Object Storage para IA: Deixando de tratar o S3 como um disco USB glorificado

Seus clusters de H100 estão ociosos esperando dados? Descubra como arquitetar Object Storage de alta performance com GPUDirect e S3 Express One Zone para eliminar gargalos de I/O.
Você gastou o PIB de uma pequena nação insular para reservar um cluster de H100s. Seus cientistas de dados estão eufóricos, o CFO está tomando ansiolíticos e o roadmap de IA da empresa depende desse treinamento. Mas quando você olha para os gráficos de monitoramento, vê algo aterrorizante: suas GPUs de 30 mil dólares estão dormindo.
Não é culpa do modelo. Não é culpa do CUDA. É culpa da sua arquitetura de armazenamento que ainda trata o Amazon S3 (ou qualquer Object Storage compatível) como se fosse um pendrive gigante e lento na nuvem.
A verdade inconveniente é que a maioria das arquiteturas de dados foi desenhada para arquivamento ou web hosting, não para alimentar monstros famintos por throughput que consomem terabytes por hora. Se você ainda está fazendo aws s3 cp recursivo antes de iniciar seu script Python, você está queimando dinheiro. Vamos consertar isso.
Resumo em 30 segundos
- O Gargalo Invisível: GPUs modernas processam dados mais rápido do que o protocolo HTTP padrão consegue entregar, criando o temido gráfico "dente de serra" de ociosidade.
- A Morte do POSIX: Tentar montar buckets S3 como sistemas de arquivos (FUSE) é uma gambiarra que mata a performance devido ao overhead de metadados e travas de kernel.
- A Solução Real: O uso de Directory Buckets (como S3 Express One Zone) e GPUDirect Storage elimina a CPU do caminho, permitindo que o dado flua do disco direto para a VRAM.
O silêncio caro das GPUs H100 ociosas e o gráfico dente de serra
Imagine contratar um piloto de Fórmula 1 e fazê-lo parar a cada volta para ler um mapa de papel. É exatamente isso que acontece quando o I/O de armazenamento não acompanha a velocidade de computação da GPU.
No mundo ideal, o fluxo de dados para a GPU é contínuo. No mundo real, observamos o padrão "dente de serra" (sawtooth). A GPU processa um batch em milissegundos e então... espera. Espera o próximo batch ser baixado do Object Storage, desserializado pela CPU e copiado para a memória.
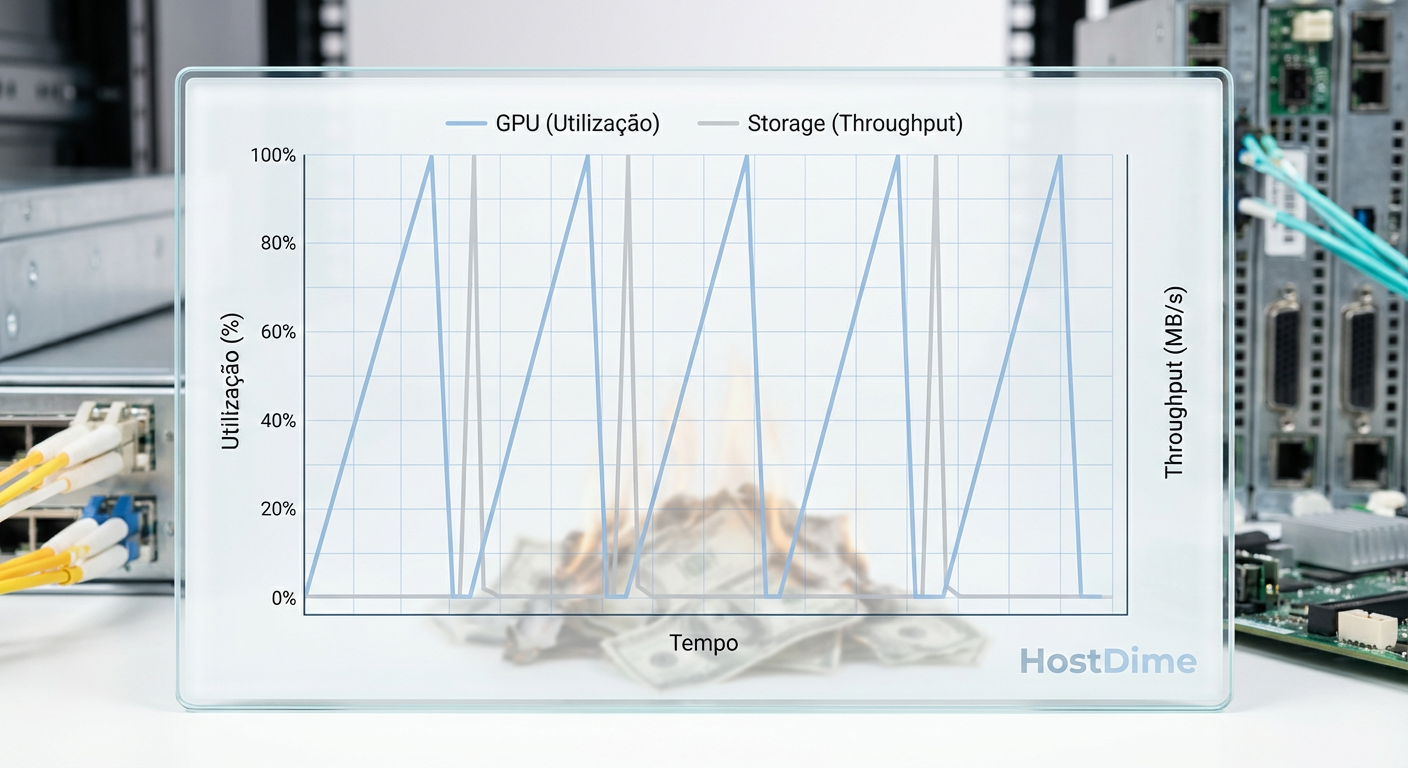 Figura: O gráfico "Dente de Serra": A linha verde representa a utilização da GPU caindo a zero enquanto espera o I/O (linha azul) entregar dados, desperdiçando orçamento de computação.
Figura: O gráfico "Dente de Serra": A linha verde representa a utilização da GPU caindo a zero enquanto espera o I/O (linha azul) entregar dados, desperdiçando orçamento de computação.
Se o seu cluster custa US$ 500 por hora e suas GPUs ficam ociosas 30% do tempo esperando dados (I/O Wait), você não está apenas perdendo tempo; você está pagando uma "taxa de latência" de US$ 150/hora. Multiplique isso por um treinamento de três semanas e você terá uma conversa muito desagradável com o financeiro.
💡 Dica Pro: Monitore a métrica
GPU Utilizationem conjunto comRX Bytesna interface de rede. Se elas forem inversamente proporcionais (uma sobe, a outra desce), seu gargalo é inequivocamente o storage ou a rede, não o código do modelo.
A anatomia da latência: por que o protocolo HTTP e o buffer da CPU matam a performance
O S3 é uma maravilha da engenharia distribuída, mas ele fala HTTP/REST. Para cada objeto que você pede (e em Deep Learning, estamos falando de milhões de pequenos arquivos de imagem ou áudio), existe um handshake, cabeçalhos, e o pior de tudo: o caminho tortuoso do dado dentro do servidor.
No fluxo tradicional, o dado faz uma viagem turística desnecessária:
Sai do Storage via rede.
Entra na NIC (Placa de Rede) da instância.
A CPU copia o dado do buffer da NIC para a memória do Kernel.
A CPU copia do Kernel para o User Space (onde seu PyTorch roda).
A CPU copia do User Space para o driver da GPU.
Finalmente, o dado chega à VRAM da GPU.
Isso é conhecido como "CPU Bounce". Sua CPU, que deveria estar orquestrando o treinamento ou fazendo pré-processamento leve, vira um despachante de luxo, gastando ciclos preciosos apenas movendo bits de um lugar para outro.
Além disso, temos a latência de "primeiro byte" (TTFB). Em buckets padrão (Standard Tier), a latência pode variar entre 10ms a 100ms. Para um arquivo de 10GB, isso é irrelevante. Para um milhão de arquivos de 50KB, a latência acumulada é maior que o tempo de treino.
A armadilha de copiar datasets de petabytes para NVMe local efêmero
A solução "clássica" de 2018 era simples: provisione uma instância com 8TB de NVMe local, copie todo o dataset do S3 para o disco no boot e treine localmente.
Isso não funciona mais. Por quê?
Escala dos Dados: Datasets modernos (como Common Crawl para LLMs ou LAION para imagem) têm Petabytes. Eles não cabem no NVMe local de uma única máquina, nem mesmo nas instâncias
p5.48xlargemais parrudas.Tempo de Boot (Cold Start): Copiar 10TB de dados a 10Gbps leva horas. Se o seu spot instance for interrompido e você precisar reiniciar, lá se vão mais horas copiando dados antes de processar um único tensor.
Custo de Oportunidade: O armazenamento NVMe local em instâncias de GPU é caro e efêmero. Usá-lo como cache de leitura única é ineficiente.
Precisamos de um modelo onde o Object Storage seja performático o suficiente para ser consumido diretamente, ou com um caching inteligente que não exija pré-aquecimento manual.
Comparativo: Abordagens de Acesso a Dados
| Característica | Cópia Local (Legado) | FUSE Mount (s3fs/Goofys) | Streaming Direto / SDK |
|---|---|---|---|
| Latência | Baixíssima (NVMe) | Alta (Overhead de Metadados) | Média/Baixa (Otimizado) |
| Tempo de Início | Horas (Cópia prévia) | Imediato | Imediato |
| Escalabilidade | Limitada ao disco local | Limitada pela CPU/FUSE | Infinita (Paralelismo) |
| Complexidade | Baixa (Arquivos locais) | Média (POSIX fake) | Alta (Requer refatoração) |
| Custo Oculto | Tempo de GPU ociosa no boot | CPU gasta em syscalls | Custo de API (GET requests) |
Implementando buckets de diretório e bypass de kernel com GPUDirect
Aqui é onde a arquitetura moderna se separa dos tutoriais antigos. Para resolver o problema da latência e do CPU Bounce, a indústria (liderada por AWS e NVIDIA) introduziu duas mudanças tectônicas.
1. Buckets de Diretório (S3 Express One Zone)
Lançado recentemente, o S3 Express One Zone muda a estrutura fundamental de como os objetos são indexados. O S3 padrão tem uma estrutura "flat" onde as pastas são uma ilusão criada pelos prefixos das chaves. Isso limita a taxa de requisições por prefixo (geralmente 3.500 PUT/COPY/POST/DELETE ou 5.500 GET/HEAD por segundo).
Os Directory Buckets usam uma hierarquia real e hardware dedicado, entregando latência de um dígito em milissegundos (single-digit millisecond latency). Isso permite que o storage responda tão rápido quanto um array flash local, suportando centenas de milhares de TPS (transações por segundo). É o fim do gargalo de metadados.
2. GPUDirect Storage (GDS) e NVIDIA Magnum IO
Lembra da viagem turística do dado pela CPU? O GPUDirect Storage (GDS) cria uma via expressa.
Utilizando tecnologias como RDMA (Remote Direct Memory Access), o GDS permite que a placa de rede envie os dados diretamente para a memória da GPU, ignorando completamente a CPU e a memória RAM do sistema principal.
 Figura: Comparação de Data Path: O caminho legado (topo) sobrecarrega a CPU com cópias de memória. O caminho GPUDirect (fundo) cria um túnel direto entre o Storage e a GPU.
Figura: Comparação de Data Path: O caminho legado (topo) sobrecarrega a CPU com cópias de memória. O caminho GPUDirect (fundo) cria um túnel direto entre o Storage e a GPU.
Isso não apenas reduz a latência, mas libera a CPU para fazer o que ela deveria estar fazendo: pré-processamento de dados, data augmentation ou gerenciamento de checkpoints. Testes mostram que o GDS pode reduzir a carga da CPU em até 45% durante cargas intensas de I/O.
⚠️ Perigo: Para usar GDS com Object Storage, você geralmente precisa de uma camada de abstração compatível ou um cliente de alta performance (como o AIStore ou integrações específicas do PyTorch DataPipes), pois o S3 nativo é HTTP. Não é "plug and play" sem configuração de software.
Métricas de validação: reduzindo o tempo de checkpoint de minutos para segundos
Não falamos apenas de leitura. O treinamento de LLMs é instável. Hardware falha. Drivers quebram. O "Save Game" (Checkpointing) é crítico.
Em modelos com bilhões de parâmetros, um checkpoint pode ter centenas de Gigabytes. Se você usa o método padrão de serialização para um bucket S3 Standard, o processo de escrita pode pausar o treinamento (blocking operation) por minutos.
Otimização de Checkpoint:
Multipart Uploads Paralelos: Nunca envie um arquivo de 100GB como um fluxo único. Quebre em partes de 100MB e suba em paralelo massivo.
Escrita Assíncrona: Use bibliotecas que permitem descarregar o checkpoint para a memória RAM primeiro e, em seguida, uma thread separada faz o upload para o S3 enquanto o treinamento retoma (non-blocking).
Tiering de Storage: Jogue o checkpoint no S3 Express (rápido e caro) inicialmente. Configure uma regra de Lifecycle Policy para movê-lo para S3 Standard ou Infrequent Access após 24 horas. Você paga pela velocidade quando precisa (escrita e recuperação rápida de falha) e paga pelo arquivamento barato a longo prazo.
O Veredito do Arquiteto
Tratar Object Storage como um sistema de arquivos legado é o maior gargalo oculto em pipelines de IA modernos. A infraestrutura evoluiu. Temos agora buckets de baixa latência e caminhos diretos de hardware (GDS) que eliminam a CPU da equação de I/O.
Se você está pagando por H100s, você tem a obrigação moral e financeira de alimentá-las na velocidade máxima. Pare de otimizar centavos no custo do GB de armazenamento e comece a olhar para o custo do minuto de GPU ociosa. A matemática é brutal e não perdoa arquiteturas preguiçosas.
Construa pipelines que façam streaming, use buckets de alta performance para o hot tier e deixe o cp -r para os amadores.
FAQ: Perguntas Frequentes
O S3 Express One Zone substitui o S3 Standard para treinamento de IA?
Não para tudo. Ele é ideal para o 'hot tier' de treinamento e checkpoints frequentes devido à latência de um dígito em milissegundos, mas custa significativamente mais por GB (cerca de 7x mais que o Standard em algumas regiões). O S3 Standard continua sendo o repositório final (cold tier) e a fonte da verdade para datasets que não estão em uso ativo imediato.O que é GPUDirect Storage e por que ele importa para Object Storage?
É uma tecnologia parte do NVIDIA Magnum IO que permite que a GPU leia dados diretamente do storage (via NVMe local ou RDMA sobre rede), ignorando a CPU e a memória do sistema principal. Isso elimina o efeito de "bounce buffer", reduzindo a latência e a carga da CPU em até 45%, garantindo que a GPU não fique esperando dados.Sistemas de arquivos paralelos (Lustre/GPFS) ainda são necessários?
Eles ainda têm seu lugar em supercomputação tradicional (HPC), mas o Object Storage moderno com suporte a 'Directory Buckets' e clientes de alta performance está fechando essa lacuna rapidamente. Isso permite arquiteturas mais simples, elásticas e nativas de nuvem sem a complexidade operacional insana de gerenciar um filesystem POSIX em exascale.Como o CXL (Compute Express Link) vai impactar isso no futuro?
O CXL, especificamente o CXL 2.0 e 3.0, permitirá o compartilhamento de memória e pool de recursos entre CPU e aceleradores com coerência de cache. Isso pode reduzir ainda mais a necessidade de cópias de dados, permitindo que o storage se comporte quase como uma extensão da memória RAM endereçável, mas isso ainda é uma tecnologia emergente para a próxima geração de servidores.Referências & Leitura Complementar
AWS S3 Express One Zone: Documentação oficial sobre a nova classe de armazenamento de baixa latência. AWS Documentation
NVIDIA GPUDirect Storage (Magnum IO): Whitepaper técnico sobre o fluxo de dados direto para VRAM. NVIDIA Developer
SNIA (Storage Networking Industry Association): Especificações sobre performance de armazenamento para IA e cargas de trabalho de alto throughput.
PyTorch DataPipes: Implementação moderna de data loading para streaming direto de URLs e buckets. PyTorch Docs

Rafael Barros
Arquiteto de Cloud Storage
"Desenho arquiteturas de object storage escaláveis e guiadas por API. Meu foco é performance máxima sem deixar o orçamento sangrar com taxas de egress ocultas."