OpenZFS dRAID: a matemática da reconstrução distribuída em arrays de alta densidade

Descubra como o dRAID do OpenZFS revoluciona o tempo de resilver em grandes storages, distribuindo a paridade e eliminando o gargalo do hot spare dedicado.
Se você gerencia armazenamento há tempo suficiente, conhece aquele frio na espinha que ocorre quando um disco falha em um array RAIDZ. Não é o medo da perda de dados imediata, afinal, temos paridade. O medo real é o tempo de reconstrução (resilver).
Com discos rígidos modernos ultrapassando a barreira dos 20TB e 24TB, a matemática do RAID tradicional começou a jogar contra nós. O tempo necessário para ler todos os dados restantes e escrever em um único disco de substituição (hot spare) tornou-se perigosamente longo. Estamos falando de dias, às vezes semanas, onde seu array está vulnerável a uma falha secundária que poderia ser catastrófica.
É aqui que o OpenZFS dRAID (Distributed RAID) entra. Não é apenas uma nova sigla para vender hardware; é uma reengenharia fundamental de como a paridade e os discos de reserva são gerenciados para resolver o gargalo físico de IOPS durante a recuperação.
Resumo em 30 segundos
- O Problema: O RAIDZ tradicional limita a velocidade de reconstrução à velocidade de escrita de um único disco novo (o gargalo do hot spare).
- A Solução: O dRAID distribui a capacidade de reserva (spare) por todos os discos do array, permitindo que todos os drives participem da leitura e da escrita durante a reconstrução.
- O Alvo: Ideal para arrays de alta densidade (20, 60, 90+ discos). Para setups domésticos pequenos, a complexidade geralmente não compensa.
O gargalo físico do RAIDZ tradicional
Para entender o dRAID, precisamos dissecar a falha do modelo atual. Imagine um vdev RAIDZ2 com 10 discos + 1 Hot Spare dedicado. Quando um disco morre, o ZFS precisa ler os dados dos 9 discos sobreviventes, calcular a paridade e escrever o resultado no Hot Spare.
O problema é puramente físico: a largura de banda de leitura combinada dos 9 discos é massiva, mas a largura de banda de escrita do Hot Spare é fixa. Um HDD moderno escreve a cerca de 250-280 MB/s (no melhor cenário sequencial). Não importa quão rápido seja seu processador ou quão otimizado seja o ZFS, o processo de resilver nunca será mais rápido que aquele único disco girando e gravando.
Além disso, durante esse processo, o disco novo é martelado com escritas, enquanto os discos antigos sofrem carga de leitura intensa. O desempenho do pool cai drasticamente, afetando qualquer VM ou banco de dados que esteja rodando ali.
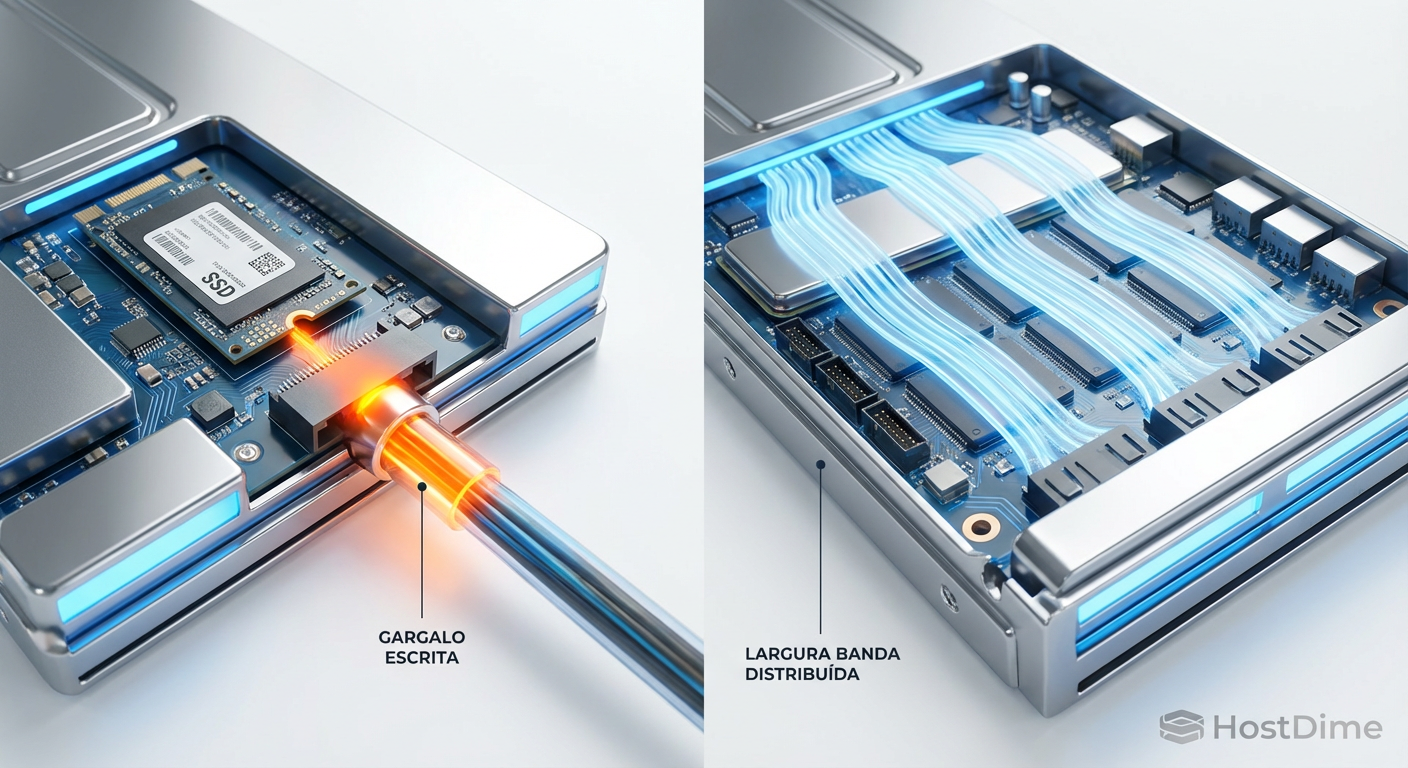 Figura: Comparação visual do gargalo de escrita em um Hot Spare dedicado versus a largura de banda distribuída no dRAID.
Figura: Comparação visual do gargalo de escrita em um Hot Spare dedicado versus a largura de banda distribuída no dRAID.
A arquitetura de paridade declustered (dRAID)
O dRAID implementa o conceito de declustered parity. Em vez de ter um disco físico parado esperando para ser usado (o hot spare clássico), o dRAID pega a capacidade desse disco e a "fatia", distribuindo esses blocos vazios por todos os discos do grupo.
No dRAID, não existe "disco de dados", "disco de paridade" ou "disco de spare" dedicados. Cada disco físico no array contém uma mistura de:
Blocos de dados.
Blocos de paridade.
Blocos de espaço de reserva (distributed spare).
A mágica da reconstrução distribuída
Quando um disco falha em um vdev dRAID, o sistema não precisa escrever tudo em um único lugar. Como o "espaço de reserva" está espalhado por todos os discos sobreviventes, todos os discos escrevem.
Se você tem um array de 60 discos e um falha, os 59 discos restantes leem os dados necessários E escrevem os dados reconstruídos nos seus próprios espaços de reserva internos.
A matemática muda drasticamente:
RAIDZ: Velocidade de Reconstrução = Velocidade de Escrita de 1 Disco.
dRAID: Velocidade de Reconstrução = (Velocidade de Escrita de 1 Disco) * (Número de Discos - 1).
Em testes práticos com arrays grandes, isso reduz o tempo de resilver de dias para horas.
 Figura: Visualização lógica de como o espaço de reserva (spare) é distribuído em blocos por todos os discos no dRAID, em vez de residir em um único dispositivo físico.
Figura: Visualização lógica de como o espaço de reserva (spare) é distribuído em blocos por todos os discos no dRAID, em vez de residir em um único dispositivo físico.
Comparativo: RAIDZ vs dRAID
Para o operador de homelab ou sysadmin, a escolha entre os dois depende do tamanho da infraestrutura. Veja as diferenças críticas:
| Característica | RAIDZ (Tradicional) | dRAID (OpenZFS) |
|---|---|---|
| Conceito de Spare | Disco físico dedicado (inativo até a falha). | Capacidade virtual distribuída (ativa). |
| Velocidade de Resilver | Limitada por 1 disco (o alvo). | Limitada pela soma da banda de todos os discos. |
| Impacto na Performance | Alto impacto durante a reconstrução. | Impacto diluído, o array mantém melhor performance. |
| Flexibilidade | Moderada. | Baixa (estrutura fixa na criação). |
| Complexidade de CPU | Baixa. | Média (cálculo de mapas de permutação). |
| Cenário Ideal | Arrays pequenos a médios (< 12 discos). | Alta densidade (20, 50, 100+ discos). |
💡 Dica Pro: O dRAID utiliza mapas de permutação pré-calculados para saber onde colocar os dados. Isso exige um pouco mais de CPU e RAM do que o RAIDZ tradicional, mas em hardware moderno (mesmo usado), isso raramente é o gargalo.
A anatomia de um comando dRAID
A sintaxe do ZFS para criar um dRAID pode assustar no início, pois introduz novos argumentos: data, children e spares.
Um comando típico se parece com isso:
zpool create tank draid2:4d:1s:11c /dev/sd[a-k]
Vamos decodificar a nomenclatura draid2:4d:1s:11c:
draid2: Nível de paridade (equivalente ao RAIDZ2, suporta falha de 2 discos).
4d: Número de discos de dados por "grupo de redundância" (data drives).
1s: Número de "spares virtuais" distribuídos. O sistema reserva a capacidade equivalente a 1 disco, espalhada por todos.
11c: Número de "children" (filhos/discos) totais no vdev.
Aqui reside uma das maiores armadilhas para quem gosta de expandir aos poucos. O layout interno do dRAID é estático. O tamanho dos grupos de redundância é fixo. Diferente de adicionar um mirror a um pool existente, mexer na geometria interna de um vdev dRAID é, atualmente, impossível sem destruir e recriar.
 Figura: O mapeamento lógico: Grupos de Redundância sendo distribuídos fisicamente através de um mapa de permutação sobre os discos reais.
Figura: O mapeamento lógico: Grupos de Redundância sendo distribuídos fisicamente através de um mapa de permutação sobre os discos reais.
O trade-off da imutabilidade e o "Resilver Sequencial"
O OpenZFS introduziu o recurso de resilver sequencial como padrão para dRAID (e mais tarde portado para RAIDZ). Isso significa que, em vez de buscar blocos aleatoriamente pelo disco para verificar checksums (o que matava a performance de HDDs mecânicos), o dRAID reconstrói o mapa de alocação e lê/escreve da forma mais sequencial possível.
No entanto, a rigidez é o preço. Em um ambiente de homelab, onde compramos discos em promoções aleatórias (shucking de drives externos, por exemplo) e expandimos o array de 4 para 6, depois para 8 discos, o dRAID é um inimigo. Ele exige planejamento de capacidade upfront. Você precisa comprar todos os discos de uma vez para justificar o uso.
Quando o dRAID não faz sentido
Se você tem um servidor com 8 baias ou menos, esqueça o dRAID.
Perda de Capacidade: A sobrecarga de paridade e spare distribuído em poucos discos consome uma porcentagem desproporcional de armazenamento útil.
Ganhos Marginais: Com 6 discos, distribuir a escrita de reconstrução por 5 discos em vez de 1 é melhor, mas não muda o jogo como faria com 50 discos.
Complexidade: A gestão e o troubleshooting de um mapa dRAID são mais complexos que um simples
zpool statusde um RAIDZ2.
 Figura: Gráfico de eficiência: O ponto de inflexão onde o dRAID supera o RAIDZ tradicional ocorre geralmente acima de 12-15 discos.
Figura: Gráfico de eficiência: O ponto de inflexão onde o dRAID supera o RAIDZ tradicional ocorre geralmente acima de 12-15 discos.
Veredito do Operador
O dRAID não é uma "atualização" automática para o RAIDZ; é uma ferramenta especializada para um problema de escala.
Se você está construindo um JBOD de alta densidade (pense em chassis de 45 ou 60 baias como os da 45Drives ou Supermicro top-load) e planeja preenchê-lo com discos de 18TB+, o dRAID é obrigatório. O risco de uma segunda falha durante um resilver de 4 dias em RAIDZ tradicional é estatisticamente inaceitável para dados críticos. O dRAID reduz essa janela de vulnerabilidade para horas, usando a força bruta da largura de banda agregada.
Para o entusiasta com um gabinete torre e 6 discos: mantenha o RAIDZ2. A simplicidade e a eficiência de espaço ainda vencem nessa escala. O dRAID é a prova de que, no armazenamento, a força está nos números — mas apenas se você tiver números suficientes para jogar.
Referências & Leitura Complementar
OpenZFS Documentation: dRAID Feature Description
Paper Original (USENIX): "Declustered RAID: A New Look at an Old Technique" - Base teórica para implementações modernas.
Pull Request do Recurso: OpenZFS PR #10102 (Implementação técnica e discussão de código).
JEDEC/SNIA: Padrões de confiabilidade de HDD e taxas de erro de bit (UBER) que justificam a necessidade de reconstruções rápidas.
O que é dRAID no OpenZFS?
O dRAID (Distributed RAID) é um tipo de vdev que distribui tanto os dados e paridade quanto a capacidade de reserva (hot spares) por todos os discos do grupo. Diferente do RAID tradicional, onde um disco de reserva fica ocioso, no dRAID todos os discos são usados, permitindo reconstruções muito mais rápidas.Qual a diferença entre RAIDZ2 e dRAID2?
A principal diferença está na reconstrução. O RAIDZ2 limita a velocidade de reconstrução à velocidade de escrita de um único disco novo (o gargalo). O dRAID2 usa a largura de banda combinada de todos os discos restantes para reconstruir os dados no espaço distribuído, reduzindo drasticamente o tempo de vulnerabilidade do array.O dRAID vale a pena para arrays pequenos?
Geralmente não. O dRAID brilha em arrays com muitos discos (20, 60, 90+ drives) onde a largura de banda agregada é massiva. Para setups domésticos pequenos (menos de 10-12 discos), a complexidade de configuração e a perda de flexibilidade raramente compensam os ganhos de performance na reconstrução.Posso expandir um vdev dRAID depois de criado?
Não da maneira tradicional. A estrutura interna de um vdev dRAID (número de grupos de dados e paridade) é fixa após a criação. Embora o ZFS permita adicionar novos vdevs ao pool para crescer o espaço total, você não pode alterar facilmente a largura ou a contagem de spares dentro de um vdev dRAID já existente.
Marcos Lopes
Operador Open Source (Self-Hosted)
"Troco licenças proprietárias por soluções open source robustas, ciente de que a economia financeira custa suor na manutenção. Defensor da soberania de dados e da força da comunidade."