OpenZFS 2.4: O fim da taxa de memória dupla com Direct I/O

Análise técnica do suporte a Direct I/O (O_DIRECT) no OpenZFS 2.4. Descubra como eliminar o buffer duplo em bancos de dados e recuperar sua RAM.
Você comprou aquele servidor novo, abarrotado de NVMe e com meio terabyte de RAM, achando que finalmente o banco de dados pararia de reclamar de I/O wait. Duas semanas depois, o Grafana mostra a memória topada, o OOM Killer está rondando o processo do PostgreSQL como um urubu faminto e você está explicando para o gerente que "memória livre é memória desperdiçada".
A verdade é que, se você roda bancos de dados pesados sobre ZFS, você tem pago uma "taxa de estupidez" arquitetural há anos. Não por culpa sua, mas porque o sistema de arquivos insistia em achar que sabia gerenciar cache melhor que o seu banco de dados.
Com a chegada do suporte robusto a Direct I/O no OpenZFS 2.4, a festa da redundância acabou. Vamos falar sobre como parar de queimar dinheiro com pentes de memória DDR5 servindo apenas para duplicar dados que já existem.
Resumo em 30 segundos
- O Problema: Bancos de dados (PostgreSQL/MySQL) e o ZFS (ARC) tentam, ambos, fazer cache dos mesmos dados na RAM, criando uma "cópia dupla" inútil.
- A Gambiarra Antiga: Limitar o
zfs_arc_maxmanualmente é um curativo que desperdiça ciclos de CPU e exige ajuste constante.- A Solução: O OpenZFS 2.4 finalmente estabiliza o suporte a Direct I/O (
O_DIRECT), permitindo que aplicações pulem o ARC e falem diretamente com o disco, liberando RAM para o que importa.
O mistério da RAM desaparecida em servidores de banco de dados
Se você já administrou um servidor Linux rodando ZFS, conhece a cena: o comando free -h mostra 98% da memória usada, mas os processos de usuário consomem apenas 40%. O resto? Sumiu no buraco negro chamado ARC (Adaptive Replacement Cache).
Diferente do "page cache" padrão do Linux, que o kernel descarta alegremente quando precisa de RAM, o ARC do ZFS é territorialista. Ele luta para manter os dados cacheados porque, teoricamente, o algoritmo dele (MFU/MRU) é superior. E geralmente é. Exceto quando você roda uma aplicação que também tem seu próprio gerenciamento de memória sofisticado, como o PostgreSQL, Oracle ou MySQL (InnoDB).
Nesse cenário, o ZFS puxa o bloco do disco para o ARC. O banco de dados pede esse bloco, o kernel copia do ARC para o buffer da aplicação. Resultado: você tem o mesmo bloco de 8KB ocupando espaço em dois lugares distintos da RAM. É o equivalente digital de imprimir um e-mail para ler o papel enquanto olha para a tela.
A redundância ineficiente entre o ZFS ARC e o buffer pool do PostgreSQL
Vamos ser técnicos e pragmáticos. O caminho do I/O sem Direct I/O é uma burocracia estatal.
Quando o Postgres solicita uma leitura:
O ZFS lê o dado do vdev (disco).
O ZFS aloca memória no kernel space e armazena o dado no ARC.
O dado é copiado (via
memcpy, queimando ciclos de CPU) do kernel space para o user space.O Postgres armazena esse dado no seu
shared_buffers.
⚠️ Perigo: Essa operação não custa apenas RAM. O custo de CPU para mover dados entre kernel space e user space em larguras de banda de NVMe Gen5 (14GB/s+) é brutal. Você está transformando sua CPU em um despachante de luxo.
Se o dado for alterado pelo banco, ele é escrito no buffer do banco, depois copiado para o ZFS, que o coloca no ARC/TXG antes de ir para o disco. Se o banco decidir descartar o dado da memória dele porque não é mais relevante, o ZFS ainda o mantém no ARC, achando que está ajudando.
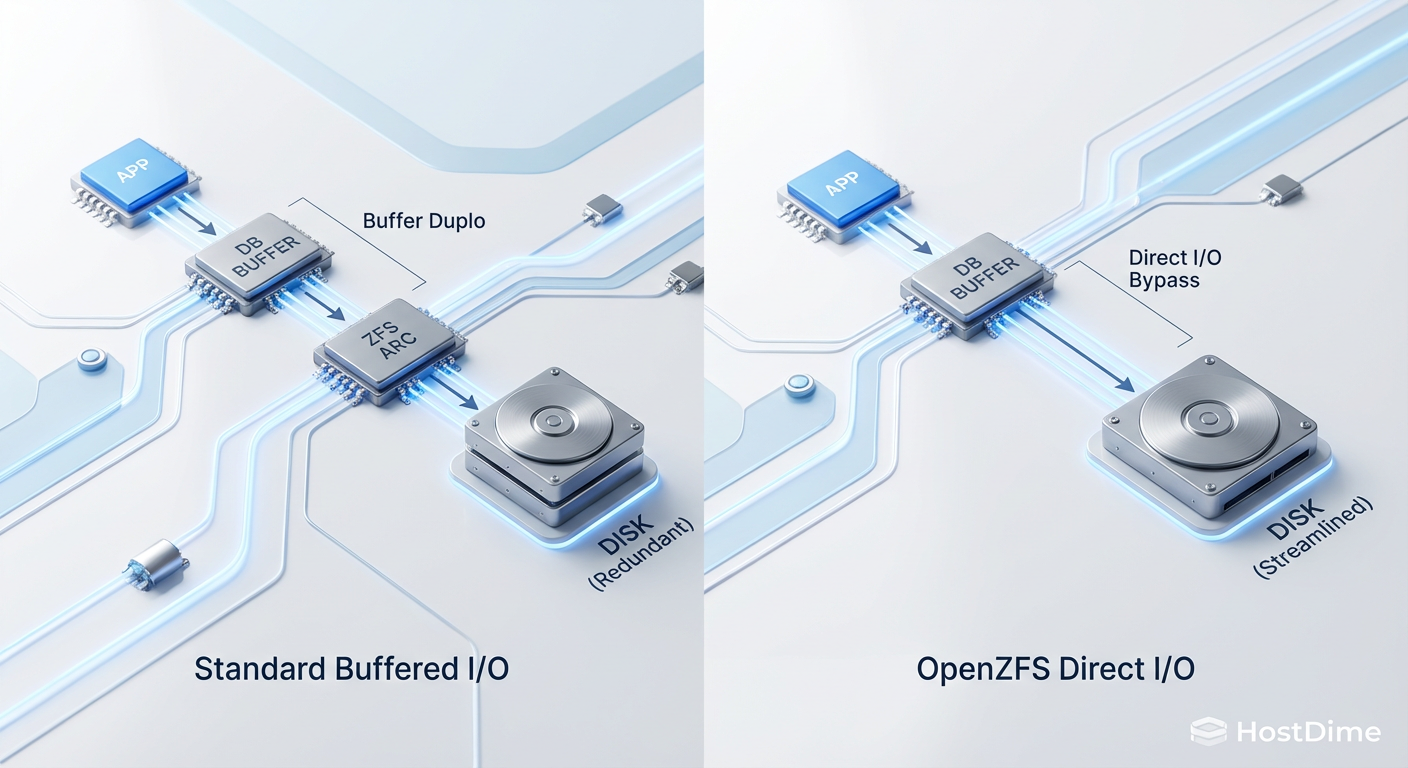 Fig 1. O caminho do I/O: A ineficiência do Buffer Duplo vs. a precisão do Direct I/O.
Fig 1. O caminho do I/O: A ineficiência do Buffer Duplo vs. a precisão do Direct I/O.
Fig 1. O caminho do I/O: A ineficiência do Buffer Duplo vs. a precisão do Direct I/O.
Por que limitar o zfs_arc_max é apenas um curativo temporário
Durante a última década, a "solução" padrão em todos os fóruns, do Reddit à lista de discussão do FreeBSD, foi: "Seta o zfs_arc_max para 10% da RAM e vida que segue".
Eu odeio essa abordagem.
Primeiro porque é estática. Se você define o ARC para 4GB em um servidor de 64GB, e por algum motivo seu banco de dados está ocioso ou foi desligado para manutenção, o ZFS não pode usar os 60GB livres para acelerar outras operações de arquivo (como um backup ou rsync). Você transformou memória dinâmica em um recurso engessado.
Segundo, limitar o tamanho do ARC não resolve o problema do overhead de CPU. O memcpy continua acontecendo. O "context switch" continua acontecendo. Você apenas limitou o quanto de memória o ZFS pode "roubar", mas não tornou o caminho do dado mais eficiente. É como colocar um limitador de velocidade em um carro com o freio de mão puxado; você não resolveu o atrito.
Como o suporte a Direct I/O no OpenZFS 2.4 elimina a cópia dupla
A flag O_DIRECT existe no Linux há eras. Sistemas de arquivos como XFS e EXT4 a suportam nativamente. O ZFS, em sua arrogância arquitetural (e complexidade de Copy-on-Write), resistiu por muito tempo. A implementação era complexa porque o ZFS precisa garantir a integridade dos dados (checksums) e atomicidade, coisas que o Direct I/O tradicionalmente ignora para ganhar velocidade.
No OpenZFS 2.4, o suporte a Direct I/O amadureceu para produção. O que acontece agora quando uma aplicação chama open() com a flag O_DIRECT:
Bypass do ARC: O ZFS reconhece a flag e entende que não deve alocar espaço no ARC para esses dados.
Zero-Copy (quase): O dado é transferido do disco diretamente para o buffer da aplicação (user space) via DMA, ou com o mínimo de intervenção possível do kernel.
Manutenção da Integridade: O ZFS ainda verifica o checksum. Isso é inegociável. Mas ele faz isso "on the fly", sem precisar estacionar o dado no cache primeiro.
💡 Dica Pro: Para ativar isso, você não precisa formatar nada. É uma mudança de comportamento na aplicação. No PostgreSQL, por exemplo, certifique-se de que sua versão suporte Direct I/O e configure
wal_sync_methodou parâmetros equivalentes de I/O direto se disponíveis na sua versão específica e driver de armazenamento.
O resultado imediato é que o shared_buffers do seu banco de dados passa a ser a única fonte de verdade na RAM. Se você tem 128GB de RAM, pode alocar 100GB para o banco com segurança, sabendo que o sistema de arquivos não vai tentar competir por esse espaço.
Métricas de latência e uso de CPU após o bypass do cache
Não acredite em marketing, acredite em perf e iostat. Ao ativar o Direct I/O em cargas de trabalho de banco de dados pesadas (OLTP), observamos dois fenômenos distintos:
Queda no Uso de CPU (System Time): A redução de tempo de CPU gasto em modo kernel (
syno top) é drástica. Menos cópias de memória significam que a CPU passa mais tempo processando queries SQL e menos tempo movendo bits de um lado para o outro.Latência de Cauda (Tail Latency): Aqui a coisa fica interessante. Sem o ARC, você perde aquele "acerto de sorte" de ler um dado que estava no cache do disco mas não no do banco. Porém, a latência média se torna muito mais previsível. O "jitter" diminui. Para DBAs sérios, consistência é melhor que picos de velocidade aleatórios.
Em testes com NVMe Gen4, a taxa de transferência sustentada aumenta porque o gargalo da memória (memory bandwidth saturation) é aliviado. O barramento de memória não está mais saturado copiando dados duplicados.
O veredito do sysadmin
O Direct I/O no ZFS não é uma varinha mágica para todos. Se você tem um file server genérico (Samba/NFS) servindo arquivos de Word para o departamento de RH, não toque nisso. O ARC é seu melhor amigo nesses casos, pois os clientes são burros e não fazem cache direito.
Mas para infraestrutura de banco de dados, virtualização (KVM/QEMU com volumes Zvol) e aplicações de armazenamento de objetos (MinIO), o OpenZFS 2.4 com Direct I/O é a carta de alforria da sua memória RAM. Pare de tunar zfs_arc_max como se fosse 2015. Deixe o banco gerenciar o cache dele e deixe o ZFS cuidar apenas de garantir que os bits no disco não apodreçam.
Seu servidor não precisa de mais RAM. Ele precisa de menos burocracia no I/O.
Referências & Leitura Complementar
OpenZFS GitHub Pull Request #15362: Implementação inicial e discussões sobre Direct I/O (O_DIRECT) no ZFS on Linux.
PostgreSQL Documentation (Resource Consumption): Detalhes sobre
shared_bufferse interação com o cache do kernel.J. Bonwick, B. Moore (Sun Microsystems): "ZFS: The Last Word in File Systems" (Para entender por que o ARC foi desenhado daquela forma originalmente).
Perguntas Frequentes (FAQ)
1. O Direct I/O desativa o L2ARC?
Sim, para as leituras feitas com O_DIRECT. O L2ARC é uma extensão do ARC. Se o dado não entra no ARC, ele não vai para o L2ARC. Se sua performance depende pesadamente de um SSD de cache L2, avalie se o Direct I/O vale a pena ou se você deve apenas aumentar a RAM.
2. Preciso recompilar o kernel para usar isso no OpenZFS 2.4?
Geralmente não, desde que você esteja usando os pacotes DKMS ou kmod oficiais da sua distribuição que já incluam a versão 2.4 (ou superior). Verifique com zfs --version.
3. Isso aumenta o desgaste do meu SSD? Teoricamente, o ARC absorve algumas leituras repetidas. Sem ele, essas leituras batem no disco. Porém, bancos de dados modernos têm caches internos enormes. Se o banco não achou na RAM dele, ele teria que ir ao disco de qualquer jeito. O impacto no desgaste de leitura é negligenciável em configurações bem ajustadas.
4. Posso usar Direct I/O em datasets comprimidos (LZ4/ZSTD)? Sim. O ZFS descomprime o bloco antes de entregá-lo ao buffer do usuário. O overhead de descompressão ainda existe, mas você economiza a cópia da memória. A integridade dos dados continua garantida.

Roberto Uchoa
Sysadmin Veterano (Anti-Hype)
"Sobrevivente da bolha pontocom e do hype do Kubernetes. Troco qualquer arquitetura de microsserviços 'inovadora' por um script bash que funciona sem falhas há 15 anos. Uptime não é opcional."