Object Storage On-Prem: Por Que a Promessa 'Cloud-Like' Vira Pesadelo Operacional

Descubra por que implementar Object Storage on-prem (S3-compatible) raramente é simples. Uma análise pragmática sobre latência, consistência e o custo real do 'grátis'.
Se eu ganhasse um centavo para cada vez que um CIO leu um artigo no LinkedIn sobre "Soberania de Dados" e decidiu que precisávamos construir nosso próprio AWS S3 no porão do prédio, eu já teria me aposentado em uma ilha sem conectividade de rede.
A narrativa é sempre a mesma, entregue com aquele brilho nos olhos de quem nunca teve que substituir um disco às 3 da manhã de um sábado: "Vamos usar hardware commodity! É Software-Defined Storage! É infinitamente escalável! Vamos economizar milhões saindo da nuvem!"
Deixe-me traduzir isso para o idioma do Sysadmin Veterano: "Vamos comprar lixo eletrônico, instalar um software complexo demais para nossa equipe de três pessoas gerenciar e criar um sistema de arquivos distribuído que vai corromper dados silenciosamente enquanto queima nossa sanidade."
Bem-vindo ao mundo do Object Storage On-Prem, onde a promessa de uma infraestrutura cloud-like colide violentamente com a realidade da física, da latência e do orçamento de TI.
O Hype do 'S3 Caseiro': A Ilusão do Hardware Commodity
O pecado original do Object Storage on-premise (seja Ceph, MinIO, Swift ou qualquer sabor do mês) é a mentira do hardware barato. Os vendedores de software juram de pés juntos que você pode pegar aqueles servidores R720 aposentados, encher de HDDs SATA de consumidor e — voilà — você tem um cluster de armazenamento resiliente.
Isso é uma falácia técnica.
Na nuvem pública, a Amazon e a Google fazem isso funcionar porque eles têm escala massiva. Quando um disco morre lá, é uma estatística irrelevante diluída em exabytes. Quando um disco morre no seu cluster de 4 nós "commodity", o rebalancing começa. E é aí que você descobre que sua rede de 10GbE (que você jurava ser suficiente) está saturada apenas movendo bits de paridade, derrubando a aplicação de RH que, por algum motivo, decidiram hospedar no mesmo switch.
A ideia de que o software resolve todas as deficiências do hardware é linda no papel. Na prática, o Software-Defined Storage (SDS) é apenas uma maneira chique de dizer que a CPU agora tem que fazer o trabalho que um controlador RAID dedicado fazia sem reclamar em 1999. Você está trocando CapEx (hardware decente) por OpEx (sua equipe bebendo café excessivamente para tunar o kernel do Linux).
A Realidade Operacional do Object Storage: Latência e IOPS
Vamos falar sobre o elefante na sala do servidor: Object Storage é lento.
Não me venha com benchmarks sintéticos de throughput sequencial. Qualquer coisa é rápida se você estiver apenas despejando ISOs de 50GB. O mundo real é feito de arquivos pequenos, leituras aleatórias e metadados.
O protocolo S3 (e seus primos) é baseado em HTTP/REST. Você sabe o que isso significa? Overhead. Muito overhead. Para cada PUT ou GET, você tem o handshake TCP, a negociação TLS (porque a segurança insistiu), o parsing dos headers HTTP, a autenticação, a consulta ao banco de dados de metadados, o cálculo do hash do objeto, a distribuição dos chunks via Erasure Coding e, finalmente, a escrita no disco.
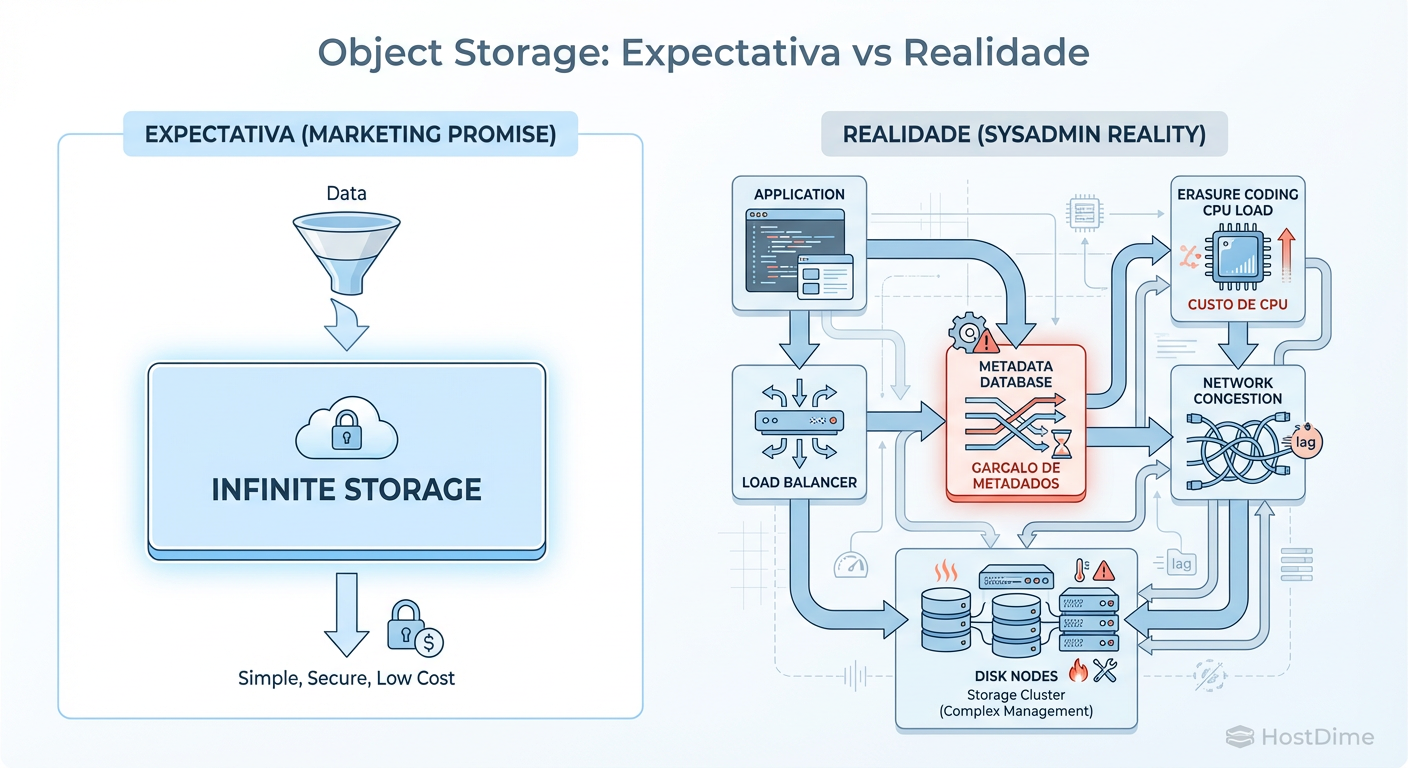 Figura: Fig. 1: O diagrama de fluxo que o vendedor do software esqueceu de mostrar no PowerPoint. Note onde a latência realmente se esconde.
Figura: Fig. 1: O diagrama de fluxo que o vendedor do software esqueceu de mostrar no PowerPoint. Note onde a latência realmente se esconde.
Compare isso com um bloco iSCSI ou um mount NFS. No Object Storage, a latência do "Time to First Byte" é abominável para cargas de trabalho transacionais. Se algum desenvolvedor full-stack tentar convencer você a montar um bucket S3 como um sistema de arquivos para rodar um banco de dados, bloqueie o acesso dele à cafeteira.
Tabela: A Mentira da Performance vs. Realidade
| Recurso | O que o Vendedor Diz | A Realidade On-Prem |
|---|---|---|
| Latência | "Baixa latência para aplicações modernas" | 50ms+ por operação é "normal". Seu DB vai dar timeout. |
| Throughput | "Escala linearmente com nós" | Escala até o switch de agregação pegar fogo. |
| IOPS | "Milhões de IOPS distribuídos" | Limitado pela velocidade do banco de metadados (RocksDB/LevelDB). |
| Hardware | "Roda em qualquer coisa" | Requer NVMe para metadados ou o cluster rasteja. |
Onde a Teoria Quebra: Gargalos de Metadados e o Inferno do Rebalancing
Aqui é onde os sonhos morrem. O segredo sujo do Object Storage é que ele não é apenas sobre armazenar o blob de dados; é sobre saber onde diabos esse pedaço de dado está.
O Gargalo dos Metadados
Todo cluster de Object Storage tem um mecanismo de gerenciamento de metadados. No Ceph, são os MONs e MDS. Em outras soluções, é um banco de dados chave-valor distribuído embutido. Quando você tem 100 milhões de objetos, esse banco de dados de metadados se torna um monstro.
Se você economizou no hardware e colocou os metadados em discos rotacionais ou SSDs baratos sem proteção contra perda de energia (PLP), prepare-se. Quando a latência de gravação dos metadados sobe, todo o cluster para. Não importa que seus discos de dados estejam 90% ociosos; se o cluster não consegue confirmar onde escrever, ele não escreve.
Consistência Eventual (Eventualmente Falha)
A promessa da "Consistência Eventual" é ótima para o feed do Twitter, mas péssima para o backup corporativo que precisa ser restaurado agora. Em arquiteturas on-prem mal configuradas, "eventual" pode significar "nunca" se houver uma partição de rede ou um "split-brain". Explicar para o Diretor Financeiro que o arquivo existe, mas o sistema "ainda não concordou sobre isso", é uma conversa que não desejo a ninguém.
O Pesadelo do Rebalancing
Um disco de 16TB falha. Acontece. Em um RAID 6 tradicional, a reconstrução é chata, mas previsível. No Object Storage com Erasure Coding, o sistema entra em pânico e tenta recriar a redundância lendo de todos os outros nós e escrevendo em todos os outros nós.
Isso gera uma tempestade de tráfego leste-oeste (East-West traffic) que pode saturar o backplane da sua rede. O desempenho do cluster cai para níveis inutilizáveis. Se outro disco falhar durante esse processo (o que é provável, dado que você comprou todos do mesmo lote "commodity"), você entra em uma espiral de morte de perda de dados.
A Alternativa Chata que Funciona: NAS e SAN
Sabe o que não é hype? POSIX. Sabe o que funciona há 40 anos? Sistemas de Arquivos.
A menos que você esteja armazenando Petabytes de dados frios (arquivos mortos, logs de conformidade que ninguém nunca vai ler), você provavelmente não precisa da complexidade de um Object Storage distribuído.
Um bom servidor rodando ZFS (TrueNAS, ou até mesmo um Linux bem configurado) ou um storage appliance empresarial (NetApp, Dell, Pure) vai superar um cluster Ceph mal-ajambrado em 90% dos casos de uso de pequenas e médias empresas.
Por que o "Boring Storage" Vence:
Simplicidade: Se quebrar,
ls,dmesgezpool statuste dizem o que houve. Não precisa debugar logs de RPC distribuído.Latência: O acesso a nível de bloco ou arquivo é ordens de magnitude mais rápido para a maioria das aplicações.
Confiabilidade: Controladores duplos e RAID via hardware (ou ZFS RAID-Z) são tecnologias maduras. Elas não tentam reinventar a roda via HTTP.
Custo Real: Quando você soma as horas-homem gastas para manter um cluster Object Storage de pé, aquele storage proprietário caro de repente parece uma pechincha.
Veredito Técnico Rabugenta: Mantenha Simples ou Pague Alguém para Sofrer
O Object Storage tem seu lugar. Se você é o CERN, a Netflix ou está construindo uma nuvem pública, vá em frente. Você tem a escala e a equipe de engenharia para fazer isso funcionar.
Mas para a empresa média, tentar replicar o S3 on-prem é um exercício de vaidade arquitetural. Você está introduzindo complexidade distribuída para resolver um problema de armazenamento que poderia ser resolvido com um chassi de discos decente e um cabo SAS.
Minha recomendação de veterano: Se você precisa de S3 porque seus desenvolvedores codaram a aplicação pensando na AWS, use a AWS. Se a conta está cara, use o Backblaze ou Cloudflare R2. Se você é obrigado por regulação a manter os dados em casa, compre um appliance que ofereça interface S3 (como MinIO rodando em um único box robusto ou um storage enterprise com gateway S3) e trate-o como uma caixa preta.
Não construa um cluster distribuído de sucata esperando performance de nuvem. A única coisa "Cloud-Like" que você vai conseguir é a sensação nebulosa na cabeça depois de virar três noites tentando recuperar seus metadados corrompidos.
Agora, se me dão licença, tenho que ir verificar por que o estagiário está tentando instalar Kubernetes no servidor de impressão.
Referências para quem duvida:
Ceph Documentation - Hardware Recommendations: Onde eles admitem que "commodity" não significa "lixo".
RFC 2616 (HTTP/1.1): Para entender por que usar HTTP para storage de alta performance é doloroso.
Cantrill, Bryan. "Visualizing DTrace Strategies". ACM Queue, onde aprendemos que latência nunca mente.
Google Site Reliability Engineering Book: Capítulo sobre armazenamento distribuído e por que é difícil pra c*****.

Dr. Elena Kovic
Metodologista de Benchmark
"Desmonto o marketing com análise estatística rigorosa. Meus benchmarks isolam cada variável para revelar a performance crua e sem filtros do hardware corporativo."