots tradicionais de storage são suficientes contra ransomware?
Não. Se o atacante obtiver credenciais administrativas do array SAN ou do hypervisor, ele pode emitir comandos para deletar todos os snapshots in-band antes de iniciar a criptografia. A defesa exige volumes WORM (Write Once, Read Many) ou snapshots imutáveis com bloqueio de retenção.Qual é o primeiro passo ao detectar atividade anômala de I/O em um volume de bloco?
O comandante do incidente deve imediatamente revogar o acesso de gravação (colocar a LUN em read-only) ou derrubar as portas do switch conectadas ao host suspeito, preservando o estado atual dos blocos para análise forense e evitando a propagação lateral.
Roberto Xavier
Comandante de Incidentes
"Lidero equipes em momentos críticos de infraestrutura. Priorizo a restauração rápida de serviços e promovo uma cultura de post-mortem sem culpa para construir sistemas mais resilientes."