Object Storage vs Block Storage: Diferenças críticas de arquitetura e performance

Entenda a batalha técnica entre SAN/iSCSI e S3/MinIO. Analisamos latência, escalabilidade e custos para definir quando usar Block ou Object Storage.
Se você já tentou rodar um banco de dados de alta performance em um bucket S3 montado como disco local, você sabe exatamente o que é dor. Se você nunca fez isso, parabéns: você evitou um dos erros mais comuns e catastróficos de arquitetura de dados.
No mundo do armazenamento, "espaço" não é apenas capacidade. A forma como seus dados são endereçados, recuperados e protegidos define se sua aplicação voará baixo ou rastejará. A batalha entre Block Storage (Armazenamento em Bloco) e Object Storage (Armazenamento de Objeto) não é sobre qual é "melhor", mas sobre qual problema de engenharia você está tentando resolver: latência de microssegundos ou escala de petabytes.
Resumo em 30 segundos
- Block Storage (SAN/DAS): Divide dados em blocos de tamanho fixo (setores). É o rei da baixa latência e consistência. Obrigatório para bancos de dados (SQL), discos de boot de VMs e aplicações sensíveis a IOPS.
- Object Storage (S3/Blob): Trata dados como objetos imutáveis com metadados ricos e ID único. É o rei da escalabilidade massiva e custo por TB. Ideal para backups, media streaming, data lakes e arquivos não estruturados.
- O erro fatal: Tentar usar Object Storage para cargas de trabalho transacionais resulta em latência inaceitável devido ao overhead do protocolo HTTP/REST.
A diferença fundamental: setores lógicos vs buckets via API
Para entender a performance, precisamos descer ao nível do sistema operacional.
No Block Storage (pense em um SSD NVMe, um volume iSCSI ou uma LUN em uma SAN), o sistema operacional vê o armazenamento como uma sequência linear de setores ou blocos (geralmente 4KB ou 512 bytes). Quando você salva um arquivo, o sistema de arquivos (NTFS, EXT4, ZFS) decide: "Vou colocar este pedaço no bloco LBA 100 e o próximo no LBA 101". O disco não sabe o que é um "arquivo", ele apenas obedece ordens de gravação em endereços específicos.
No Object Storage, o conceito de setor ou posição física não existe para o usuário. Você não "grava no setor X". Você envia um comando PUT via API (geralmente RESTful sobre HTTP) contendo o dado e um ID único (Key). O sistema de storage recebe esse pacote, calcula onde guardá-lo em um cluster de servidores e devolve um "OK".
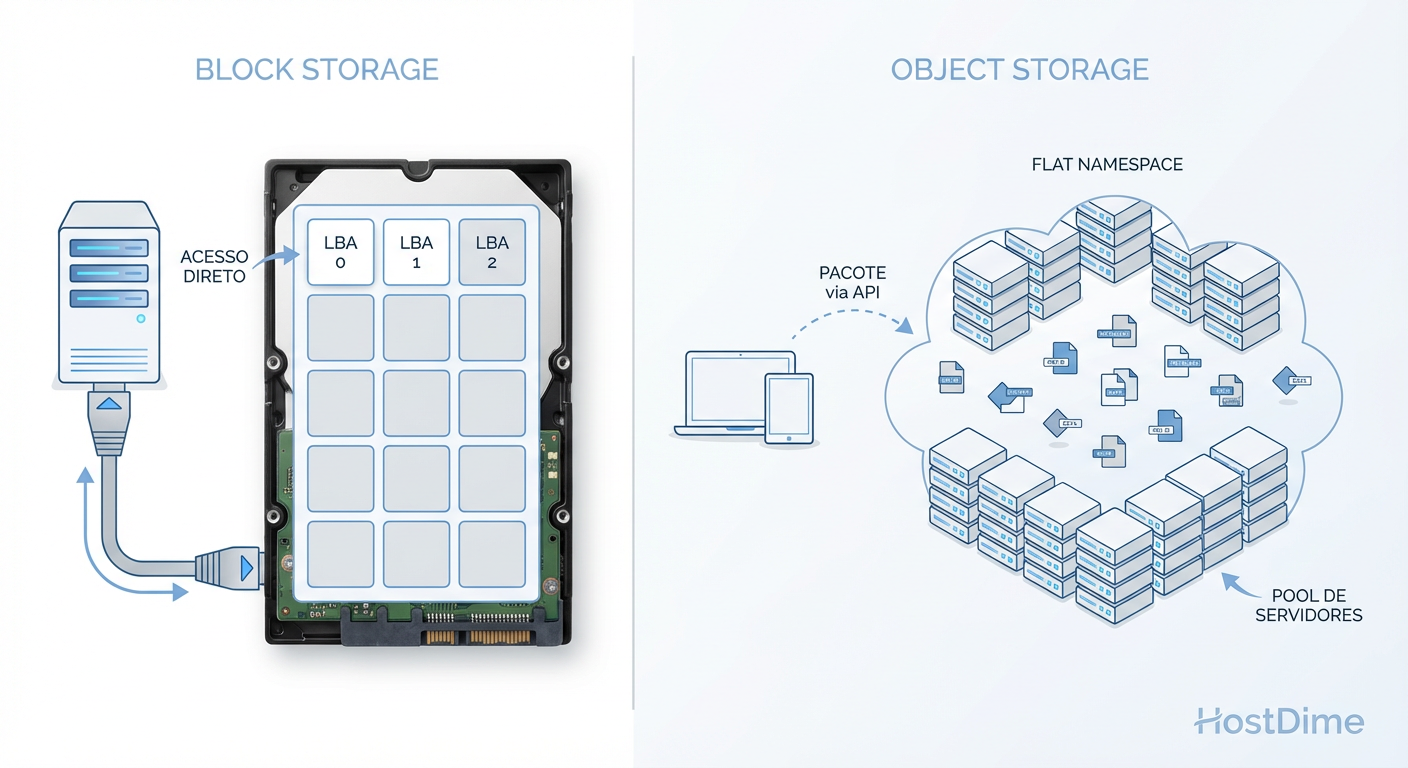 Figura: Legenda: Block Storage gerencia endereços físicos lógicos; Object Storage gerencia chaves em um namespace plano.
Figura: Legenda: Block Storage gerencia endereços físicos lógicos; Object Storage gerencia chaves em um namespace plano.
💡 Dica Pro: Pense no Block Storage como um estacionamento com vagas numeradas. Você sabe exatamente onde o carro está (Vaga 4B). O Object Storage é um serviço de Valet. Você entrega a chave e o carro, recebe um ticket, e não faz ideia de onde o carro foi estacionado, apenas que ele voltará quando você apresentar o ticket.
Anatomia da gravação: acesso direto vs encapsulamento
Aqui é onde a performance diverge drasticamente.
Quando uma aplicação grava em Block Storage, o caminho é curto e otimizado. O comando passa pelo barramento PCIe (no caso de NVMe) ou por uma rede dedicada (Fibre Channel/iSCSI), chegando ao controlador do disco quase instantaneamente. Não há tradução complexa de protocolos de alto nível. É I/O bruto.
No Object Storage, a anatomia de uma gravação é burocrática:
A aplicação gera uma requisição HTTP (TCP handshake, headers, overhead).
O Load Balancer recebe e encaminha para um nó de acesso.
O sistema calcula o hash do objeto e determina a localização.
Metadados são gerados e indexados separadamente dos dados.
O dado é frequentemente dividido usando Erasure Coding (mais sobre isso adiante) e espalhado por múltiplos discos em múltiplos servidores.
O sistema aguarda a confirmação de gravação de n nós antes de retornar o código 200 OK para o cliente.
Esse "overhead" do protocolo HTTP e a gestão de metadados adicionam milissegundos preciosos. Para um arquivo de vídeo de 10GB, isso é irrelevante (o throughput importa mais). Para 10.000 transações de banco de dados por segundo, é a morte.
O gargalo da latência: por que bancos relacionais exigem block
Bancos de dados relacionais (PostgreSQL, MySQL, Oracle) dependem de latência de disco previsível e consistência atômica. Eles frequentemente alteram apenas alguns bytes de um arquivo gigante (ex: atualizar o saldo de uma conta).
No Block Storage, alterar 4KB no meio de um arquivo de 100GB é trivial: o sistema sobrescreve apenas aquele bloco específico.
No Object Storage, os objetos são imutáveis. Você não pode editar um objeto. Para mudar uma vírgula, você precisa:
Ler o objeto inteiro (GET).
Modificar na memória.
Gravar o objeto inteiro novamente como uma nova versão (PUT).
Isso gera uma amplificação de escrita absurda. É por isso que rodar um banco de dados sobre um mount point S3 (usando ferramentas como S3FS ou Rclone) resulta em corrupção de dados ou performance abismal.
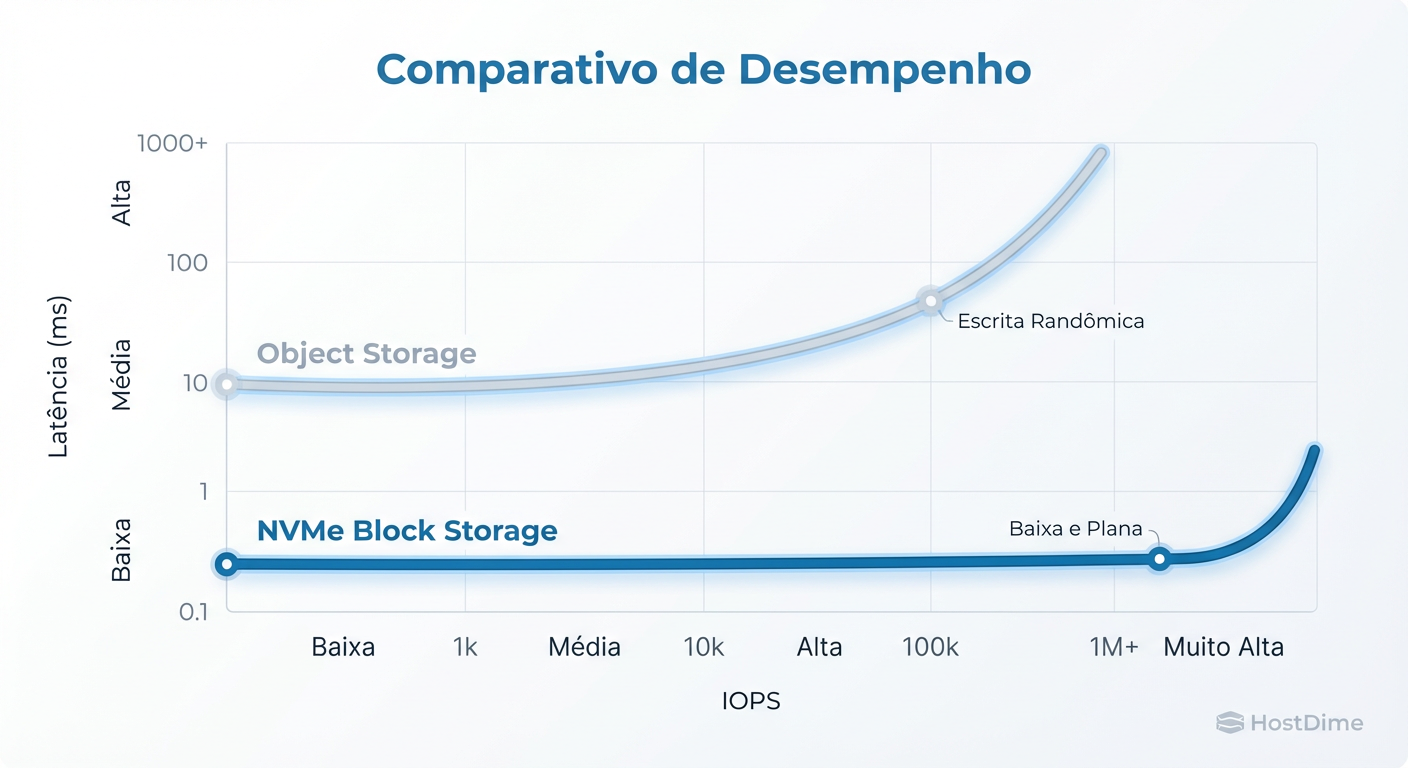 Figura: Legenda: A latência do Object Storage dispara em cargas de trabalho transacionais pequenas, enquanto o Block mantém estabilidade.
Figura: Legenda: A latência do Object Storage dispara em cargas de trabalho transacionais pequenas, enquanto o Block mantém estabilidade.
A barreira dos inodes: quando o sistema de arquivos limita a escala
Se o Block Storage é tão rápido, por que não usamos ele para tudo? Porque sistemas de arquivos tradicionais não escalam infinitamente.
Sistemas de arquivos que vivem em cima de Block Storage (como EXT4 ou XFS) usam inodes para rastrear arquivos. Cada arquivo consome um inode. Se você tentar armazenar 1 bilhão de fotos de 5KB em um único volume:
Você provavelmente esgotará os inodes antes de esgotar o espaço em disco.
A performance de listagem (
lsoudir) cairá para zero, pois o sistema precisa percorrer árvores hierárquicas gigantescas.O backup desse volume levará dias apenas para "caminhar" pela estrutura de diretórios.
O Object Storage elimina a hierarquia. É um Flat Namespace (Namespace Plano). Não existem "pastas" reais, apenas prefixos no nome da chave (ex: fotos/2025/janeiro/img.jpg é o nome do objeto, não uma estrutura de diretórios física). Isso permite que um único bucket escale para exabytes de dados e trilhões de objetos sem degradação de performance na recuperação direta pelo ID.
Comparativo de protocolos: NVMe/iSCSI vs HTTP/REST
A eficiência do transporte é outro divisor de águas.
Block (NVMe/FC/iSCSI):
NVMe: Projetado para flash. Suporta 64.000 filas de comandos, com 64.000 comandos por fila. É paralelismo puro.
Overhead: Mínimo. O protocolo é binário e enxuto.
Object (S3 API/Swift):
HTTP/REST: Protocolo de texto. Cada operação carrega headers HTTP (User-Agent, Date, Auth tokens).
Conexão: Frequentemente exige abertura e fechamento de conexões TCP (embora HTTP/2 e Keep-Alive ajudem), o que é custoso para CPU.
⚠️ Perigo: Não subestime o custo de CPU do Object Storage. Calcular hashes MD5/SHA para verificação de integridade e gerenciar conexões HTTPS em escala exige muito mais poder de processamento dos servidores de storage do que um array SAN tradicional.
Análise de TCO: Hardware proprietário vs Commodity com Erasure Coding
Aqui o jogo vira a favor do Object Storage.
Para garantir redundância em Block Storage, tradicionalmente usamos RAID (1, 5, 6, 10).
RAID 10: Ótima performance, mas você perde 50% da capacidade bruta (overhead de 100%).
Hardware: SANs Enterprise (Dell PowerStore, Pure Storage, NetApp) usam controladores proprietários duplos, cache NVRAM espelhado e backplanes customizados. O custo por GB é alto.
No Object Storage, a proteção de dados geralmente é feita via Erasure Coding (EC).
O EC divide o dado em fragmentos de dados (k) e fragmentos de paridade (m).
Exemplo: Em um esquema 10+4, você divide o arquivo em 10 pedaços e cria 4 de paridade. Você pode perder quaisquer 4 discos (ou servidores inteiros) e ainda ler o dado.
Eficiência: O overhead é de apenas ~1.4x (comparado a 2x do RAID 10), oferecendo durabilidade muito superior.
Hardware: Roda em servidores commodity x86 padrão (Supermicro, Dell PowerEdge comuns) cheios de discos rígidos de alta capacidade.
 Figura: Legenda: A arquitetura distribuída do Object Storage permite uso de hardware commodity, reduzindo drasticamente o TCO em escala.
Figura: Legenda: A arquitetura distribuída do Object Storage permite uso de hardware commodity, reduzindo drasticamente o TCO em escala.
Veredito: Alinhando a infraestrutura ao perfil de I/O
A escolha entre Block e Object não é uma preferência pessoal, é uma decisão ditada pelo perfil de I/O da sua aplicação.
Use Block Storage (NVMe/SAN) quando:
A aplicação é um Banco de Dados: SQL Server, MySQL, PostgreSQL, Oracle.
Boot de Sistemas: O sistema operacional precisa de um disco local para iniciar.
Virtualização: Datastores VMware ou Hyper-V.
Latência Crítica: Aplicações de trading de alta frequência ou renderização em tempo real.
Use Object Storage (S3/MinIO) quando:
Dados Não Estruturados: Imagens, vídeos, PDFs, logs, backups.
Aplicações Cloud-Native: Software moderno escrito para consumir APIs S3 diretamente.
Arquivamento de Longo Prazo: Dados que precisam ser guardados por anos (WORM - Write Once Read Many).
Big Data & AI: Data Lakes (Spark, Presto) que varrem petabytes de dados sequencialmente.
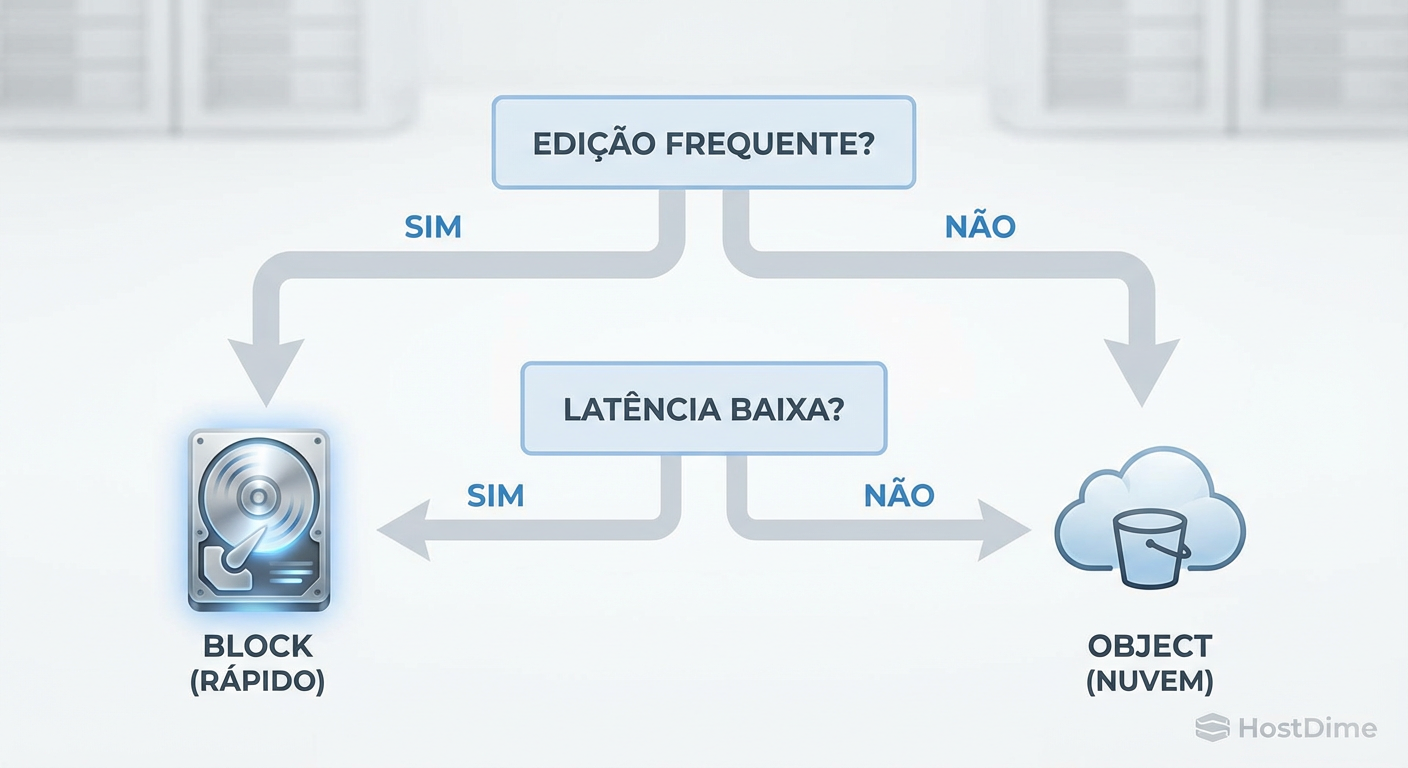 Figura: Legenda: Fluxo simplificado para decisão de arquitetura de armazenamento.
Figura: Legenda: Fluxo simplificado para decisão de arquitetura de armazenamento.
Não tente forçar uma tecnologia a fazer o trabalho da outra. Montar buckets S3 como drives locais para usuários finais é uma receita para frustração e chamados de suporte infinitos devido à latência. Por outro lado, armazenar backups de 5 anos em um array All-Flash NVMe é queimar dinheiro da empresa. A infraestrutura eficiente coloca o dado certo, no protocolo certo, pelo preço certo.

Carlos Ornelas
Mecânico de Datacenter
"Vivo nos corredores frios instalando racks e organizando cabeamento estruturado. Para mim, a nuvem é feita de metal, silício e ventoinhas que precisam girar sem parar."