OpenZFS dRAID: A arquitetura de resiliência para a era dos discos de 24TB

Adeus aos rebuilds de 6 dias. Descubra como o dRAID elimina o gargalo do resilver em arrays de alta capacidade, reduzindo o TCO e o risco de perda de dados.
A densidade de armazenamento atingiu um ponto de inflexão crítico. Com a padronização dos discos rígidos de 24TB e a chegada iminente das unidades de 30TB+ no mercado enterprise, a arquitetura tradicional de redundância baseada em RAID (e por extensão, o RAIDZ do ZFS) deixou de ser apenas "lenta". Ela se tornou um risco operacional inaceitável.
Quando projetamos sistemas de armazenamento para alta disponibilidade, não olhamos apenas para a capacidade bruta. Olhamos para o tempo de recuperação. A matemática é implacável: a capacidade dos discos cresceu exponencialmente, mas a velocidade mecânica dos atuadores (IOPS) permaneceu praticamente estagnada. O resultado é uma janela de vulnerabilidade durante a reconstrução (resilver) que não se mede mais em horas, mas em dias ou semanas. O OpenZFS dRAID (Distributed RAID) não é apenas uma "nova feature"; é a resposta arquitetural necessária para desacoplar a segurança dos dados das limitações físicas de um único eixo mecânico.
Resumo em 30 segundos
- O problema: Reconstruir um disco de 24TB em RAIDZ tradicional é limitado pela velocidade de escrita de um único drive substituto, criando uma janela de risco de dias.
- A solução: O dRAID distribui a "reserva" (hot spare) e a paridade por todos os discos do array, permitindo que todos participem da reconstrução simultaneamente.
- O ganho: O tempo de resilver é reduzido drasticamente (frequentemente em 10x ou mais), minimizando a probabilidade de uma segunda falha catastrófica durante a recuperação.
O risco matemático da janela de vulnerabilidade estendida
Em arquiteturas distribuídas, a durabilidade dos dados é uma função do tempo. Quanto mais tempo seus dados permanecem em estado degradado (sem paridade completa), maior a probabilidade estatística de uma perda de dados irrevogável (Mean Time to Data Loss - MTTDL).
O cenário clássico de pesadelo para qualquer engenheiro de armazenamento é a falha secundária durante o resilver. Ao substituir um disco falho em um vdev RAIDZ2, você submete os discos restantes — que já possuem a mesma idade e desgaste do disco que morreu — a uma carga de leitura intensa e contínua.
⚠️ Perigo: Em um array de discos de 24TB, um resilver tradicional pode exigir a leitura e escrita de dezenas de terabytes. Se a taxa de erro de leitura não recuperável (URE) do disco for de 1 setor a cada $10^{15}$ bits lidos, a probabilidade matemática de encontrar um erro durante a reconstrução de um array grande aproxima-se perigosamente de 100%.
Se o processo levar 96 horas, você está jogando dados com a integridade do seu pool por quatro dias inteiros. O dRAID ataca essa variável "tempo" na equação de risco. Ao reduzir o tempo de reconstrução, reduzimos linearmente a janela de exposição a erros de bit e falhas de hardware adicionais.
A limitação física de IOPS no resilver tradicional
Para entender por que o dRAID é necessário, precisamos dissecar a falha do modelo atual. No RAIDZ (ou RAID 5/6 tradicional), quando um disco falha e um hot spare entra em ação, a velocidade de reconstrução é ditada pelo elo mais fraco.
Geralmente, esse elo é a velocidade de escrita sequencial do disco novo. Um HDD moderno de 24TB, mesmo com hélio e alta densidade de área, dificilmente sustenta mais que 250-280 MB/s de escrita contínua. E isso é no melhor cenário (início do prato). Nas trilhas internas, isso cai pela metade.
 Fig. 1: O 'Efeito Funil' do RAIDZ versus a distribuição de carga do dRAID.
Fig. 1: O 'Efeito Funil' do RAIDZ versus a distribuição de carga do dRAID.
O diagrama acima ilustra o que chamamos de "Efeito Funil". Você pode ter 50 discos no seu chassi, mas durante um resilver tradicional, 49 deles estão lendo confortavelmente enquanto apenas um está escrevendo freneticamente. O desempenho agregado do seu storage de meio milhão de reais é desperdiçado porque a arquitetura de software está acoplada à topologia física de um único drive de destino.
Desacoplando a reserva de espaço da topologia física
A genialidade do dRAID reside na abstração. Tradicionalmente, um hot spare é um disco físico, ocioso, consumindo energia e ocupando um slot no chassi, esperando algo quebrar. É um desperdício de capital (CAPEX) e operacional (OPEX).
No dRAID, não existe "disco de spare". Existe "capacidade de spare".
Ao configurar um pool dRAID, você define uma capacidade virtual de reserva distribuída (distributed spare). O ZFS reserva blocos lógicos equivalentes a um ou mais discos, mas espalha esses blocos por todos os drives do vdev.
O mecanismo de reconstrução: Quando um disco falha, o dRAID não precisa esperar que você espete um disco novo para começar a recuperar a redundância. Ele imediatamente começa a reconstruir os dados perdidos usando a capacidade de reserva distribuída nos discos sobreviventes.
Como todos os discos do array possuem espaço livre reservado e todos possuem dados, todos os discos escrevem e leem simultaneamente.
💡 Dica Pro: Em um vdev dRAID com 90 discos, a velocidade de reconstrução não é 1x a velocidade de um disco, mas sim um fator multiplicado pela largura do array. Testes em ambientes de produção mostram reconstruções de múltiplos terabytes ocorrendo em minutos ou poucas horas, não dias.
A falácia de resolver durabilidade apenas com paridade extra
Uma resposta comum de administradores juniores ao problema dos discos grandes é: "Basta usar RAIDZ3 (paridade tripla)". Embora o RAIDZ3 seja excelente e deva ser usado, ele resolve apenas a tolerância a falhas simultâneas, não a velocidade de retorno ao estado saudável.
O RAIDZ3 protege você de perder dados se três discos falharem. Mas se a reconstrução do primeiro disco demorar uma semana, você passará essa semana inteira com a redundância degradada. Se ocorrerem UREs ou vibração induzida no chassi, a degradação de performance será severa.
O dRAID muda a conversa de "quantos discos posso perder?" para "quão rápido posso voltar à redundância total?".
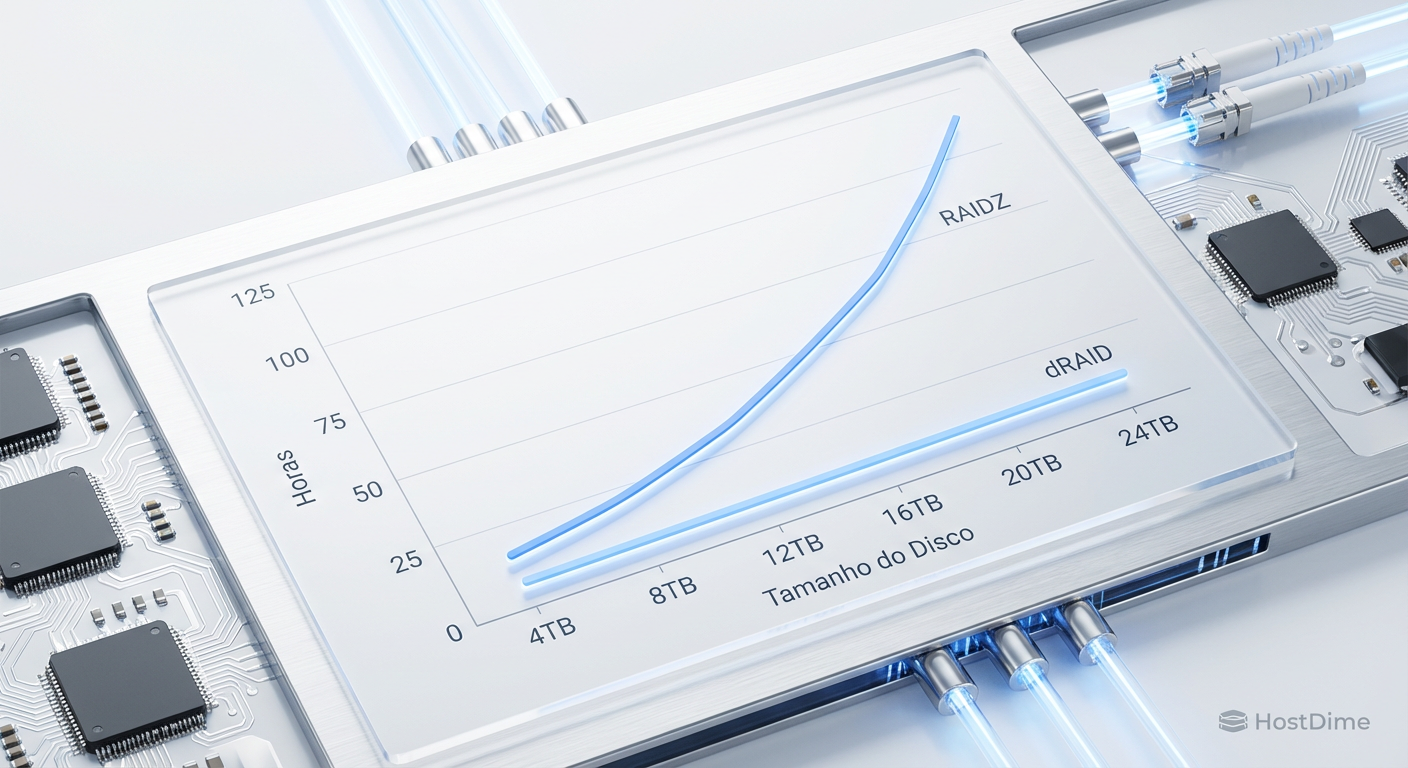 Fig. 2: Projeção de tempo de reconstrução baseada na saturação de IOPS de um único disco.
Fig. 2: Projeção de tempo de reconstrução baseada na saturação de IOPS de um único disco.
A projeção acima demonstra a diferença brutal no TCO operacional. A linha vermelha (RAIDZ) mostra um risco linear crescente. A linha azul (dRAID) mostra um tempo de recuperação quase constante, independentemente do tamanho do disco, desde que a largura do vdev (número de discos) escale proporcionalmente.
Validando o impacto no TCO e planejamento de capacidade
A adoção do dRAID exige uma mudança de mentalidade no planejamento de infraestrutura. Não se trata apenas de habilitar uma flag no momento da criação do pool zpool create. Existem trade-offs reais que impactam o Custo Total de Propriedade.
Layout Estático: Ao contrário de vdevs espelhados (mirrors) que são flexíveis, o dRAID possui uma geometria interna complexa. Uma vez criado, o layout (tamanho da tira, número de grupos de redundância) é fixo. Você não expande um vdev dRAID facilmente; você adiciona novos vdevs dRAID.
Custo de CPU: O cálculo de paridade declustered e o mapeamento lógico exigem mais ciclos de CPU do que o RAIDZ linear. Para workloads de arquivamento (Cold Storage), isso é irrelevante. Para workloads de alta performance, o overhead deve ser validado.
Eficiência de Armazenamento: O dRAID pode ter uma eficiência de armazenamento ligeiramente menor devido aos requisitos de preenchimento (padding) e alinhamento, dependendo do
ashifte do tamanho do registro (recordsize) escolhidos.
No entanto, o TCO brilha na densidade. Com dRAID, você pode preencher um chassi de 60 ou 90 baias (JBODs de alta densidade) como um único vdev lógico maciço, mantendo tempos de reconstrução extremamente baixos. Tentar fazer isso com múltiplos vdevs RAIDZ2 pequenos resultaria em fragmentação de IOPS e perda de capacidade em paridade excessiva.
O veredito arquitetural
A transição para dRAID não é uma questão de "se", mas de "quando" para qualquer organização que planeje utilizar discos acima de 18TB-20TB. A física dos HDDs mecânicos não mudará; a velocidade de rotação e a densidade de atuação atingiram seus limites práticos.
Se sua infraestrutura depende de arrays grandes de HDDs para backup, object storage ou data lakes, o modelo RAIDZ tradicional tornou-se um passivo técnico. O risco de uma segunda falha durante uma janela de reconstrução de 100 horas é um jogo de azar que nenhuma empresa séria deveria aceitar.
Minha recomendação é clara: para novos deployments de alta densidade (especialmente aqueles com 24TB+ drives e chassis com mais de 20 slots), o dRAID deve ser o padrão. Para home labs e arrays pequenos (menos de 10 discos), o RAIDZ2 continua sendo superior pela simplicidade e menor overhead.
O armazenamento é a fundação da confiabilidade. Construa-o para falhar, mas projete-o para se recuperar antes que alguém perceba.
Referências & Leitura Complementar
OpenZFS dRAID Feature Flag: Documentação oficial do OpenZFS sobre a implementação
feature@draid.M. Holland et al., "Declustered Parity for Data Reliability": O paper fundamental que descreve a matemática por trás da distribuição de paridade e redução do tempo de reconstrução.
Seagate & Western Digital Datasheets (2024-2025): Especificações de taxa de transferência sustentada (Sustained Transfer Rate) para discos Exos e Ultrastar de 24TB+, validando o gargalo físico de ~280MB/s.
Perguntas Frequentes (FAQ)
1. O dRAID substitui totalmente o RAIDZ? Não. O dRAID brilha em arrays com grande número de discos (geralmente 20+). Para arrays menores, a complexidade e o overhead do dRAID não justificam os ganhos, e o RAIDZ2 ou Mirrors continuam sendo mais eficientes.
2. Posso converter um pool RAIDZ existente para dRAID? Não. O dRAID é uma topologia de vdev fundamentalmente diferente. Requer a destruição do pool e recriação do zero (backup e restore).
3. O que acontece se eu não tiver um disco físico para substituir o falho imediatamente? Essa é a vantagem do dRAID. Se você configurou "capacidade de spare virtual", o sistema reconstrói a redundância usando o espaço livre nos discos restantes. O array volta ao estado "Saudável" (embora com menos espaço livre) antes mesmo de você trocar o disco físico.
4. O dRAID consome mais RAM que o RAIDZ? Sim, marginalmente. A tabela de mapeamento para distribuir os blocos requer mais memória e os cálculos de reconstrução distribuída geram mais metadados. Em servidores modernos com ZFS ARC bem dimensionado, isso raramente é um problema.

Otávio Henriques
Arquiteto de Soluções Enterprise
"Com duas décadas desenhando infraestruturas críticas, olho além do hype. Foco em TCO, resiliência e trade-offs, pois na arquitetura corporativa a resposta correta quase sempre é 'depende'."