Omissão coordenada no Fio: a falha metodológica que invalida testes de latência em NVMe

Descubra como a omissão coordenada mascara a latência de cauda em SSDs NVMe durante testes com o Fio e aprenda a configurar benchmarks de malha aberta.
Você acaba de instalar um novo array de SSDs NVMe (Non-Volatile Memory Express) no seu servidor. Para validar o investimento, você abre o terminal, executa um script padrão do Fio (Flexible I/O Tester) e sorri ao ver latências médias na casa dos microssegundos. O relatório vai para a diretoria, o sistema entra em produção e, subitamente, seu banco de dados começa a apresentar travamentos inexplicáveis sob carga pesada.
O hardware não está com defeito. O problema é que o seu benchmark mentiu para você.
Na engenharia de armazenamento de dados, confiar em testes de carga padrão sem entender a mecânica de enfileiramento do gerador de I/O é um erro fatal. A grande maioria dos administradores de sistemas e analistas de infraestrutura é vítima de um fenômeno matemático e metodológico conhecido como omissão coordenada (coordinated omission). Este erro mascara os verdadeiros gargalos dos discos, escondendo picos de latência que inevitavelmente destruirão o desempenho de aplicações sensíveis a tempo de resposta.
Resumo em 30 segundos
- Testes padrão no Fio operam em malha fechada, pausando o envio de novas requisições quando o SSD engasga, o que esconde a latência real.
- Aumentar a profundidade de fila (Queue Depth) não resolve o problema metodológico, apenas satura o barramento de forma irrealista.
- Para obter dados reais, é obrigatório configurar o Fio em malha aberta, utilizando taxas fixas de IOPS e distribuição de Poisson para simular tráfego de produção.
A mecânica da omissão coordenada e o mascaramento da latência de cauda
O termo omissão coordenada foi popularizado por Gil Tene para descrever uma falha fundamental em ferramentas de benchmark. Por padrão, o Fio opera em um sistema de malha fechada (closed-loop). Isso significa que o gerador de carga envia uma requisição de leitura ou escrita para o disco e aguarda a resposta antes de enviar a próxima requisição daquela mesma thread.
Se o seu SSD NVMe precisar pausar as operações por 50 milissegundos para executar uma rotina interna de Garbage Collection (limpeza de blocos de memória flash), o Fio também vai pausar. Durante esses 50 milissegundos, nenhuma nova requisição é gerada ou contabilizada no relatório de latência. O benchmark está, literalmente, sendo educado com o disco lento.
 Figura: Diagrama conceitual mostrando a diferença de enfileiramento entre testes de malha fechada e malha aberta em SSDs NVMe.
Figura: Diagrama conceitual mostrando a diferença de enfileiramento entre testes de malha fechada e malha aberta em SSDs NVMe.
No mundo real, os usuários do seu site ou as transações do seu banco de dados não são educados. Se o storage engasgar, as requisições da rede continuarão chegando, acumulando-se nas filas do sistema operacional e do hypervisor. Quando o disco finalmente voltar a responder, a latência experimentada pela aplicação não será apenas o tempo de processamento do I/O, mas todo o tempo que a requisição passou esperando na fila. O teste de malha fechada omite esse tempo de espera, gerando um relatório otimista e perigoso.
⚠️ Perigo: Relatórios de marketing de fabricantes de storage quase sempre utilizam testes de malha fechada para exibir latências médias irreais. Nunca dimensione um ambiente de missão crítica baseado nesses números.
O erro de aumentar a profundidade de fila para forçar o estresse
Uma tentativa comum de contornar resultados irreais é aumentar agressivamente o parâmetro iodepth (profundidade de fila) no Fio. A lógica ingênua dita que, ao manter 128 ou 256 requisições simultâneas em voo, o disco será forçado a mostrar seus limites. Embora isso aumente o throughput total (largura de banda), não corrige a omissão coordenada.
Aumentar a profundidade de fila em um teste de malha fechada apenas cria um lote maior de requisições simultâneas. Se o controlador do SSD travar, todas as 256 requisições da fila sofrerão o atraso, mas o Fio continuará sem enviar a requisição número 257 até que um slot seja liberado. O enfileiramento externo, que ocorreria no kernel do Linux ou no VMware ESXi durante um pico de tráfego, continua sendo ignorado pela ferramenta de teste.
Para entender claramente a diferença de abordagem, precisamos comparar os dois métodos de teste de estresse em infraestrutura de storage.
| Característica | Malha fechada (Padrão do Fio) | Malha aberta (Recomendado) |
|---|---|---|
| Geração de carga | Depende da resposta do disco | Independente da resposta do disco |
| Comportamento em gargalos | Pausa o envio de novos I/Os | Continua enviando I/Os (acumula fila) |
| Métrica de latência | Mede apenas o tempo de serviço do disco | Mede tempo de serviço + tempo de espera na fila |
| Caso de uso ideal | Medir throughput máximo teórico | Medir latência real de aplicações e bancos de dados |
| Risco metodológico | Mascara picos de latência (Omissão Coordenada) | Requer calibração cuidadosa para não travar o host |
Implementando testes de malha aberta com distribuição de Poisson no Fio
Para destruir a ilusão da omissão coordenada, precisamos forçar o Fio a operar em malha aberta (open-loop). O objetivo é instruir a ferramenta a disparar requisições em uma taxa fixa, independentemente de o storage estar respondendo rápido ou lento. Se o disco atrasar, o Fio deve registrar o tempo que a nova requisição ficou esperando para ser despachada.
No Fio, alcançamos isso utilizando o parâmetro rate_iops. Ao definir um limite fixo de operações por segundo, desvinculamos a geração de carga da velocidade de resposta do hardware. No entanto, apenas fixar a taxa não é suficiente para simular o caos de um ambiente de produção.
 Figura: Configuração de parâmetros no terminal Linux forçando o Fio a operar com distribuição de Poisson.
Figura: Configuração de parâmetros no terminal Linux forçando o Fio a operar com distribuição de Poisson.
É aqui que entra o parâmetro rate_process=poisson. Em vez de enviar requisições em intervalos perfeitamente espaçados (o que é irreal), a distribuição de Poisson randomiza o tempo de chegada das requisições. Isso cria micro-explosões de tráfego seguidas de breves calmarias, imitando perfeitamente o comportamento de conexões de rede chegando a um servidor web ou consultas SQL atingindo um banco de dados.
Um bloco de configuração rigoroso no Fio para testar a latência real de um SSD NVMe corporativo ficaria semelhante a isto:
[global]
ioengine=libaio
direct=1
invalidate=1
time_based=1
runtime=3600
[teste_malha_aberta]
filename=/dev/nvme0n1
rw=randread
bs=4k
iodepth=64
rate_iops=80000
rate_process=poisson
💡 Dica Pro: Ao usar
rate_iops, certifique-se de que o valor escolhido seja inferior ao limite máximo absoluto do disco. O objetivo da malha aberta é medir a latência sob uma carga sustentada realista, não causar um buffer overflow imediato no sistema operacional.
Comprovando a latência real do SSD através da análise do percentil 99.99
Com o teste de malha aberta configurado, o próximo passo é saber para onde olhar no relatório final. A latência média é a métrica mais inútil na engenharia de storage. Ela dilui anomalias matemáticas severas. Se um SSD responde a 9.999 requisições em 0.1ms, mas trava por 100ms em uma única requisição devido a um flush de cache, a média continuará parecendo excelente.
A verdadeira saúde do seu subsistema de armazenamento reside na latência de cauda (tail latency). No Fio, isso é representado pelos percentis de conclusão (clat percentiles). Para ambientes corporativos, o foco deve estar no percentil 99 (p99), 99.9 (p99.9) e, crucialmente, no 99.99 (p99.99).
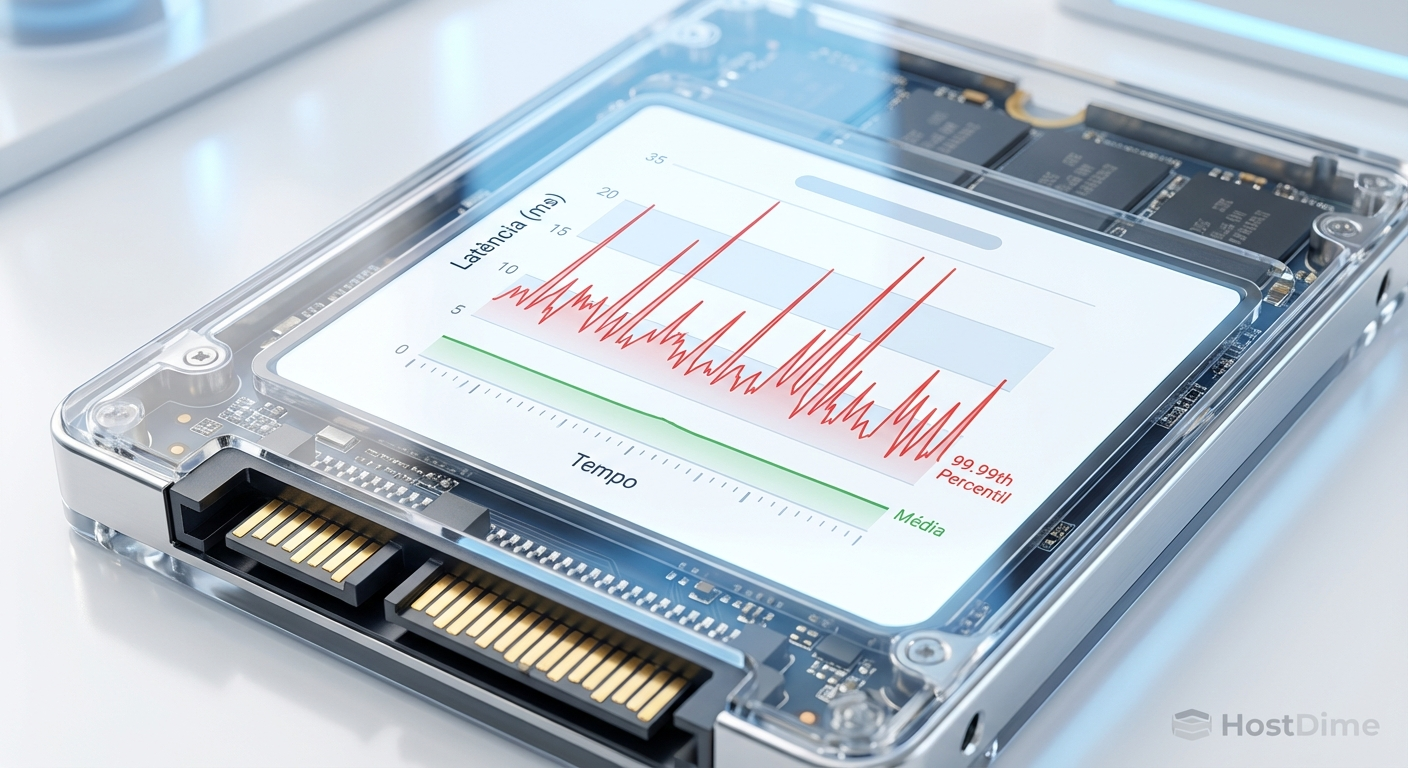 Figura: Gráfico evidenciando como a latência média esconde os picos severos revelados pela análise do percentil 99.99.
Figura: Gráfico evidenciando como a latência média esconde os picos severos revelados pela análise do percentil 99.99.
O percentil 99.99 indica o tempo máximo que as requisições mais lentas (1 em cada 10.000) levaram para ser concluídas. Em um banco de dados transacional de alto volume, 10.000 IOPS ocorrem em um único segundo. Se o seu p99.99 for de 200 milissegundos, isso significa que seu banco de dados está sofrendo engasgos perceptíveis a cada segundo de operação.
Ao rodar o teste com distribuição de Poisson e malha aberta, você notará que o p99.99 reportado será ordens de magnitude pior do que nos seus testes antigos de malha fechada. Não se assuste. Você não quebrou o hardware. Você apenas removeu a venda metodológica e está finalmente enxergando o comportamento real do controlador flash sob estresse.
O impacto no mundo real em hypervisors e bancos de dados
A ignorância sobre a omissão coordenada é a causa raiz de muitos problemas de performance em clusters de virtualização. Hypervisors como VMware ESXi e Proxmox VE dependem de latências de armazenamento consistentes para gerenciar o I/O de dezenas de máquinas virtuais simultaneamente.
Quando um SSD NVMe de baixo custo (frequentemente focado no mercado consumidor) é colocado em um servidor corporativo, seus testes iniciais de malha fechada podem parecer adequados. No entanto, sob a carga paralela e caótica de múltiplas VMs, o controlador do disco satura. O hypervisor continua enviando comandos (malha aberta real), as filas do kernel enchem e o infame erro de "I/O abortado" ou "latência de datastore alta" começa a pipocar nos logs de monitoramento.
 Figura: Representação visual do acúmulo de requisições no controlador de um SSD NVMe durante um gargalo de I/O.
Figura: Representação visual do acúmulo de requisições no controlador de um SSD NVMe durante um gargalo de I/O.
Discos de classe Enterprise (como os formatos U.2, U.3 ou E1.S) possuem firmware otimizado especificamente para manter a latência de cauda baixa e previsível, sacrificando muitas vezes o pico de IOPS de marketing em favor da estabilidade. A única maneira de provar o valor de um disco Enterprise sobre um disco Desktop em um servidor é através de testes rigorosos de malha aberta focados no percentil 99.99.
O veredito metodológico
Continuar utilizando scripts padrão de Fio em malha fechada para validar infraestrutura de armazenamento é um risco inaceitável para qualquer operação de TI séria. A omissão coordenada não é apenas um preciosismo acadêmico, é uma falha matemática que invalida completamente a correlação entre o seu benchmark e o desempenho da sua aplicação em produção.
Revise seus procedimentos de homologação de hardware hoje. Descarte relatórios que citam apenas latência média e exija testes de malha aberta com análise de percentis profundos. O verdadeiro teste de um storage não é o quão rápido ele é quando tudo está bem, mas o quão previsível ele se mantém quando o caos do tráfego real atinge seus controladores.
Referências & Leitura Complementar
SNIA (Storage Networking Industry Association): Solid State Storage Performance Test Specification (PTS) Enterprise v2.0. Documentação oficial sobre metodologias de pré-condicionamento e testes de estado estacionário (steady state) em SSDs.
Gil Tene: "How NOT to Measure Latency". Apresentação fundamental que cunhou o termo Omissão Coordenada e detalhou as falhas matemáticas em benchmarks de malha fechada.
Jens Axboe: Documentação oficial do Fio (Flexible I/O Tester), especificamente as seções detalhando os parâmetros
rate_processe controle de submissão de I/O.
O que é omissão coordenada em testes de storage?
É um erro metodológico grave onde o gerador de carga (como o Fio em sua configuração padrão) pausa o envio de novas requisições enquanto aguarda uma resposta lenta do disco. Isso esconde o enfileiramento real que ocorreria no sistema operacional e mascara picos de latência que inevitavelmente atingiriam um ambiente de produção.Como evitar a omissão coordenada usando o Fio?
A solução definitiva é utilizar testes de malha aberta (open-loop). No Fio, você alcança isso configurando parâmetros de taxa fixa, como o `rate_iops`, combinados com `rate_process=poisson`. Essa configuração garante que as requisições cheguem ao disco de forma contínua e caótica, independentemente da velocidade de resposta anterior do hardware.Por que a latência de cauda (tail latency) é mais importante que a latência média em NVMe?
A latência média é uma métrica falha porque dilui anomalias matemáticas severas. Em ambientes corporativos e datacenters, a latência de cauda (medida pelos percentis 99 ou 99.99) revela os engasgos reais do hardware. Pausas para garbage collection no SSD ou saturação do controlador causam travamentos em bancos de dados de alta transação, e apenas a latência de cauda consegue expor esses eventos.
Dr. Elena Kovic
Metodologista de Benchmark
"Desmonto o marketing com análise estatística rigorosa. Meus benchmarks isolam cada variável para revelar a performance crua e sem filtros do hardware corporativo."